一、为什么需要“指纹”?
在警察破案的时候,会经常接触到犯人的指纹。指纹能从生物的角度上判断它是不是某一个人。这么看来,指纹相当于一个人独一无二的东西,通过他就能找到对应唯一的一个人。
在网络传输过程中,可能存在中间人。那人们就有了这样的想法:能不能找到消息的“指纹”?这样就可以知道消息是谁发送的,从而避免中间人的攻击。
二、单向散列函数
开发者日常工作中会使用 git 命令。git diff 命令可以比对 2 次 commit,展示出两者不同的地方。那么相同的文件不会展示。那么 git diff 是如何对比两个文件的呢?如果一个文件巨大,能否有一个简单快捷的方式能判断文件是否被更改了呢?
这个时候文件的“指纹”的作用就凸显出来了。从一一比对 2 个文件的每一行,到现在只需要比对文件的“指纹”信息,如果一个指纹信息就能检查文件完整性,该多么方便啊!
单向散列函数就是一种采集文件“指纹”的技术。单向散列函数生成的散列值,就相当于消息的“指纹”。单向散列函数(one-way hash function)有一个输入和一个输出,其中输入成为消息(message),输出成为散列值(hash value)。单向散列函数可以根据消息的内容计算散列值,而散列值就可以被用来检查消息的完整性。
这个的消息可以是更加广义的消息,可以是图片,也可以是声音,单向散列函数并不需要关心消息实际代表的含义。在单向散列函数的眼里只有 0、1、0、1 比特流。
单向散列函数计算出来的散列值的长度和消息的长短没有关系。以 SHA-256 为例,它计算出来的散列值永远都是 256 比特(32 字节)。
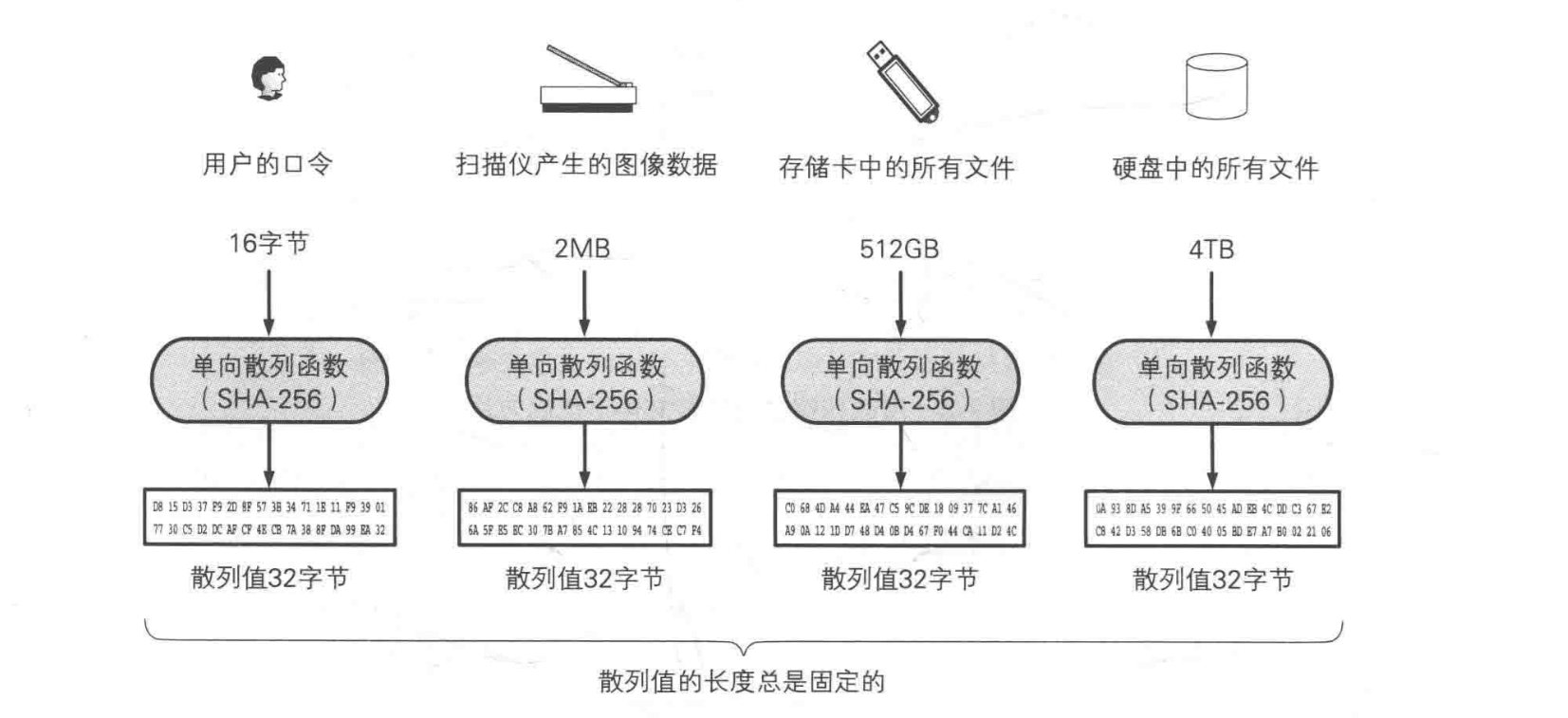
单向散列函数有以下几点性质:
1. 根据任意长度的消息计算出固定长度的散列值
2. 能够快速计算出散列值
3. 消息不同,散列值也不同
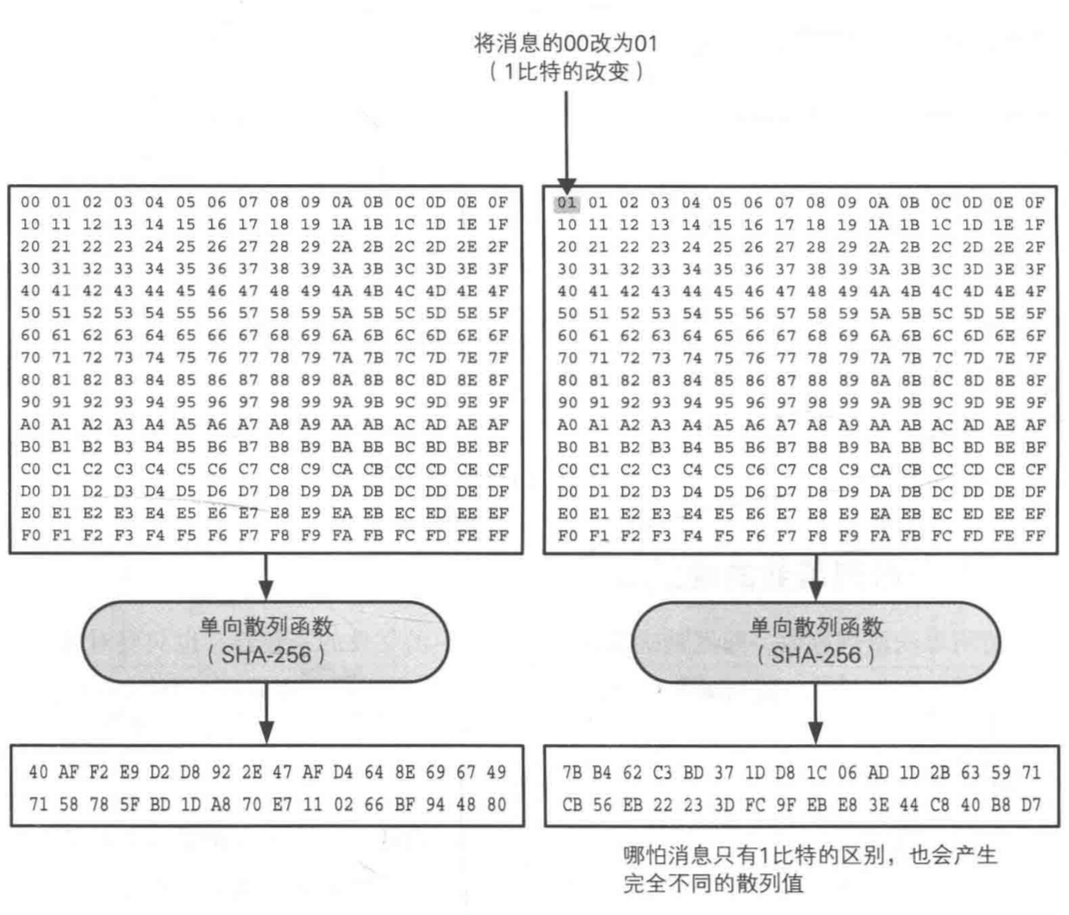
最后一点性质是最关键的。如果 2 个文件不同,算出的散列值却是相同的,那么单向散列函数的意义也就不存在了。实际上,两个不同的消息产生同一个散列值的情况称为**“碰撞(collision)”**。散列函数需要确保在不人为干涉的情况下,不存在碰撞的情况。密码学中所使用的单向散列函数,都需要具备抗碰撞性质。
单向散列函数必须要确保要找到和该条消息具有相同散列值的另外一条消息是非常困难的,这一性质称为弱抗碰撞性,单向散列函数都必须具备弱抗碰撞性。
要找到具有相同散列值但互不相同的两条消息是非常困难的,这一性质称为强抗碰撞性。这里的散列值可以是任意值。
密码技术中所使用的单向散列函数,不仅要具备弱抗碰撞性,还必须具备强抗碰撞性。
这里的弱抗碰撞性和强抗碰撞性是相对的概念,并不是说“很弱而不具备抗碰撞性”!
4. 单向性
单向散列函数必须具备单向性,单向性指的是无法通过散列值反算出消息的性质。
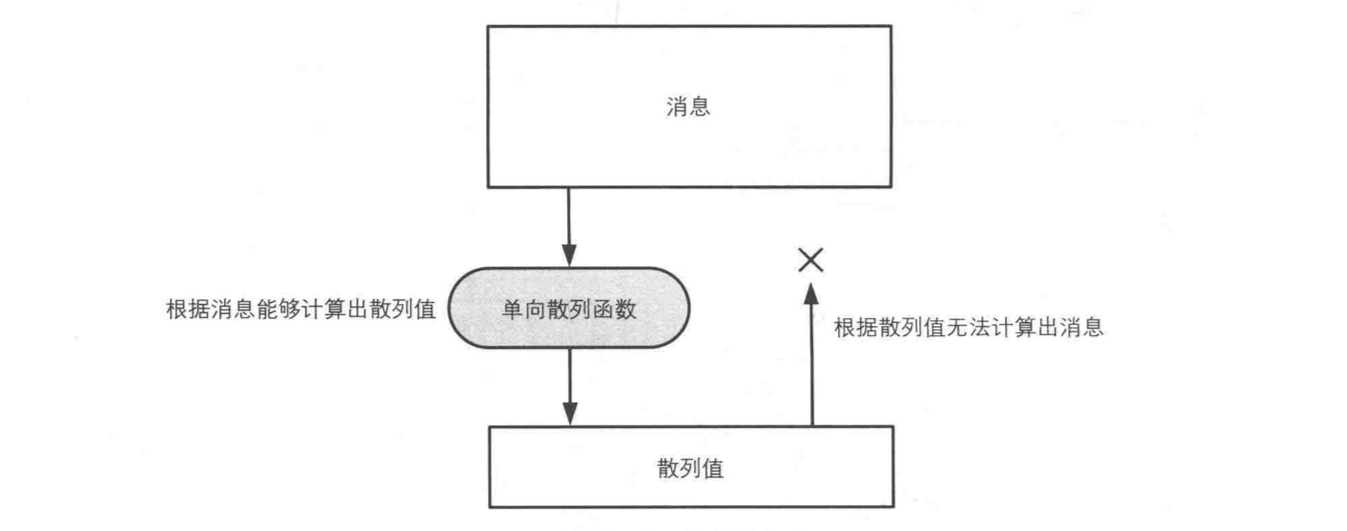
如上图所示,反算出消息的路是不通的。这也就是单向散列函数,单向两个字的来源。需要特别注意的一点是,单向散列函数并不是一种加密,所以它是无法通过解密的方法得到原消息的。
单向散列函数也称为消息摘要函数(message digest function)、哈希函数、杂凑函数。输入单向函数的消息也称为原像(pre-image)。单向散列函数输出的散列值也称为消息摘要(message digest)或者指纹(fingerprint)。完整性也被称为一致性。
对于攻击者来说,Hash 算法的破解难度是,强抗碰撞性<弱抗碰撞性<单向性。
三、单向散列函数的实际应用
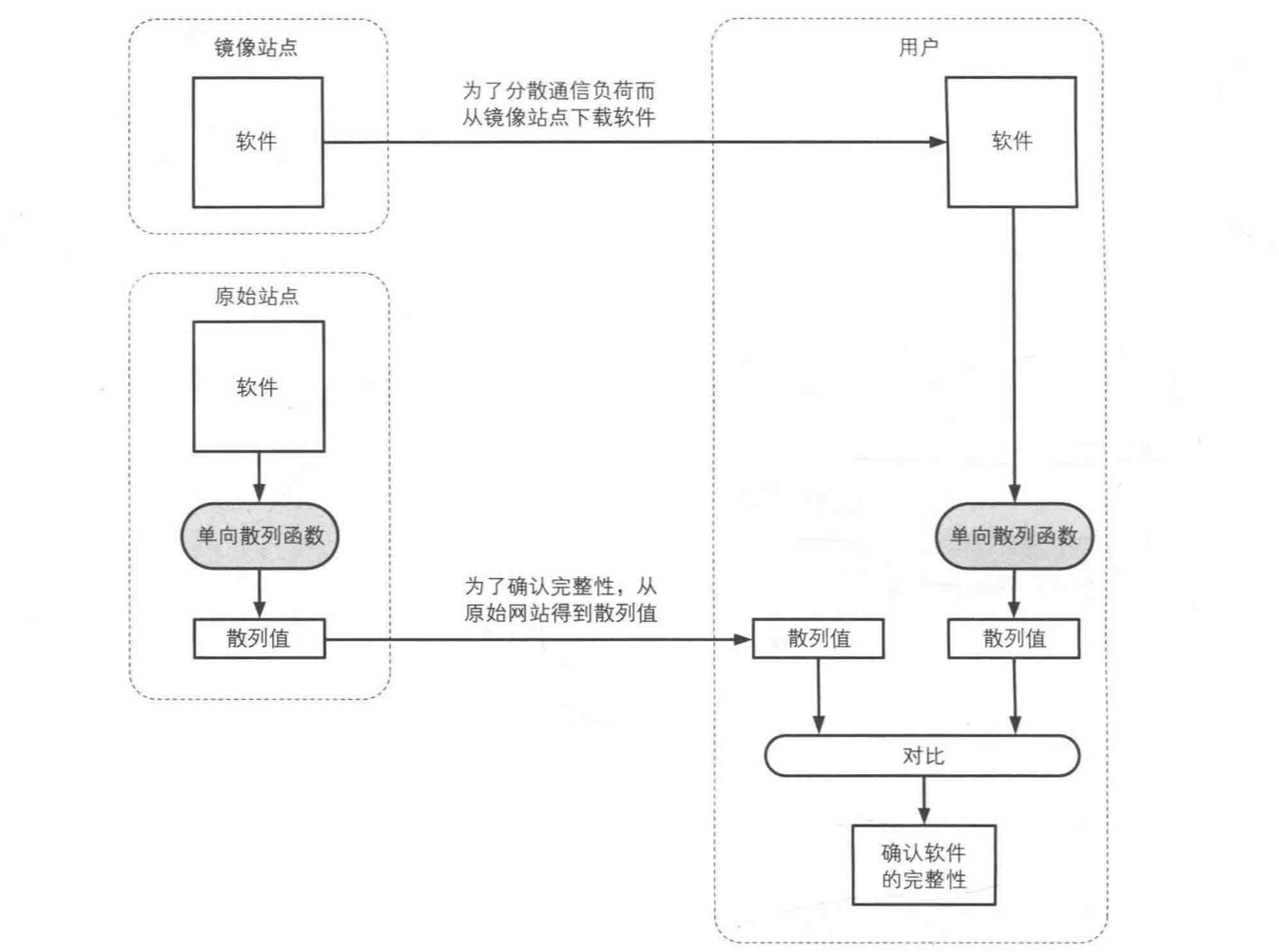
- 检测软件是否被篡改
- 基于口令的加密
单向散列函数也被用于基于口令的加密(Password Based Encryption,PBE)。PBE 的原理是将口令和盐(salt,通过伪随机数生成器产生的随机值)混合后计算其散列值,然后将这个散列值用作加密的密钥。通过这样的方法能够防御针对口令的字典攻击。
- 消息认证码
使用单向散列函数可以构造消息认证码。消息认证码是将“发送者和接收者之间的共享密钥”和“消息”进行混合后计算出的散列值。使用消息认证码可以检测并防止通信过程中的错误,篡改以及伪装。具体应用在 SSL/TLS 中。
- 数字签名
数字签名中也会用到单向散列函数。数字签名一般不会对整个消息内容进行直接施加数字签名,而是先通过单向散列函数计算出消息的散列值,然后再对散列值加上数字签名。
- 伪随机数生成器
使用单向散列函数可以构造伪随机数生成器。为了保证不能根据过去的随机数列预测未来的随机数列,可以利用单向散列函数的单向性。
- 一次性口令
一次性口令经常被用于服务器对客户端合法性认证。利用单向散列函数可以保证口令只在通信链路上传送一次,因此即使窃听者窃取了口令,也无法再次使用了。
四、单向散列函数现状
| 算法 | 比特位 | 公布年份 | 作者 | 现状 |
|---|---|---|---|---|
| MD4 (Message Digest 4,消息摘要 4) | 128 位比特(RFC 1186,修订版 RFC 1320) | 1990 年 | Rivest | Dobbertin 寻找到 MD4 散列碰撞的方法,目前已经不再安全❌ |
| MD5 (Message Digest 5,消息摘要 5) | 128 位比特(RFC 1321) | 1991 年 | Rivest | 2004 年王小云教授提出针对 MD5、SHA-0 等散列函数的碰撞攻击算法,故 MD5 目前已经不再安全❌ |
| SHA | 160 比特位 | 1993 年 | NIST (National Institute of Standards and Technology,美国国家标准技术研究所) | 发布以后很快被 NSA (National Security Agency,美国国家安全局)撤回,目前已经不安全❌ |
| SHA-1 | 160 比特位 | 1995 年 | NIST (National Institute of Standards and Technology,美国国家标准技术研究所) | 2005 年 SHA-1 的强抗碰撞性被攻破;2017 年荷兰密码学研究小组 CWI 和 Google 正式宣布攻破了 SHA-1❌ |
| RIPEMD-160 | 160 比特 | 1996 年 | 欧盟 RIPE 项目中由 Hans Dobbertin、Antoon Bosselaers 和 Bart Preneel 设计 | RIPEMD 的强抗碰撞性于 2004 年被攻破,但是 RIPEMD-160 还尚未被攻破,目前安全✅比特币中使用的就是 RIPEMD-160 |
| SHA-2 | SHA-224 224 位、SHA-256 256 位、SHA-384 384 位、SHA-512 512 位、SHA-512/224 224 位、SHA-512/256 256 位 | 2001 年 | NIST (National Institute of Standards and Technology,美国国家标准技术研究所) | 目前还没有被攻破,安全✅ |
| SHA-3 | SHA3-224 224 位、SHA3-256 256 位、SHA3-384 384 位、SHA3-512 512 位、SHAKE128 d(arbitrary)位、SHAKE256 d(arbitrary)位 | 2015 年 | NIST (National Institute of Standards and Technology,美国国家标准技术研究所) | 目前还没有被攻破,安全✅ |
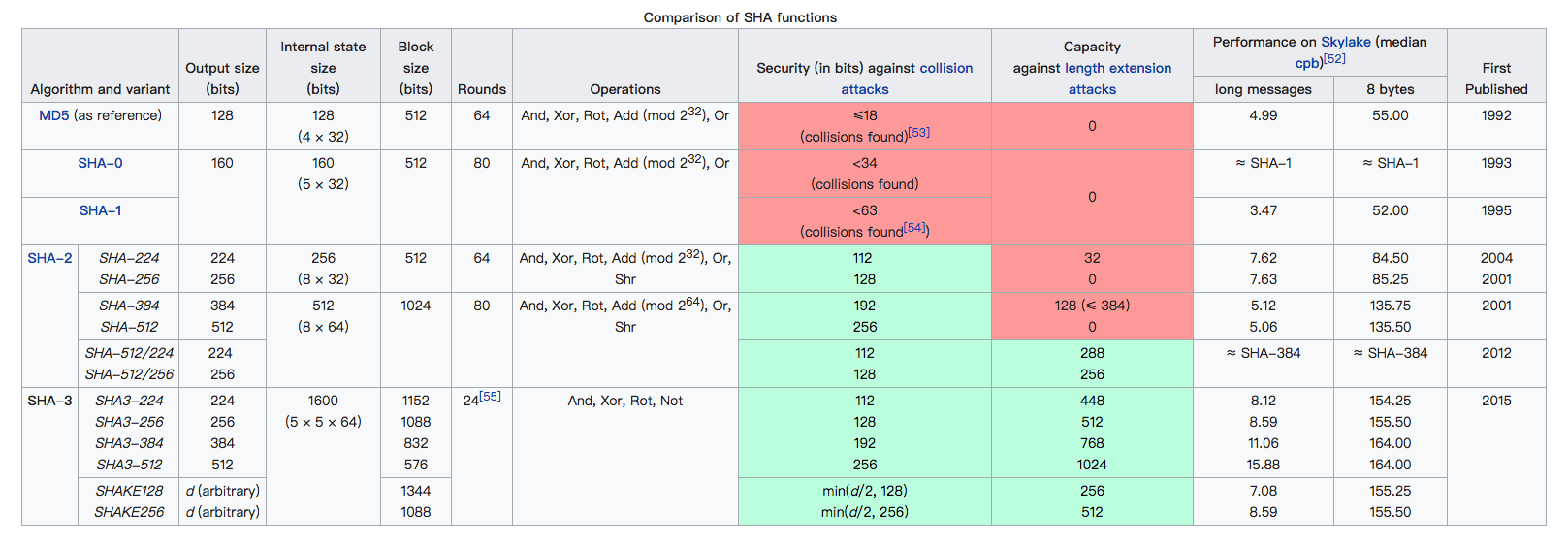
注意:Hash 算法输出值长度和运算性能没有必然联系。举例:运算的数据块越大,sha384 算法的性能比 sha256 算法性能高。这一点务必要注意!
五、Keccak 算法
2007年,NIST 开始了 SHA-3 的公开征集,截止到 2008 年共征集到了 64 个算法。
2010年,SHA-3 最终候选名单出炉,其中包括 5 个算法。
2012年,经过长达 5 年的选拔,最终将 Guido Bertoni、Joan Daemen、Michaël Peeters 和 Gilles Van Assche 共同设计的 Keccak 算法被确定为 SHA-3 标准。其中 Joan Daemen 也是对称密码算法 AES 的设计者之一。
Keccak 最终被选为 SHA-3 的理由如下:
- 采用了与 SHA-2 完全不同的结构
- 结构清晰,易于分析
- 能够适用于各种设备,也适用于嵌入式应用
- 在硬件上的实现显示了很高的性能
- 比其他最终候选算法安全性边际更大
Keccak 可以生成任意长度的散列值,但是为了配合 SHA-2 的散列值长度,SHA-3 标准中规定了 4 个版本兼容 SHA-2。在输入数据的长度上限方面,SHA-1 为 2^64 - 1 比特,SHA-2 为 2^128 - 1 比特,而 SHA-3 没有限制。
SHA-3 中另外两个 SHAKE 的函数,是支持输出任意长度散列值的。分别为 SHAKE128 和 SHAKE256 。SHAKE 这个名字 取自 Secure Hash Algorithm 与 Keccak 这几个单词。
Keccak 采用了和 SHA-1、SHA-2 完全不同的海绵结构(sponge construction)
1. 海绵结构

上图就是海绵结构,整个计算过程分为 2 步。第一步是吸收阶段(absorbing phase),第二步是**(squeezing phase)**。
第一步,吸收阶段:
- 将经过填充的输入消息按照每 r 个比特为一组分割成若干个输入分组。
- 首先,将 “内部状态的 r 个比特” 与 “输入分组 1” 进行 XOR,将其结果作为 “函数 f 的输入值”
- 然后,将“函数 f 的输出值 r 个比特” 与 “输入分组 2” 进行 XOR,将其结果再次作为 “函数 f 的输入值”。
- 反复执行上述步骤,直到到达最后一个分组。
- 待所有输入分组处理完成以后,结束吸收阶段,进入挤出阶段。
吸收阶段中,最初的内部状态是 b = r + c 个比特 0 。每次吸收 r 个比特的输入分组,与 r 个比特的内部状态位进行 XOR。内部状态 c 个比特不受输入分组的影响,但会受到函数 f 间接影响。r 称为比特率,c 称为容量。吸收完成以后,输出结果还是 b 个比特。
第二步,挤出阶段:
- 首先,将 “函数 f 的输出值中的 r 个比特” 保存为 “输出分组 1”,并将整个输出值 (r+c) 个比特再次输入到函数 f 中。
- 然后,将 “函数 f 的输出值中的 r 个比特” 保存为 “输出分组 2”,并将整个输出值 (r+c) 个比特再次输入到函数 f 中。
- 反复执行上述步骤,直到获得所需长度的输出数据。
无论是吸收状态还是挤出状态,函数 f 的逻辑是完全相同的。每执行一次函数 f,海绵结构的内部状态就会被搅拌一次。
挤出阶段执行的操作实际是 “对内部状态进行搅拌并产生输出分组 (r 个比特)” 的操作。以 r 个比特为单位,将海绵结构的内部状态中的数据一点点“挤”出来。
同样,在挤出阶段,内部状态中的 c 个比特是不会直接进入到输出分组中,这部分数据只会通过函数 f 间接影响输出的内容。因此,容量 c 的意义在于防止将输入消息中的一些特征泄露出去。
2. 双工结构
海绵结构有一个弊端,那就是必须要等吸收阶段吸收完成以后才能开始挤出阶段。于是 Keccak 对海绵结构进行了改进。提出了双工结构。如下图:
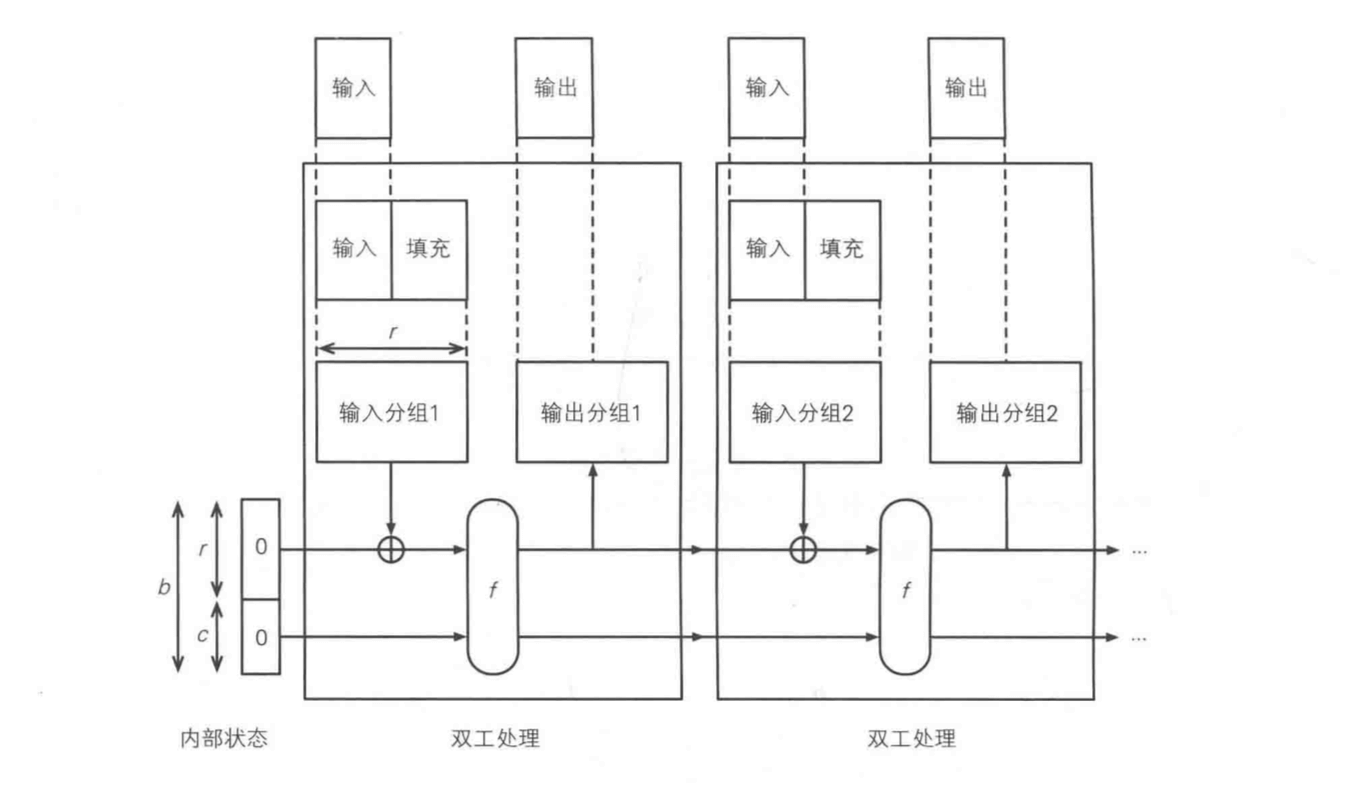
在双工结构中,输入和输出是以相同的速率进行的。在双向通信中,发送和接收同时进行的方式成为全双工(full duplex)。通过采用双工结构,Keccak 不仅可以用于计算散列值,还可以用来作为伪随机数生成器、流密码、认证加密、消息认证码等等。
六、Keccak 的内部状态
上一章节中,我们知道 Keccak 内部状态是有 b = r + c 个比特。这一章节我们深入研究一下内部状态是如何工作的。
Keccak 的内部状态是一个三维的比特数组。b 个小方块按照 5 * 5 * z 的方式组合起来,就成为一个沿 z 轴延伸的立方体。将具备 x、y、z 三个维度的内部状态整体称为 state,state 共有 b 个比特。
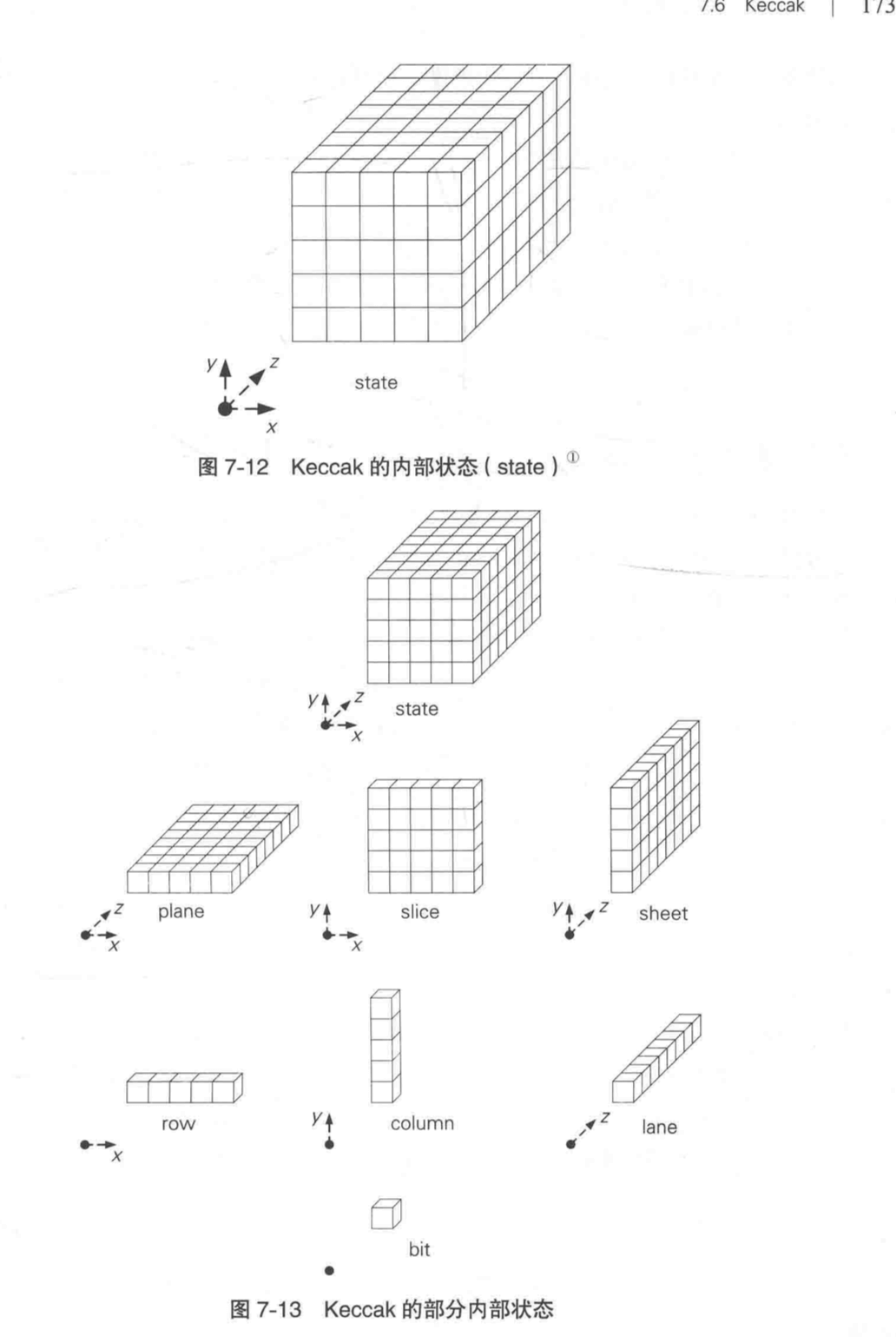
xz 平面称为 plane,xy 平面称为 slice,yz 平面称为 sheet。x 轴称为 row,y 轴称为 column,z 轴称为 lane。
整个 state 可以看出是 5 * 5 = 25 条 lane 组成的。也可以看成是 lane 长度的 slice 堆叠而成的。
Keccak 的实质就是实现一个能够将上述结构的 state 进行有效搅拌的函数 f。由于内部状态可以代表整个处理过程中的全部中间状态,因此有利于节约内存。Keccak 用到了很多比特单位的运算,因此可以有效抵御针对字节单位的攻击。
1. 函数 Keccak-f[b]
Keccak 中的内部函数实际上叫做 Keccak-f[b] 。参数 b 就是内部状态的总比特长度,这里称为宽度。根据设计规格,b 可以取 25(5 * 5 * 2^0)、50(5 * 5 * 2^1)、100(5 * 5 * 2^2)、200(5 * 5 * 2^3)、400(5 * 5 * 2^4)、800(5 * 5 * 2^5)、1600(5 * 5 * 2^6) 总共 7 种值。SHA-3 采用的是其中的最大宽度,即 b = 1600 。之所以都是 25 的倍数,是因为一个 slice 是 25 个 比特。b / 25 = slice 的片数 = lane 的长度。
在 Keccak 中,通过改变宽度 b 就可以改变内部状态的比特长度。但无论如何改变,slice 的大小依然是 5 * 5,改变的只有 lane 的长度而已。因此 Keccak 的宽度变化不影响其基本结构,这种结构也被称为套娃结构。
Keccak-f[b] 中每一轮包含 5 个步骤:θ(西塔),ρ(柔),π(派),χ(凯),τ(伊欧塔),总共循环 12 + 2ι 轮。(定义 2^ι = b / 25)。SHA-3 使用的是 Keccak-f[1600] 函数,b = 1600,ι = 6,故总共循环 12 + 2 * 6 = 24 轮。
2. 步骤 θ
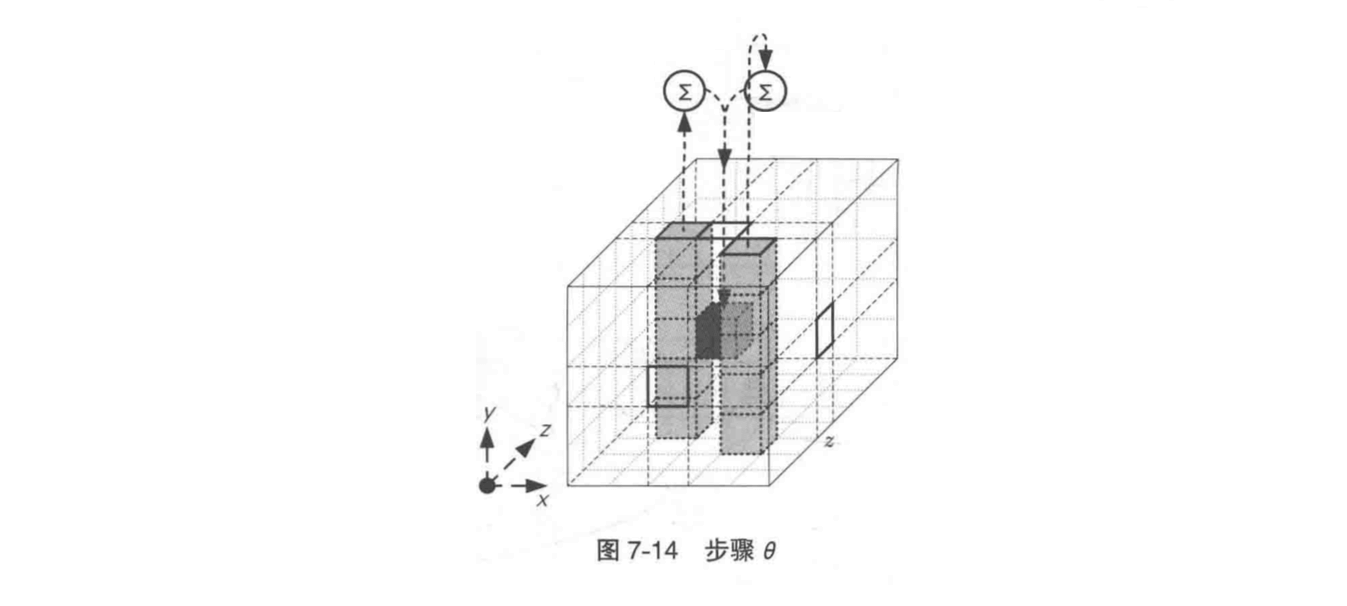
这一步的操作是将位置不同的两个 column 中各自 5 个比特通过 XOR 运算加起来,然后再与置换目标比特求 XOR 并覆盖掉目标比特。
3. 步骤 ρ
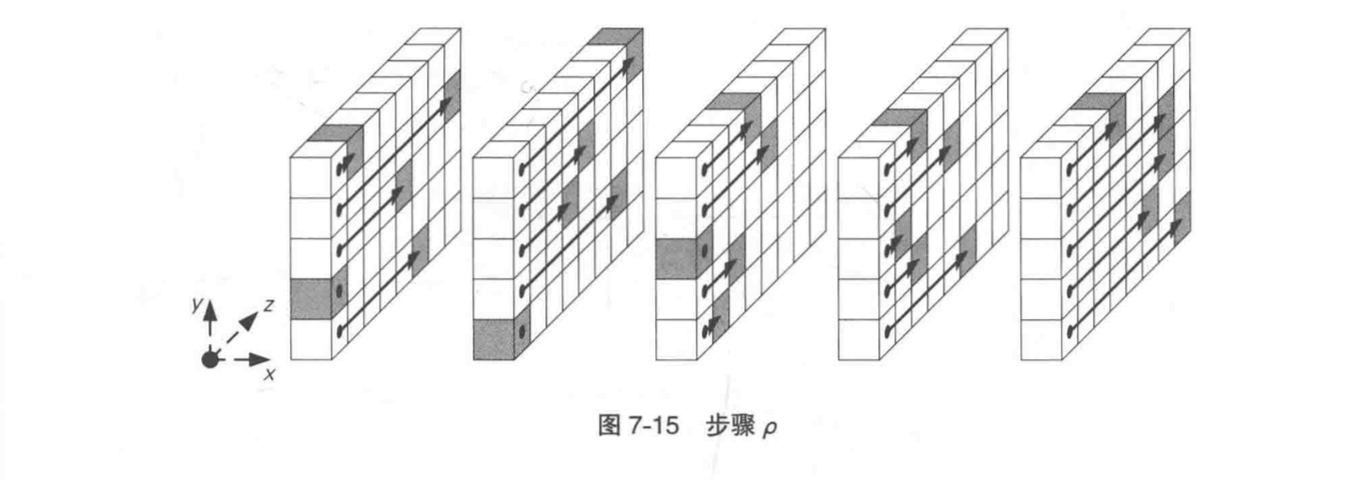
这一步的操作是沿 z 轴方向进行比特平移。
4. 步骤 π
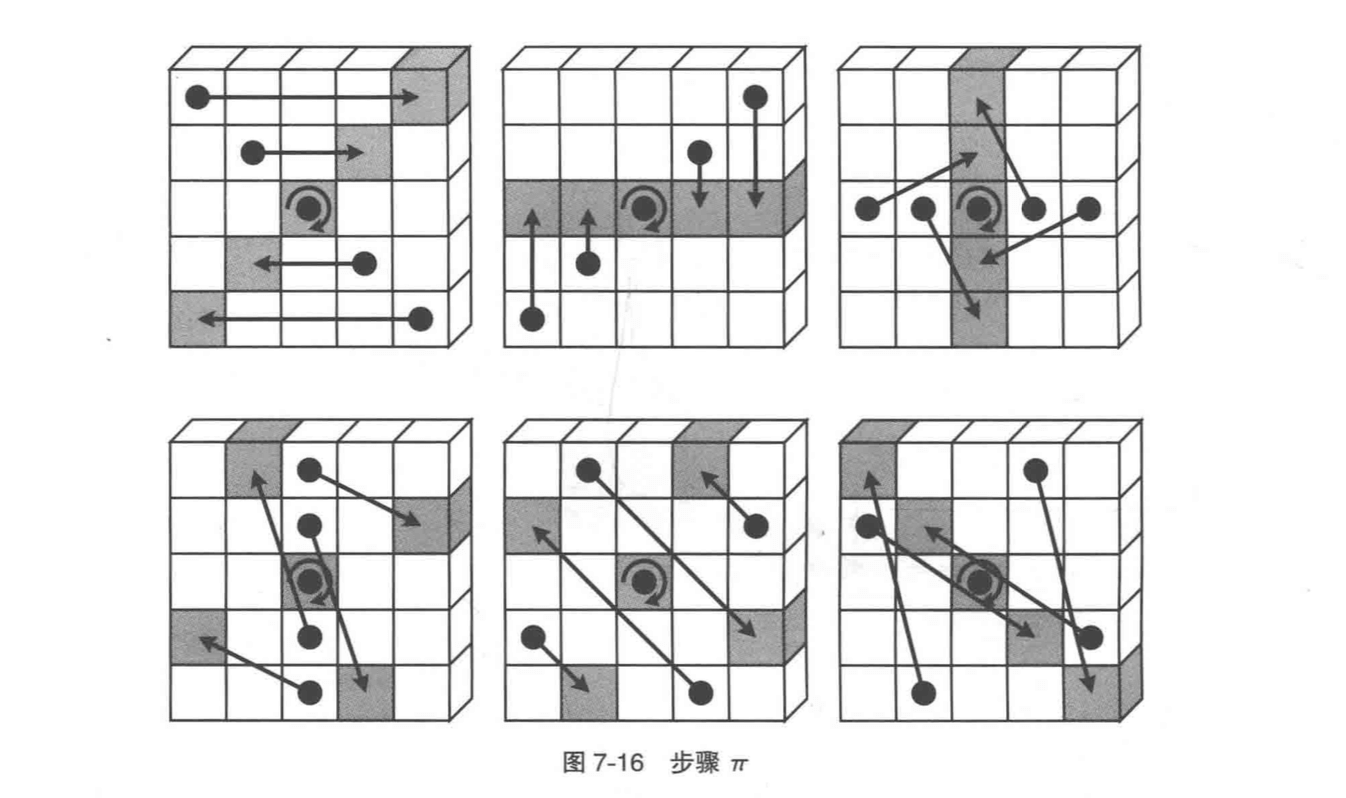
上图中展示的对其中 1 片 slice 进行步骤 π 的操作,实际上整条 lane 上的所有 slice 都会被执行同样的比特移动操作。
5. 步骤 χ
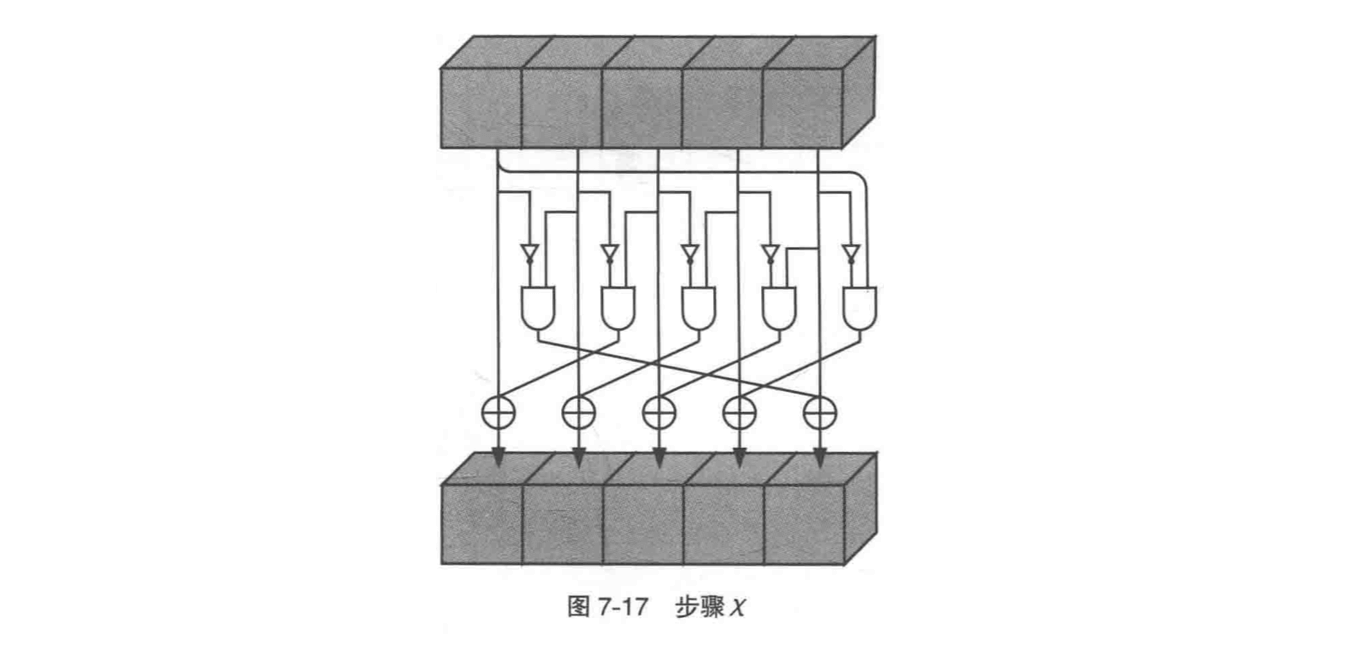
上图中展示的对其中 1 个 row 进行步骤 χ 的操作,图中有逻辑电路的符号,倒三角是逻辑取反 NOT 操作,倒字母 D 是逻辑与,AND 操作。
6. 步骤 τ
这一步是用一个固定的轮常数对整个 state 的所有比特进行 XOR 运算,目的是让内部状态具备费对称性。
以上 5 步,除了步骤 θ 中的奇偶性处理以及步骤 χ 中的 NOT 和 AND 以外,其余的操作仅通过硬件电路就都可以实现。
7. 对 Keccak 的攻击
Keccak 之前的所有单向散列函数都是通过循环执行压缩函数的方式生成散列值的,例如 MD4、MD5、RIPEMD、RIPEMD-160、SHA-1、SHA-2 等几乎所有的传统单向散列值函数算法都是基于 MD (Merkle-Damgard construction) 结构的。
为了方式 SHA-3 会被 MD 结构的影响,所以 SHA-3 在设计之初就放弃了 MD 结构。采用了完全不同的海绵结构。因为针对 SHA-1 的攻击方法对 SHA-3 是无效的。
到目前为止还没有出现能够对实际运用中的 Keccak 算法形成威胁的攻击方法。
七、对单向散列函数的攻击
1. 暴力破解
利用文件的冗余性,暴力修改文件,每次都稍微改变一下消息的值,对这些消息求散列值,一旦有一个散列值和之前的散列值一样,就算暴力破解成功。这相当于是一种试图破解单向散列函数的“弱抗碰撞性”的攻击。
找出具有指定散列值的消息的攻击分为两种:**原像攻击(Pre-Image Attack)**是指给定一个散列值,找出具有该散列值的任意消息;**第二原像攻击(Second Pre-Image Attack)**是指定给一条消息 1,找出另外一个消息 2,消息 2 的散列值和消息 1 相同。
2. 生日攻击
生日攻击(birthday attack)或者冲突攻击(collision attack)不是寻找生成特定散列值的消息,而是要找到散列值相同的 2 条消息,散列值可以是任意值。这种试图破解单向散列函数的“强抗碰撞性”的攻击。
生日攻击的原理来自生日悖论,也就是利用了“任意散列值一致的概率比想象中要高”这样的特性。以 512 比特的散列值为例,对单向散列函数进行暴力破解所需要的尝试次数为 2^512 次,而对同一单向散列函数进行生日攻击所需的尝试次数为 2^256 次,因此和暴力破解相比,生日攻击所需的尝试次数要少得多。
2005 年王小云教授团队提出的碰撞攻击方法中,对于 SHA-1 所需要的尝试次数为 2^69 次,已大大少于生日攻击所需要的 2^80 次,同年王小云教授团队尤改进了该方法,使尝试次数再次减少到 2^63 次。
八、单向散列函数无法解决的问题
单向散列函数能够辨别出“篡改”,但是无法辨别出“伪装”。对于一条消息不仅需要确认消息的完整性,还需要确认这个消息发自与谁。这仅仅靠完整性检查是不够的,还需要进行消息认证。认证的技术包括消息验证码和数字签名。
消息验证码能够向通信对象保证消息没有被篡改。数字签名不仅能够向通信对象保证消息没有篡改,还能够向所有第三方做出这样的保证。
Reference:
《图解密码技术》
SHA-3 wikipedia
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub



