一. Solving the Problem of Overfitting
考虑从 $x \in \mathbb{R}$ 预测 y 的问题。下面最左边的图显示了将 $y =\theta_{0}+\theta_{1}x$ 拟合到数据集的结果。我们看到这些数据并不是直线的,所以这个数据并不是很好。
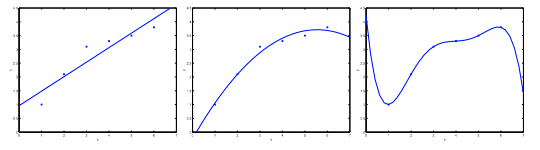
相反,如果我们添加了一个额外的特征 x2,并且拟合 $y =\theta_{0}+\theta_{1}x+\theta_{2}x^{2}$,那么我们获得的数据稍微更适合,如上图。
但是并不是添加的多项式越多越好。但是,添加太多特征也是一个危险:最右边的数字是拟合五阶多项式 $y =\theta_{0}+\theta_{1}x+\theta_{2}x^{2}+\theta_{3}x^{3}+\theta_{4}x^{4}+\theta_{5}x^{5} $ 的结果。我们看到即使拟合曲线完美地传递了数据,我们也不会认为这是一个很好的预测,上图最右边的图就是过度拟合的例子。
上图最右边的图也称有高方差。如果我们拟合一个高阶多项式,有过度的特征,并且这个假设函数能拟合几乎所有的数据,这就面临可能的函数太过于庞大,变量太多的问题。我们没有足够的数据去约束它,来获得一个好的假设函数,这就是过度拟合。
欠拟合或高偏倚是当我们的假设函数h的形式很难与数据的趋势作图时。它通常是由一个功能太简单或功能太少造成的。另一方面,过度拟合或高度方差是由适合现有数据的假设函数引起的,但不能很好地预测新数据。它通常是由一个复杂的函数造成的,它会产生大量与数据无关的不必要的曲线和角度。
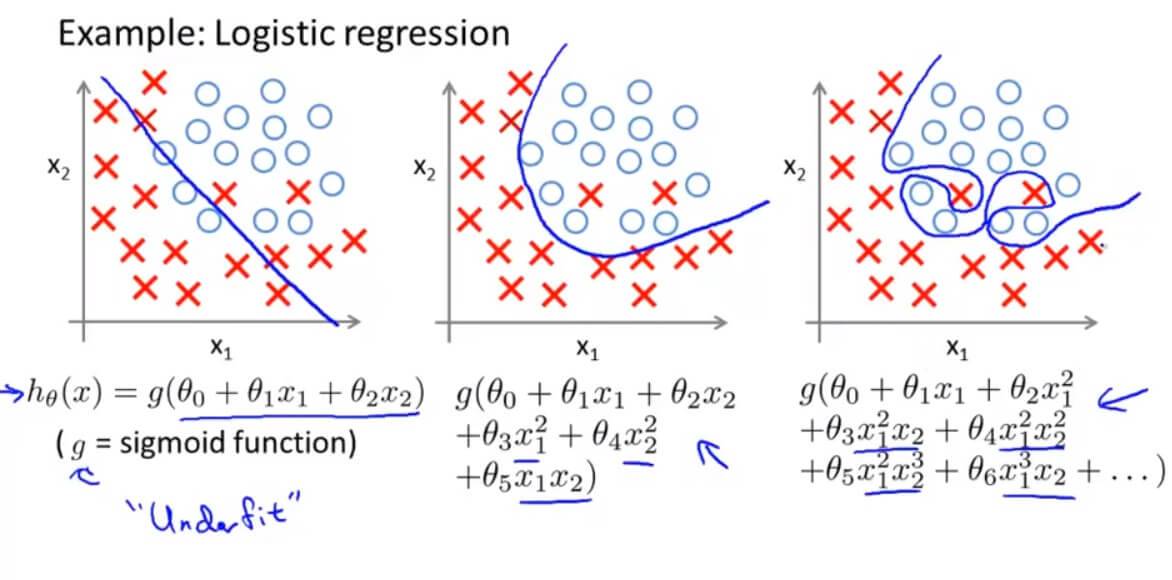
这个术语适用于线性和逻辑回归。解决过度配合问题有两个主要选项:
1. 减少特征的数量:
- 手动选择要保留的特征,哪些变量更为重要,哪些变量应该保留,哪些应该舍弃。
- 使用模型选择算法(稍后在课程中学习),算法会自动选择哪些特征变量保留,哪些舍弃。
缺点是舍弃了一些特征以后,也就舍弃了一些问题的关键信息。
2. 正则化
- 保留所有的特征,但减少参数 $\theta_{j}$ 的大小或者减少量级。
- 当有很多个特征的时候,并且每个特征都会对最终预测值产生影响,正则化可以保证运作良好。
正则化目的是尽量去简化这个假设模型。因为这些参数都接近0的时候,越简单的模型也被证明越不容易出现过拟合的问题。
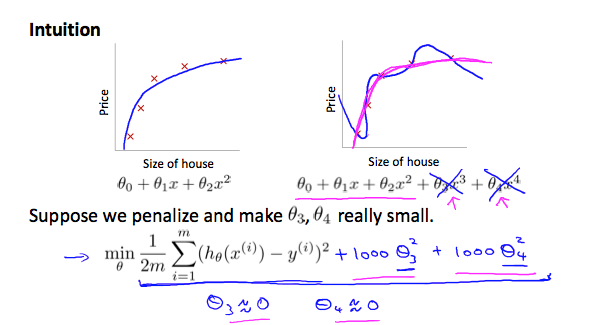
减少一些数量级的特征,加一些“惩罚”项(为了使代价函数最小,乘以 1000 就是惩罚)。
代价函数:
$$ \rm{CostFunction} = \rm{F}({\theta}) = \frac{1}{2m} \left [ \sum_{i = 1}^{m} (h_{\theta}(x^{(i)})-y^{(i)})^2 + \lambda \sum_{i = 1}^{m} \theta_{j}^{2} \right ]$$
$\lambda \sum_{i = 1}^{m} \theta_{j}^{2}$ 是正则化项,它缩小每个参数的值。 $\lambda$ 是正则化参数,$\lambda$ 控制两个不同目标之间的取舍,即更好的去拟合训练集的目标 和 将参数控制的更小的目标,从而保持假设模型的相对简单,避免出现过拟合的情况。
但是如果选择的 $\lambda $ 太大,可能会过多地消除特征,导致 $\theta$ 都约等于 0 了,最终预测函数变成了水平直线了。这就变成了欠拟合的例子了(偏见性太强,偏差过高)。
二. Regularized Linear Regression 线性回归正则化
1. Gradient Descent 线性回归梯度下降正则化
将上面的式子化简得:
在上面的式子中 $(1-\alpha \frac{\lambda}{m}) < 1$ 恒小于 1,约等于 1(0.999) 。于是梯度下降的过程就是每次更新都把参数乘以 0.999,缩小一点点,然后再向最小点的方向移动一下。
2. Normal Equation 线性回归正规方程正则化
之前推导过的正规方程结论:
正则化以后,上述式子变成了:
在之前的讨论中,有一个前提条件是 $X^{T}X$ 是非奇异(非退化)矩阵, 即 $ \left | X^{T}X \right | \neq 0 $
在上述正则化的式子里面,只要 $\lambda > 0$,就不存在不可逆的问题了。因为 $\left( X^{T}X +\lambda \begin{bmatrix}
0 & & & & \\
& 1 & & & \\
& & 1 & & \\
& & & \ddots & \\
& & & & 1
\end{bmatrix} \right)$ 这一项一定是可逆的,因为它一定不是奇异矩阵。所以正则化还能解决不可逆的情况。
三. Regularized Logistic Regression 逻辑回归正则化
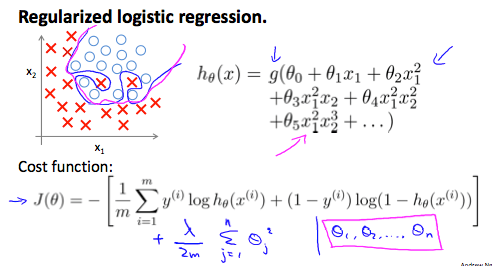
之前讨论过的代价函数是:
正则化以后:
1. Gradient Descent 逻辑回归梯度下降正则化
式子等同于线性回归正则化
虽然式子和线性回归的一模一样,不过这里的 $h_{\theta}(x)$ 代表的意义不同,逻辑回归中:
$$h_{\theta}(x) = \frac{1}{1+e^{-\theta^{T}x}}$$
四. Regularization 测试
1. Question 1
You are training a classification model with logistic regression. Which of the following statements are true? Check all that apply.
A. Introducing regularization to the model always results in equal or better performance on the training set.
B. Introducing regularization to the model always results in equal or better performance on examples not in the training set.
C. Adding many new features to the model makes it more likely to overfit the training set.
D. Adding a new feature to the model always results in equal or better performance on examples not in the training set.
解答: D
A、B 正则化的引入是解决过拟合的问题,而过拟合正是过度拟合数据但无法泛化到新的数据样本中。
D 增加一些特征量可能导致拟合在训练集原本没有被拟合到的数据,正确,这就是过拟合。
2. Question 2
Suppose you ran logistic regression twice, once with λ=0, and once with λ=1. One of the times, you got
parameters $\theta = \begin{bmatrix}
26.29\\
65.41
\end{bmatrix}$, and the other time you got $\theta = \begin{bmatrix}
2.75\\
1.32
\end{bmatrix}$. However, you forgot which value of λ corresponds to which value of θ. Which one do you think corresponds to λ=1?
A. $\theta = \begin{bmatrix}
26.29\\
65.41
\end{bmatrix}$
B. $\theta = \begin{bmatrix}
2.75\\
1.32
\end{bmatrix}$
解答: B
$\lambda = 1$表示正则化以后。正则化其实让我们的 $\theta_j$变小,所以选B。
3. Question 3
Which of the following statements about regularization are true? Check all that apply.
A. Using too large a value of λ can cause your hypothesis to overfit the data; this can be avoided by reducing λ.
B. Consider a classification problem. Adding regularization may cause your classifier to incorrectly classify some training examples (which it had correctly classified when not using regularization, i.e. when λ=0).
C. Because logistic regression outputs values 0≤hθ(x)≤1, its range of output values can only be "shrunk" slightly by regularization anyway, so regularization is generally not helpful for it.
D. Using a very large value of λ cannot hurt the performance of your hypothesis; the only reason we do not set λ to be too large is to avoid numerical problems.
解答: B
C 正则化对逻辑回归没用,错误。
A、D $\lambda$过大会导致欠拟合。
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub