一. Building a Spam Classifier
垃圾邮件分类就是一个 0/1 分类问题,可以用逻辑回归完成,这里不再重复介绍逻辑回归的过程了,我们考虑如何降低分类错误率:
- 尽可能的扩大数据样本:Honypot 做了这样一件事,把自己包装成一个对黑客极具吸引力的机器,来诱使黑客进行攻击,就像蜜罐(honey pot)吸引密封那样,从而记录攻击行为和手段。
- 添加更多特征:例如我们可以增加邮件的发送者邮箱作为特征,可以增加标点符号作为特征(垃圾邮件总会充斥了?,!等吸引眼球的标点)。
- 预处理样本:正如我们在垃圾邮件看到的,道高一尺,魔高一丈,垃圾邮件的制造者也会升级自己的攻击手段,如在单词拼写上做手脚来防止邮件内容被看出问题,例如把 medicine 拼写为 med1cinie 等。因此,我们就要有手段来识别这些错误拼写,从而优化我们输入到逻辑回归中的样本。
假如我们要用机器学习解决一个问题,那么最好的实践方法就是:
1.建立一个简单的机器学习系统,用简单的算法快速实现它。
2.通过画出学习曲线,以及检验误差,来找出我们的算法是否存在高偏差或者高方差的问题,然后再通过假如更多的训练数据、特征变量等等来完善算法。
3.误差分析。例如在构建垃圾邮件分类器,我们检查哪一类型的邮件或者那些特征值总是导致邮件被错误分类,从而去纠正它。当然,误差的度量值也是很重要的,例如我们可以将错误率表示出来,用来判断算法的优劣。
二. Handling Skewed Data
评估一个模型的好坏,通常使用误差分析可视化,即把预测的准确率(Accuracy)显示出来,其实这样是有缺陷的。这种误差度量又被称为偏斜类(Skewed Classes)问题。

举个例子:假如我们做癌症分析,最后得出该算法只有1%的误差,也就是说准确率达到了99% 。这样看起来99%算是非常高的了,但是我们发现在训练集里面只有0.5%的患者患有癌症,那么这1%的错误率就变得那么准确了。我们再举个极端一点的例子,无论输入是什么,所有预测输出的数据都为0(也就是非癌症),那么我们这里的正确率是99.5%,但是这样的判断标准显然不能体现分类器的性能。
这是因为两者的数据相差非常大,在这里因为癌症的样本非常少,所以导致了预测的结果就会偏向一个极端,我们把这类的情况叫做偏斜类(Skewed Classes)问题。
所以我们需要另一种的评估方法,其中一种评估度量值叫做查准率(Precision)和召回率(Recall)。
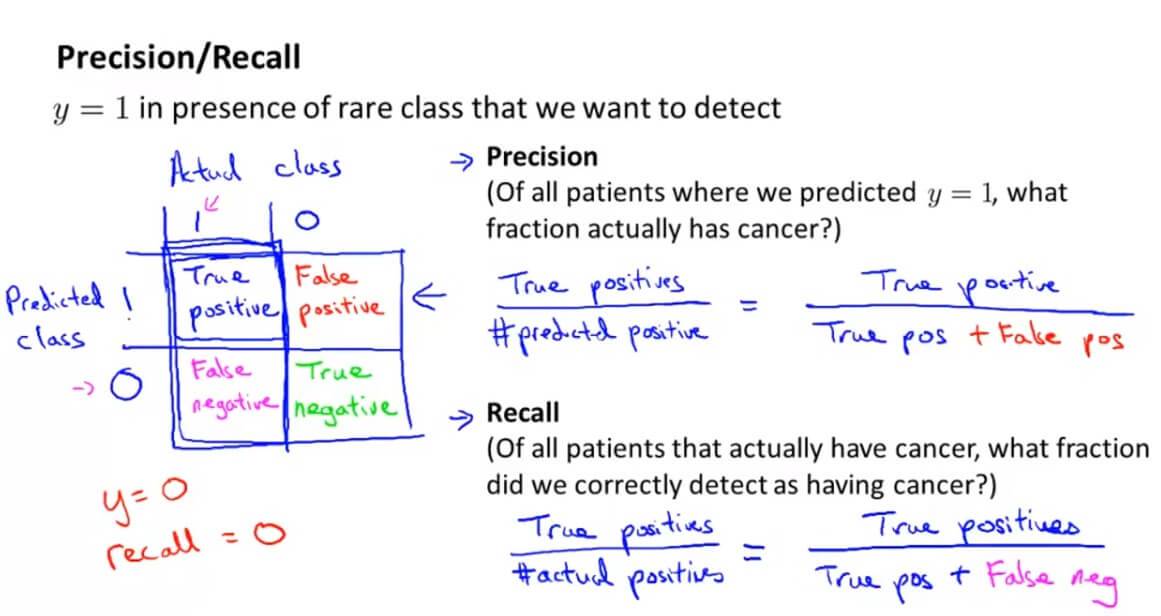
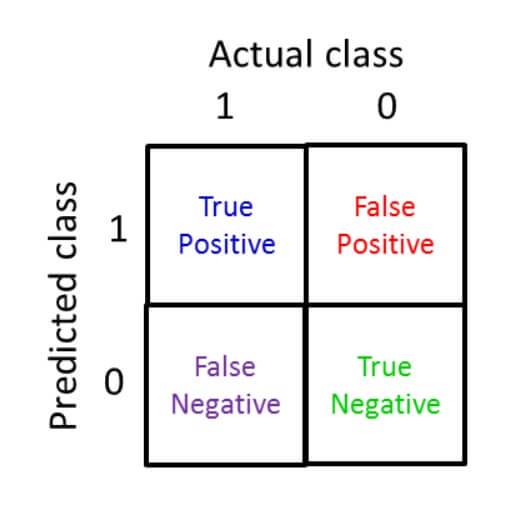
建立一个2 x 2的表格,横坐标为真实值,纵坐标为预测值,表格单元1-4分别代表:预测准确的正样本(True positive)、预测错误的正样本(False positive)、预测错误的负样本(False negative)、预测正确的负样本(True negative)。
查准率(Precision)= 预测准确的正样本(True positive)/预测的正样本(predicted positive),而其中预测的正样本自然就包括了 预测准确的正样本+ 预测错误的正样本。
召回率(Recall)= 预测准确的正样本(True positive)/实际的正样本(actual positive),而其中实际的正样本自然就包括了 预测准确的正样本+ 预测错误的负样本。
假如像之前的y一直为0,虽然其准确率为99%,但是其召回率是0%。所以这对于评估算法的正确性是非常有帮助的。
那么查准率(Precision)和召回率(Recall)应该如何评估呢?
假如我们选用两者的平均值,这样看起来可行,但是对于之前的极端例子还是不适用。假如我们预测的y一直为1,那么其召回率就100%了,而查准率非常低,但是平均下来还是相对不错。所以我们采用下面一种评估方法,叫做 F 值:
$$F_1\;Score = 2\frac{PR}{P+R}$$
P 指的是 Precision,R 指的是 Recall。
三. Using Large Data Sets
在机器学习领域,流传着这样一句话:
It's not who has the best algorithm that wins. It's who has the most data.
取得成功的人不是拥有最好算法的人,而是拥有最多数据的人。
这是为什么呢?
首先我们因为有大量的特征量,去训练数据,这样就导致了我们的训练集误差非常小,也就是 $J_{train}(\theta)$ 非常小。然后我们提供了大量的训练数据,这样有利于防止过拟合,可以使得 $J_{train}(\theta)\approx J_{test}(\theta)$ 。这样,我们的假设函数既不会存在高偏差,也不会存在高方差,所以相对而言,大数据训练出来会更加准确。
注意了,这里不仅是由大量的训练数据,而且还要有更多的特征量。因为假如只有一些特征量,例如只有房子的大小,去预测房子的价格,那么就连世界最好的销售员也不能只凭房子大小就能告诉你房子的价格是多少。
什么时候采用大规模的数据集呢,一定要保证模型拥有足够的参数(线索),对于线性回归/逻辑回归来说,就是具备足够多的特征,而对于神经网络来说,就是更多的隐层单元。这样,足够多的特征避免了高偏差(欠拟合)问题,而足够大数据集避免了多特征容易引起的高方差(过拟合)问题。
四. Machine Learning System Design 测试
1. Question 1
You are working on a spam classification system using regularized logistic regression. "Spam" is a positive class (y = 1) and "not spam" is the negative class (y = 0). You have trained your classifier and there are m = 1000 examples in the cross-validation set. The chart of predicted class vs. actual class is:
Actual Class: 1 Actual Class: 0
Predicted Class: 1 85 890
Predicted Class: 0 15 10
For reference:
- Accuracy = (true positives + true negatives) / (total examples)
- Precision = (true positives) / (true positives + false positives)
- Recall = (true positives) / (true positives + false negatives)
- F1 score = (2 * precision * recall) / (precision + recall)
What is the classifier's F1 score (as a value from 0 to 1)?
Enter your answer in the box below. If necessary, provide at least two values after the decimal point.
解答:0.158
代入公式 $2\frac{PR}{P+R}$ 计算即可。
2. Question 2
Suppose a massive dataset is available for training a learning algorithm. Training on a lot of data is likely to give good performance when two of the following conditions hold true.
Which are the two?
A. When we are willing to include high order polynomial features of x (such as $x_{1}^{2}$, $x_{2}^{2}$,$x_{1}$,$x_{2}$, etc.).
B. The features x contain sufficient information to predict y accurately. (For example, one way to verify this is if a human expert on the domain can confidently predict y when given only x).
C. We train a learning algorithm with a small number of parameters (that is thus unlikely to overfit).
D. We train a learning algorithm with a large number of parameters (that is able to learn/represent fairly complex functions).
解答:B、D
A. 需要的是足够的特征量而不是高阶。
B. 特征量有足够的信息来准确预测。
C. 少量的特征量显然是不行的。
D. 要有足够多的变量(特征量)。
3. Question 3
Suppose you have trained a logistic regression classifier which is outputing hθ(x).
Currently, you predict 1 if $h_{\theta}(x)\geqslant threshold$, and predict 0 if $h_{\theta}(x)<threshold$, where currently the threshold is set to 0.5.
Suppose you decrease the threshold to 0.3. Which of the following are true? Check all that apply.
A. The classifier is likely to have unchanged precision and recall, but higher accuracy.
B. The classifier is likely to now have higher precision.
C. The classifier is likely to now have higher recall.
D. The classifier is likely to have unchanged precision and recall, but lower accuracy.
解答:C
将阈值调低的结果只会导致召回率增大,查准率降低。
4. Question 4
Suppose you are working on a spam classifier, where spam emails are positive examples (y=1) and non-spam emails are negative examples (y=0). You have a training set of emails in which 99% of the emails are non-spam and the other 1% is spam. Which of the following statements are true? Check all that apply.
A. If you always predict non-spam (output y=0), your classifier will have 99% accuracy on the training set, but it will do much worse on the cross validation set because it has overfit the training data.
B. If you always predict non-spam (output y=0), your classifier will have 99% accuracy on the training set, and it will likely perform similarly on the cross validation set.
C. A good classifier should have both a high precision and high recall on the cross validation set.
D. If you always predict non-spam (output y=0), your classifier will have an accuracy of 99%.
解答:B、C、D
A. 在交叉验证集因为过拟合的问题会使准确率下降,这不是过拟合的问题,是偏斜类的问题。
B. 假如训练集有99%准确率,那么交叉验证集也有很大可能有99%的准确率,这是正确的,因为数据是随机分布的,训练集的数据分布跟交叉验证集的数据分布相似。
C. 一个好的分类器应该查准率和召回率都比较高,正确。
D. 假如我们都把结果设为全为非垃圾邮件,那么准确率将达到99%,正确。
5. Question 5
Which of the following statements are true? Check all that apply.
A. On skewed datasets (e.g., when there are more positive examples than negative examples), accuracy is not a good measure of performance and you should instead use F1 score based on the precision and recall.
B. If your model is underfitting the training set, then obtaining more data is likely to help.
C. After training a logistic regression classifier, you must use 0.5 as your threshold for predicting whether an example is positive or negative.
D. It is a good idea to spend a lot of time collecting a large amount of data before building your first version of a learning algorithm.
E. Using a very large training set makes it unlikely for model to overfit the training data.
解答:A、E
A.利用 F1 score 去衡量准确性,正确。
B.模型不适合训练集,是欠拟合,欠拟合增大数据样本没用。
C.阈值不一定是0.5。
D.在建立第一个学习算法前花大量时间收集数据显然有可能走向浪费时间的不归路。
E.用更多的数据样本可以解决过拟合的现象,正确。
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub