一. Photo OCR
1. Problem Description and Pipeline 问题描述
图像文字识别应用所作的事是,从一张给定的图片中识别文字。这比从一份扫描文档中识别文字要复杂的多。

为了完成这样的工作,需要采取如下步骤:
文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
字符切分(Character segmentation)——将文字分割成一个个单一的字符
字符分类(Character classification)——确定每一个字符是什么
可以用任务流程图来表达这个问题,每一项任务可以由一个单独的小队来负责解决:

2. Sliding Windows 滑动窗口
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
一旦完成后,我们按比例放大剪裁的区域,再以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。

滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。下图中绿色的区域是经过这些步骤后被认为是文字的区域,而红色的区域是被忽略的。
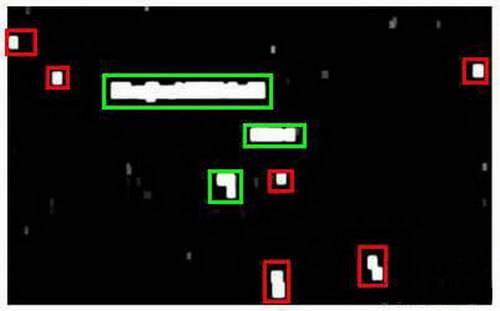
以上便是文字侦测阶段。 下一步是训练一个模型来完成将文字分割成一个个字符的任务,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。
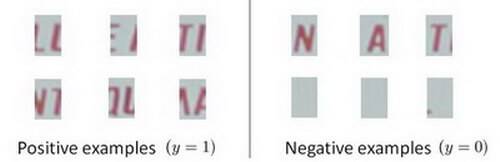
模型训练完后,我们仍然是使用滑动窗口技术来进行字符识别。
以上便是字符切分阶段。 最后一个阶段是字符分类阶段,利用神经网络、支持向量机或者逻辑回归算法训练一个分类器即可。
3. Getting Lots of Data and Artificial Data 人工合成数据
在字符识别阶段,为了更好的完成分类识别任务,我们就需要给系统提供尽可能多的训练图像,如果我们手头上拥有的图像不多,就需要人工合成更多的数据。例如,我们可以收集不同的字体,并为每种字体的每个字符加上随机背景,这样就可以人工扩展大量的字符图像:

另外,也可以通过扭曲字符形状来合成新数据,这也会帮助机器更好地处理发生过形态变化的图像:
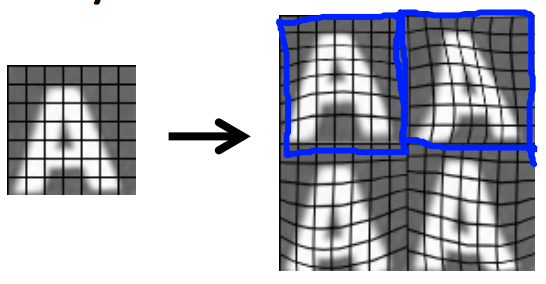
但是,为数据加上随机噪声一般不会提升模型训练质量:

4. ceiling analysis 上限分析
在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
回到我们的文字识别应用中,我们的流程图如下:
所谓上限分析,就是我们假定某个组件及其前面组件的精度都达到了 100%,即该组件完美地完成了任务,达到了上限,那么此时整个系统的精度能提升多少 。例如,假定整个系统的精度是 72%,我们令文本检测的精度是 100%(比如人工利用 PS 来定位图片中的文本框),此时,整个系统的精度能提升到 89%。即,如果我们付出足够多的精力来优化文本检测,那么理想情况下,能将系统的精度提升 17%:
| 组件 | 流水线精度 | 精度提升 |
|---|---|---|
| 整个系统 | 72% | -- |
| 文本检测 | 89% | 17% |
| 字符分割 | 90% | 1% |
| 字符识别 | 100% | 10% |
完成上限分析后,我们得到上面的表格,可以看出,最值得花费精力的步骤是文本检测,最不值得花费精力的是字符分割,即便我们完成了 100% 的分割,最多也就对系统提升 1%。
二. Application: Photo OCR 测试
1. Question 1
Suppose you are running a sliding window detector to find text in images. Your input images are 1000x1000 pixels. You will run your sliding windows detector at two scales, 10x10 and 20x20 (i.e., you will run your classifier on lots of 10x10 patches to decide if they contain text or not; and also on lots of 20x20 patches), and you will "step" your detector by 2 pixels each time. About how many times will you end up running your classifier on a single 1000x1000 test set image?
A. 500,000
B. 100,000
C. 250,000
D. 1,000,000
解答:A
$2*500*500 = 500,000$
2. Question 2
Suppose that you just joined a product team that has been developing a machine learning application, using m=1,000
training examples. You discover that you have the option of hiring additional personnel to help collect and label data. You estimate that you would have to pay each of the labellers ¥10 per hour, and that each labeller can label 4 examples per minute. About how much will it cost to hire labellers to label 10,000 new training examples?
A. ¥600
B. ¥400
C. ¥10,000
D. ¥250
解答:B
一个人一个小时可以贴$4*60 = 240 $个标签。所以需要 $10000 / 240 \approx 40$个小时,一个小时 ¥10 ,所以总共 $10*40 = 400$。
3. Question 3
What are the benefits of performing a ceiling analysis? Check all that apply.
A. It can help indicate that certain components of a system might not be worth a significant amount of work improving, because even if it had perfect performance its impact on the overall system may be small.
B. If we have a low-performing component, the ceiling analysis can tell us if that component has a high bias problem or a high variance problem.
C. A ceiling analysis helps us to decide what is the most promising learning algorithm (e.g., logistic regression vs. a neural network vs. an SVM) to apply to a specific component of a machine learning pipeline.
D. It gives us information about which components, if improved, are most likely to have a significant impact on the performance of the final system.
解答:A、D
4. Question 4
Suppose you are building an object classifier, that takes as input an image, and recognizes that image as either containing a car (y=1) or not (y=0). For example, here are a positive example and a negative example:

After carefully analyzing the performance of your algorithm, you conclude that you need more positive (y=1) training examples. Which of the following might be a good way to get additional positive examples?
A. Apply translations, distortions, and rotations to the images already in your training set.
B. Select two car images and average them to make a third example.
C. Take a few images from your training set, and add random, gaussian noise to every pixel.
D. Make two copies of each image in the training set; this immediately doubles your training set size.
解答:A
5. Question 5
Suppose you have a PhotoOCR system, where you have the following pipeline:

You have decided to perform a ceiling analysis on this system, and find the following:

Which of the following statements are true?
A. The potential benefit to having a significantly improved text detection system is small, and thus it may not be worth significant effort trying to improve it.
B. If we conclude that the character recognition's errors are mostly due to the character recognition system having high variance, then it may be worth significant effort obtaining additional training data for character recognition.
C. We should dedicate significant effort to collecting additional training data for the text detection system.
D. The most promising component to work on is the text detection system, since it has the lowest performance (72%) and thus the biggest potential gain.
解答: A、B
文字识别提高的效果确实不明显,没必要给其提供大量的数据来源,反而是分类器回归处如果是高方差就需要大数据来喂养。故 C、D 错误
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub



