一. Motivation
我们很希望有足够多的特征(知识)来保准学习模型的训练效果,尤其在图像处理这类的任务中,高维特征是在所难免的,但是,高维的特征也有几个如下不好的地方:
- 学习性能下降,知识越多,吸收知识(输入),并且精通知识(学习)的速度就越慢。
- 过多的特征难于分辨,你很难第一时间认识某个特征代表的意义。
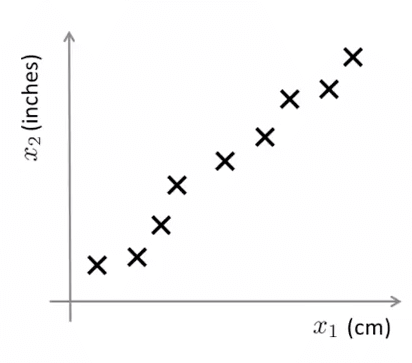
- 特征冗余,如下图所示,厘米和英尺就是一对冗余特征,他们本身代表的意义是一样的,并且能够相互转换。
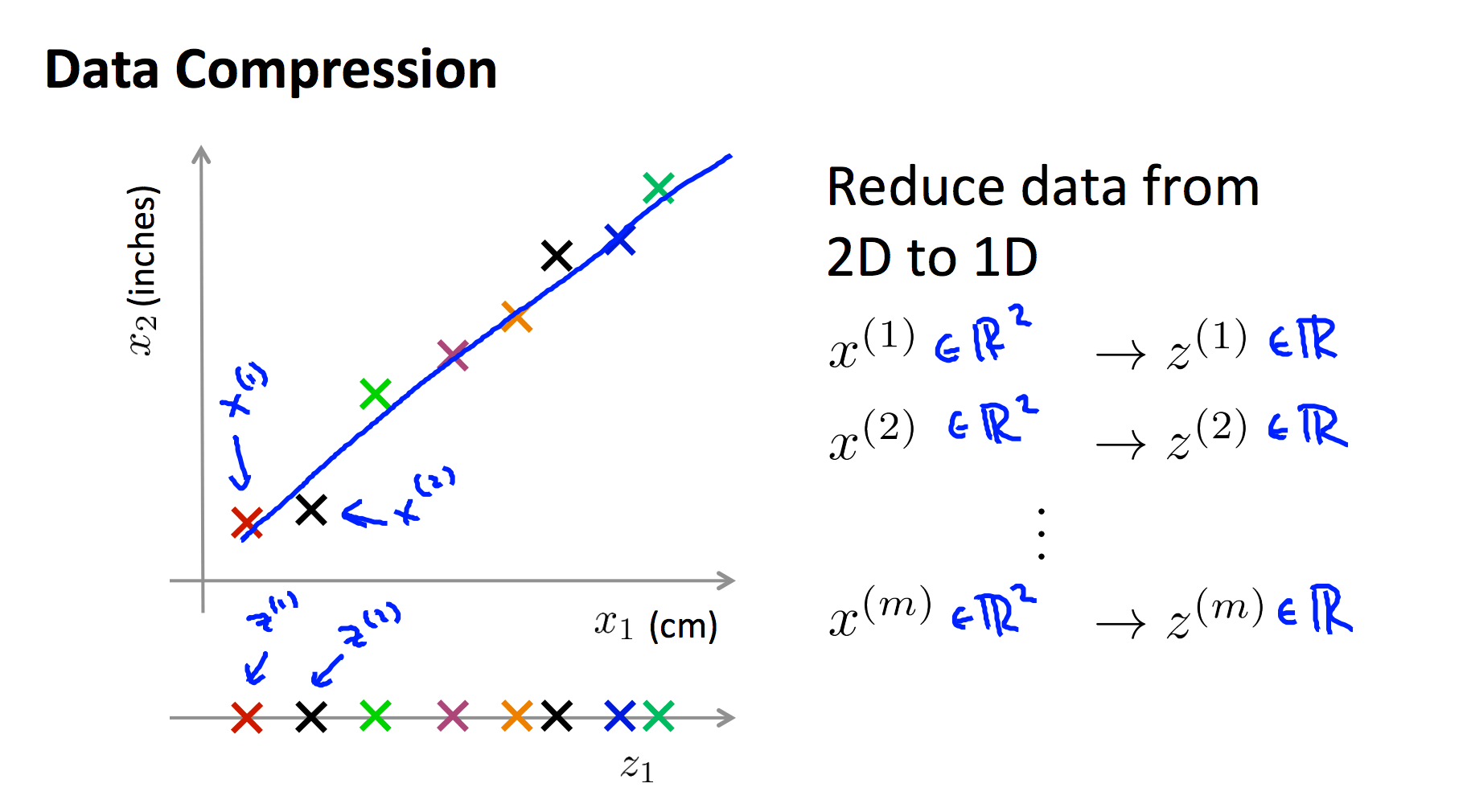
我们使用现在使用了一条绿色直线,将各个样本投影到该直线,那么,原来二维的特征 x=(厘米,英尺) 就被降低为了一维 x=(直线上的相对位置)
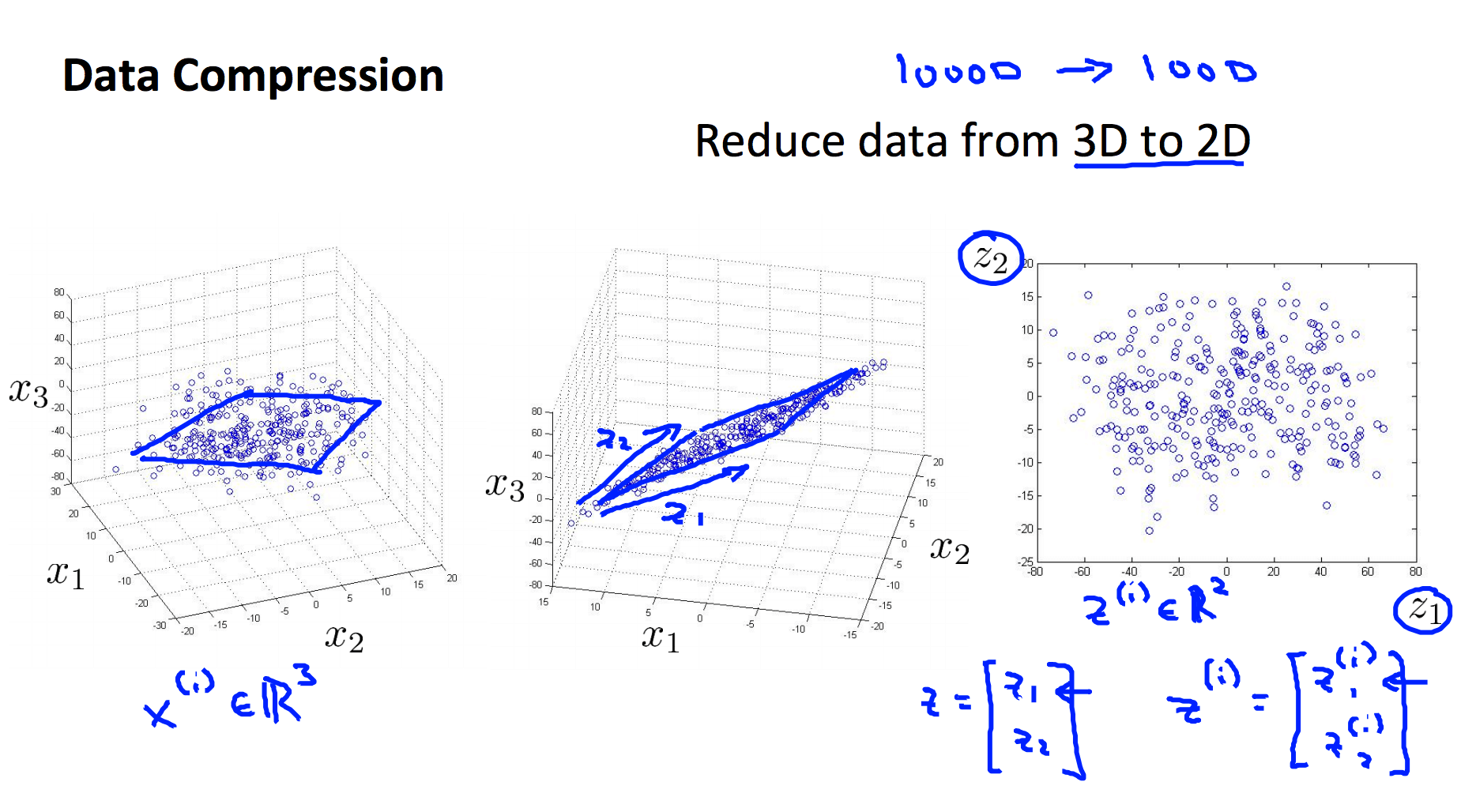
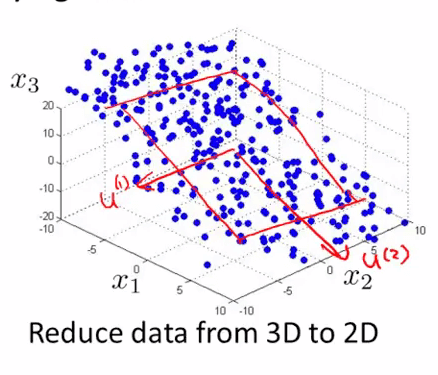
而在下面的例子中,我们又将三维特征投影到二位平面,从而将三维特征降到了二维:
特征降维的一般手段就是将高维特征投影到低维空间。
降维的动机有两个:
- 压缩数据
- 数据可视化
二. Principal Component Analysis 主成分分析
PCA,Principle Component Analysis,即主成分分析法,是特征降维的最常用手段。顾名思义,PCA 能从冗余特征中提取主要成分,在不太损失模型质量的情况下,提升了模型训练速度。
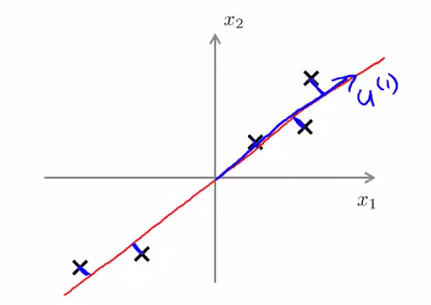
如上图所示,我们将样本到红色向量的距离称作是投影误差(Projection Error)。以二维投影到一维为例,PCA 就是要找寻一条直线,使得各个特征的投影误差足够小,这样才能尽可能的保留原特征具有的信息。
假设我们要将特征从 n 维度降到 k 维:PCA 首先找寻 k 个 n 维向量,然后将特征投影到这些向量构成的 k 维空间,并保证投影误差足够小。下图中中,为了将特征维度从三维降低到二位,PCA 就会先找寻两个三维向量 $\mu^{(1)},\mu^{(2)}$ ,二者构成了一个二维平面,然后将原来的三维特征投影到该二维平面上:
1. 区别
PCA 和 线性回归的区别是:
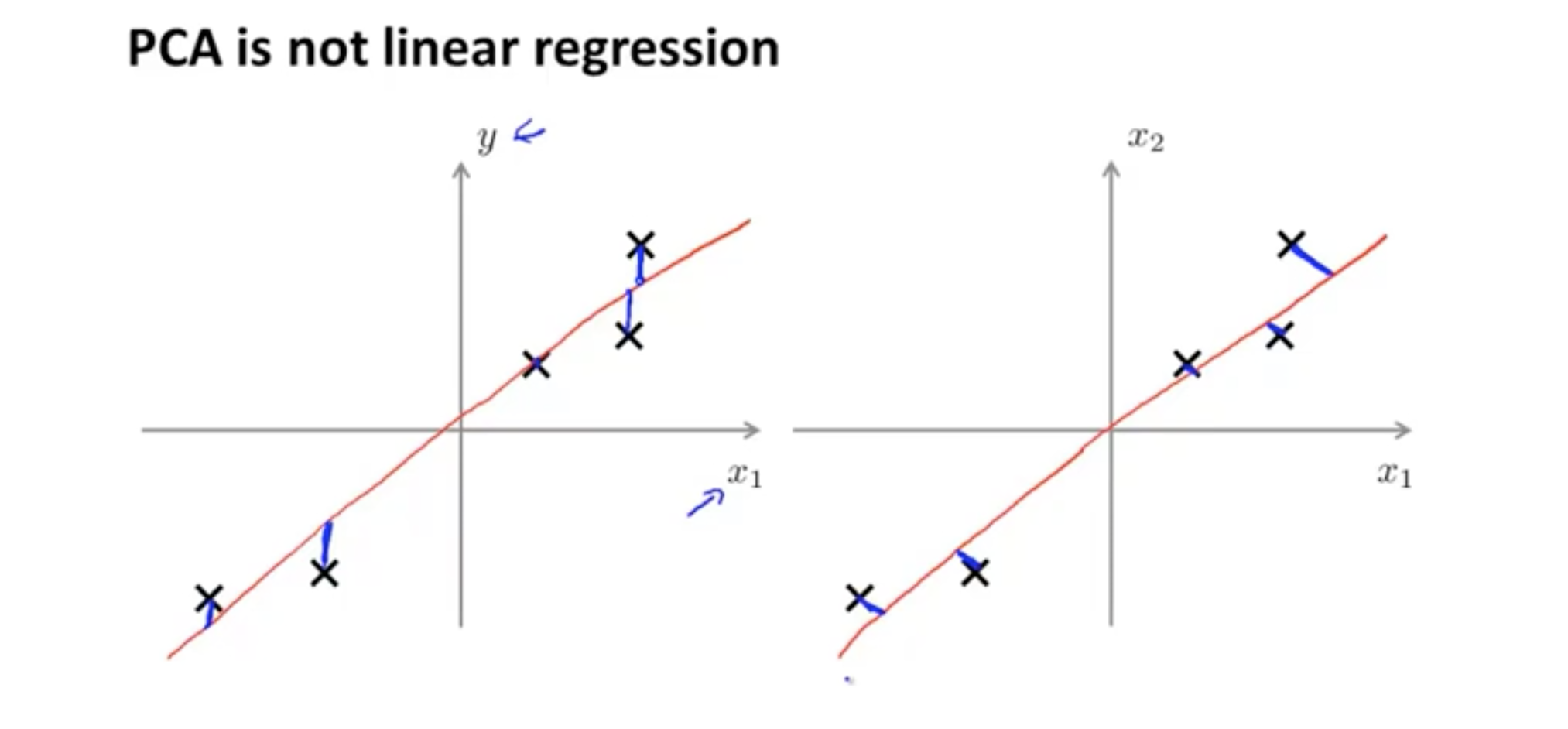
线性回归找的是垂直于 X 轴距离最小值,PCA 找的是投影垂直距离最小值。
线性回归目的是想通过 x 预测 y,但是 PCA 的目的是为了找一个降维的面,没有什么特殊的 y,代表降维的面的向量 $x_1$、$x_2$、$x_3$、$x_n$ 都是同等地位的。
2. 算法流程
假定我们需要将特征维度从 n 维降到 k 维。则 PCA 的执行流程如下:
特征标准化,平衡各个特征尺度:
$$x^{(i)}_j=\frac{x^{(i)}_j-\mu_j}{s_j}$$
$\mu_j$ 为特征 j 的均值,sj 为特征 j 的标准差。
计算协方差矩阵 $\Sigma $ :
$$\Sigma =\frac{1}{m}\sum_{i=1}{m}(x^{(i)})(x^{(i)})^T=\frac{1}{m} \cdot X^TX$$
通过奇异值分解(SVD),求取 $\Sigma $ 的特征向量(eigenvectors):
$$(U,S,V^T)=SVD(\Sigma )$$
从 U 中取出前 k 个左奇异向量,构成一个约减矩阵 Ureduce :
$$U_{reduce}=(\mu^{(1)},\mu^{(2)},\cdots,\mu^{(k)})$$
计算新的特征向量: $z^{(i)}$
$$z^{(i)}=U^{T}_{reduce} \cdot x^{(i)}$$
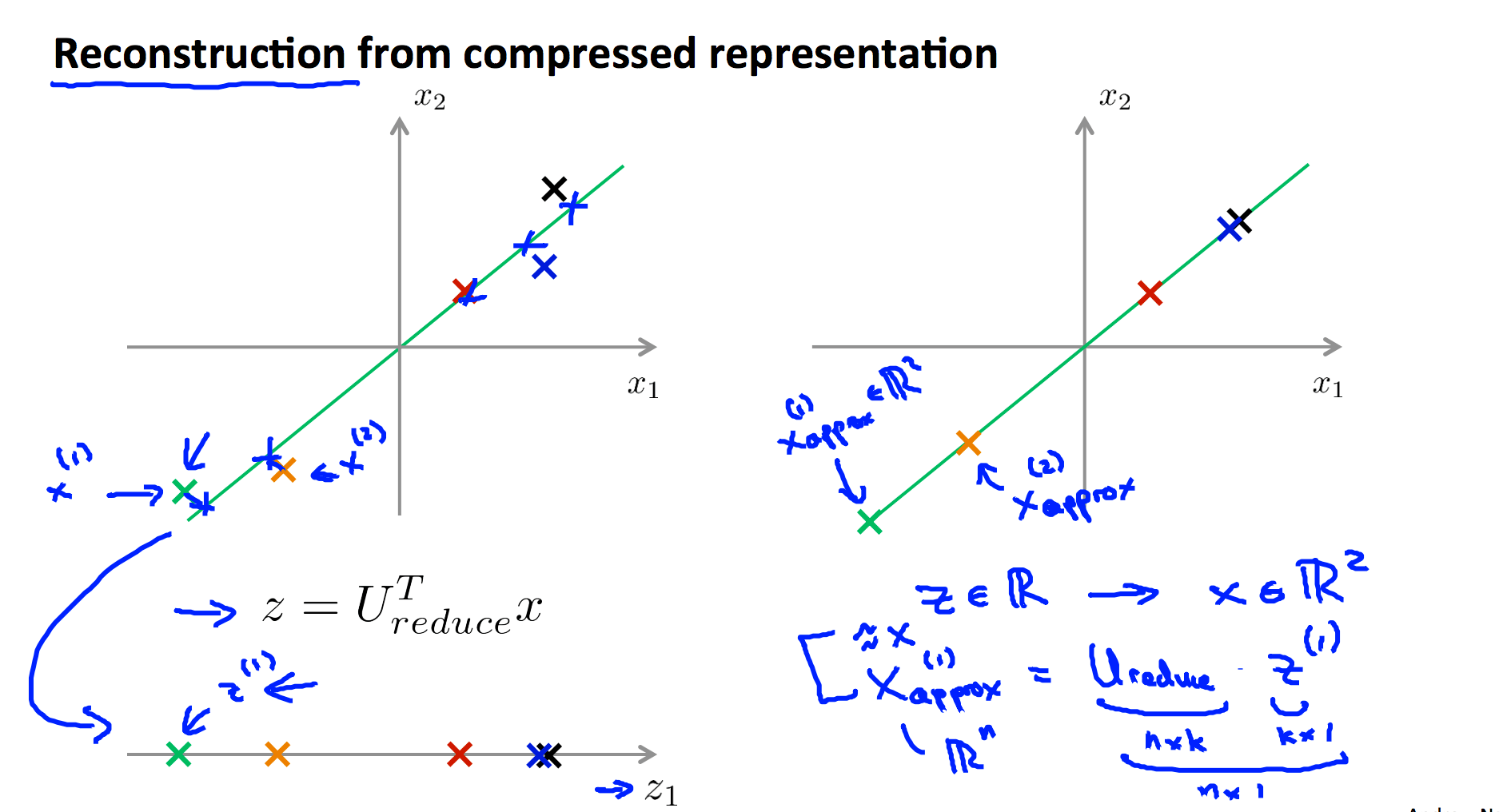
3. 特征还原
因为 PCA 仅保留了特征的主成分,所以 PCA 是一种有损的压缩方式,假定我们获得新特征向量为:
$$z=U^T_{reduce}x$$
那么,还原后的特征 $x_{approx}$ 为:
$$x_{approx}=U_{reduce}z$$
4. 降维多少才合适?
从 PCA 的执行流程中,我们知道,需要为 PCA 指定目的维度 k 。如果降维不多,则性能提升不大;如果目标维度太小,则又丢失了许多信息。通常,使用如下的流程的来评估 k 值选取优异:
求各样本的投影均方误差:
求数据的总变差:
评估下式是否成立:
其中, $\epsilon $ 的取值可以为 0.01,0.05,0.10,⋯0.01,0.05,0.10,⋯ ,假设 $\epsilon = 0.01 $ ,我们就说“特征间 99% 的差异性得到保留”。
5. 不要提前优化
由于 PCA 减小了特征维度,因而也有可能带来过拟合的问题。PCA 不是必须的,在机器学习中,一定谨记不要提前优化,只有当算法运行效率不尽如如人意时,再考虑使用 PCA 或者其他特征降维手段来提升训练速度。
当你在保留99% 或者95% 或者其它百分比的方差时 结果表明 就只使用正则化将会给你 一种避免过拟合 绝对好的方法 ,同时正则化 效果也会比 PCA 更好 因为当你使用线性回归或者逻辑回归 或其他的方法 配合正则化时 这个最小化问题 实际就变成了 y 值是什么 才不至于 将有用的信息舍弃掉 然而 PCA 不需要使用到 这些标签 更容易将有价值信息舍弃 总之 使用 PCA 的目的是 加速 学习算法的时候是好的 但是用它来避免过拟合 却并不是一个好的 PCA 应用 我们使用正则化的方法来代替 PCA 方法是很多人建议的 。
PCA 用来解决过拟合的问题是错误的选择,请考虑正则化的方式解决过拟合的问题。
你的学习算法 收敛地非常缓慢 占用内存 或者硬盘空间非常大 所以你想来压缩 数据 只有当你的$x^{(i)}$ 效果不好 只有当你有证据或者 充足的理由来确定 $x^{(i)}$ 效果不好的时候 那么就考虑用PCA来进行压缩数据 。
PCA通常都是 被用来 压缩数据的 以减少内存使用 或硬盘空间占用 或者用来可视化数据
三. Principal Component Analysis 测试
1. Question 1
Consider the following 2D dataset:
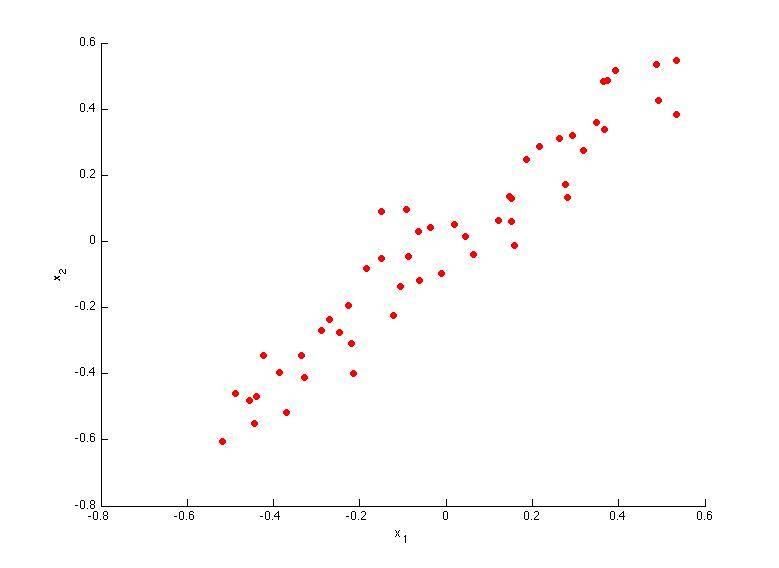
Which of the following figures correspond to possible values that PCA may return for u(1) (the first eigenvector / first principal component)? Check all that apply (you may have to check more than one figure).
A. 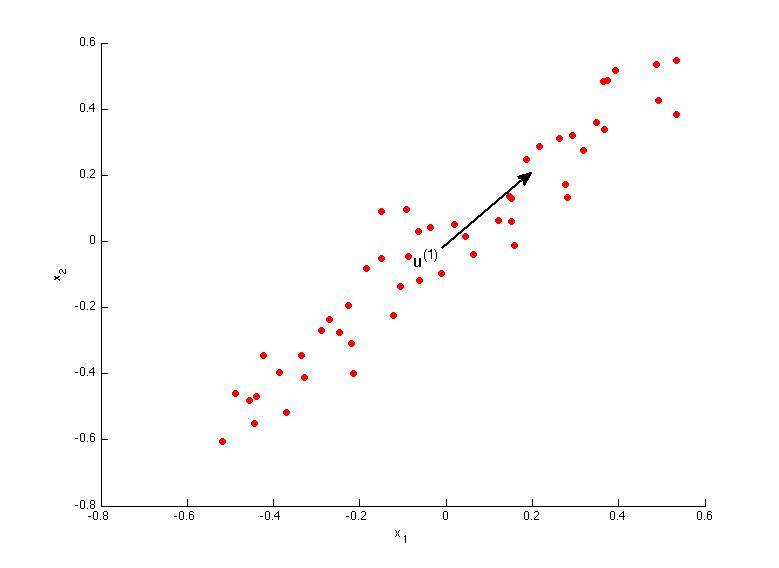
B. 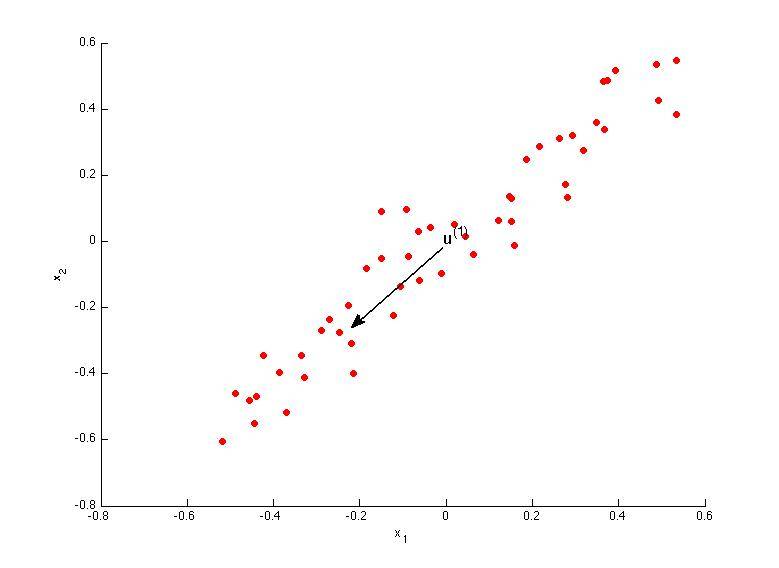
C. 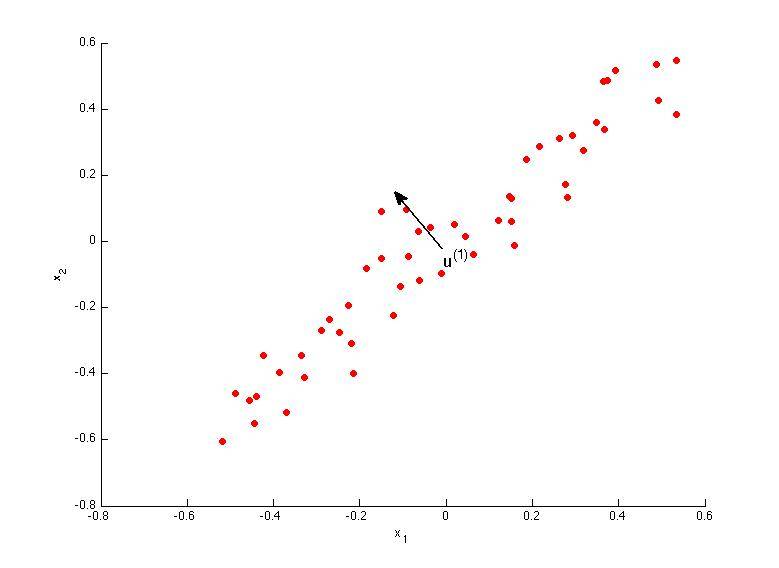
D. 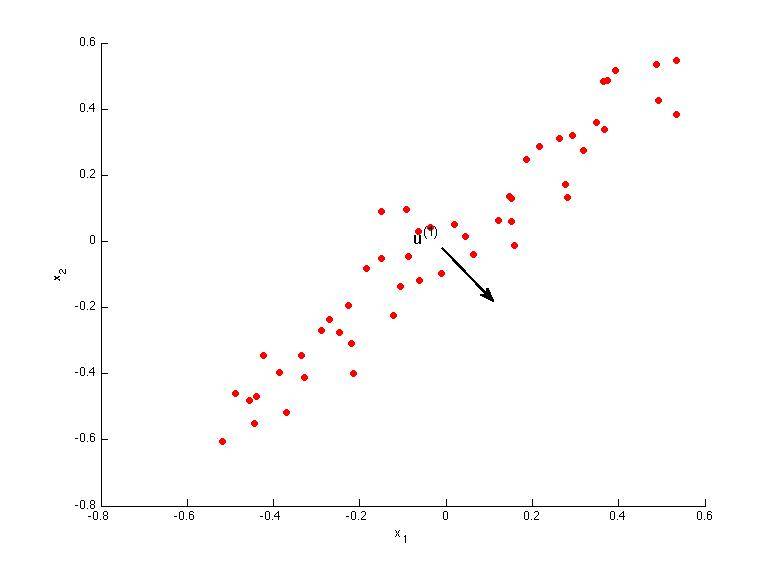
解答:A、B
2. Question 2
Which of the following is a reasonable way to select the number of principal components k?
(Recall that n is the dimensionality of the input data and m is the number of input examples.)
A. Choose k to be the smallest value so that at least 1% of the variance is retained.
B. Choose k to be the smallest value so that at least 99% of the variance is retained.
C. Choose the value of k that minimizes the approximation error $\frac{1}{m}\sum^{m}_{i=1}\left \| x^{(i)} - x_{approx}^{(i)} \right \|^{2}$.
D. Choose k to be 99% of n (i.e., k=0.99∗n, rounded to the nearest integer).
解答: B
3. Question 3
Suppose someone tells you that they ran PCA in such a way that "95% of the variance was retained." What is an equivalent statement to this?
A.
B.
C.
D.
解答: C
4. Question 4
Which of the following statements are true? Check all that apply.
A. If the input features are on very different scales, it is a good idea to perform feature scaling before applying PCA.
B. Feature scaling is not useful for PCA, since the eigenvector calculation (such as using Octave's svd(Sigma) routine) takes care of this automatically.
C. Given an input $x \in \mathbb{R}^{n}$, PCA compresses it to a lower-dimensional vector $z \in \mathbb{R}^{k}$.
D. PCA can be used only to reduce the dimensionality of data by 1 (such as 3D to 2D, or 2D to 1D).
解答:A、C
5. Question 5
Which of the following are recommended applications of PCA? Select all that apply.
A. To get more features to feed into a learning algorithm.
B. Data compression: Reduce the dimension of your data, so that it takes up less memory / disk space.
C. Data visualization: Reduce data to 2D (or 3D) so that it can be plotted.
D. Data compression: Reduce the dimension of your input data $x^{(i)}$, which will be used in a supervised learning algorithm (i.e., use PCA so that your supervised learning algorithm runs faster).
解答:B、C
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub