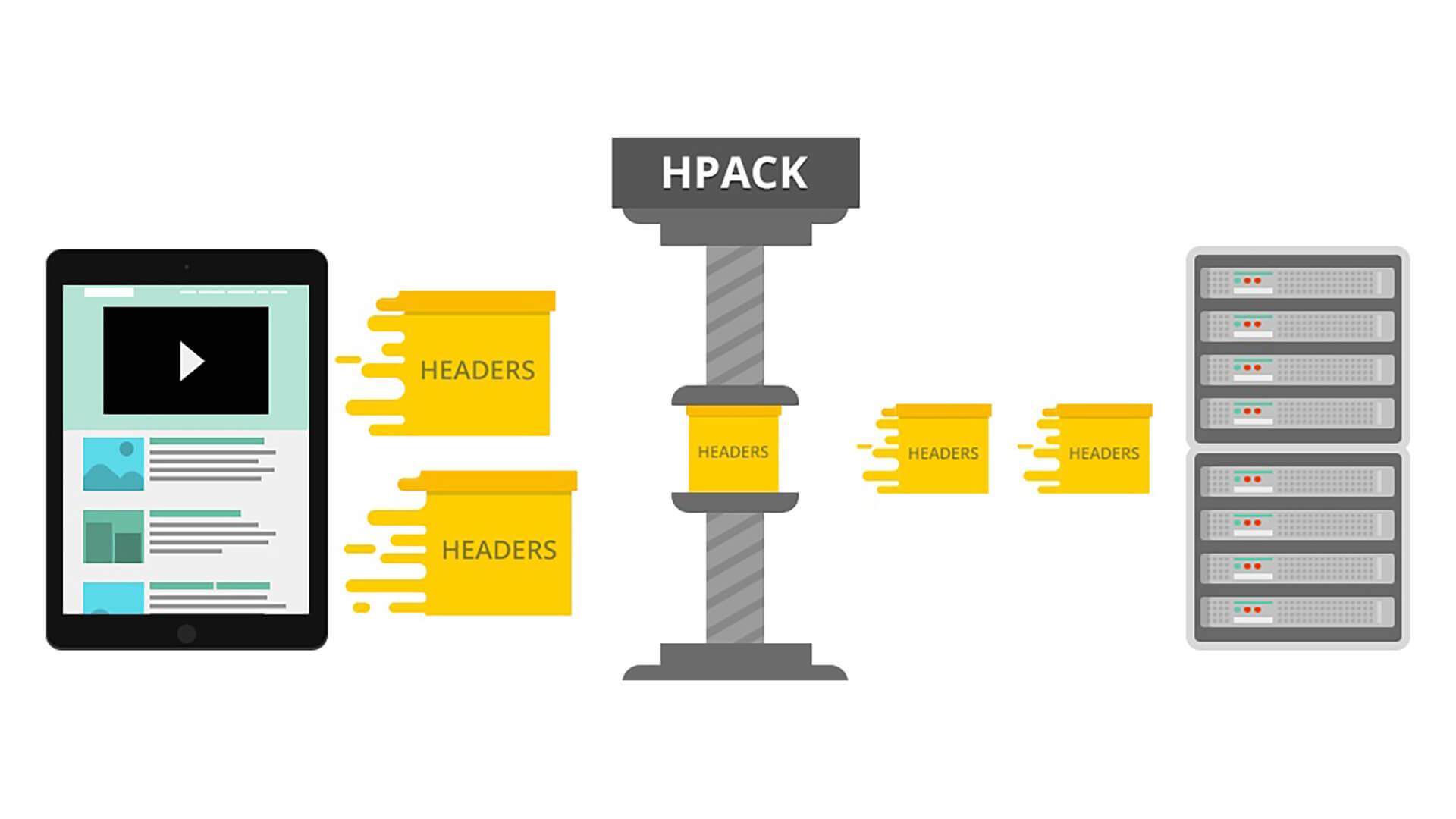
一. 简介
在 HTTP/1.1(请参阅[RFC7230])中,header 字段未被压缩。随着网页内的请求数增长到需要数十到数百个请求的时候,这些请求中的冗余 header 字段不必要地消耗了带宽,从而显着增加了延迟。
SPDY [SPDY] 最初通过使用 DEFLATE [DEFLATE] 格式压缩 header 字段来解决此冗余问题,事实证明,这种格式非常有效地表示了冗余 header 字段。但是,这种方法暴露了安全风险,如 CRIME(轻松实现压缩率信息泄漏)攻击所证明的安全风险(请参阅 [CRIME])。
本规范定义了 HPACK,这是一种新的压缩方法,它消除了多余的 header 字段,将漏洞限制到已知的安全攻击,并且在受限的环境中具有有限的内存需求。第 7 节介绍了 HPACK 的潜在安全问题。
HPACK 格式特意被设计成简单且不灵活的形式。两种特性都降低了由于实现错误而引起的互操作性或安全性问题的风险。没有定义扩展机制;只能通过定义完整的替换来更改格式。
1. 总览

本规范中定义的格式将 header 字段列表视为 name-value 对的有序集合,其中可以包括重复的对。名称和值被认为是八位字节的不透明序列,并且 header 字段的顺序在压缩和解压缩后保持不变。
header 字段表将 header 字段映射到索引值,从而得到编码。这些 header 字段表可以在编码或解码新 header 字段时进行增量更新。
在编码形式中,header 字段以字面形式表示或作为对 header 字段表中的一个 header 字段的引用。因此,可以使用引用和字面值的混合来编码 header 字段的列表。
字面值可以直接编码,也可以使用静态霍夫曼编码(最高压缩比 8:5)。
编码器负责决定将哪些 header 字段作为新条目插入 header 字段表中。解码器执行对编码器指定的 header 字段表的修改,从而在此过程中重建 header 字段的列表。这使解码器保持简单并可以与多种编码器互操作。
附录C 中提供了使用这些不同的机制表示 header 字段的示例。
注:在 HTTP/2 中,请求和响应标头字段的定义保持不变,仅有一些微小的差异:所有标头字段名称均为小写,请求行现在拆分成各个 :method、:scheme、:authority 和 :path 伪标头字段。
2. 约定
本文档中的关键字 “必须”,“不得”,“必须”,“应”,“应禁止”,“应”,“不应”,“建议”,“可以”和“可选”是 RFC 2119 [RFC2119] 中定义的。
所有数值均以网络字节顺序排列。 除非另有说明,否则值是无符号的。适当时以十进制或十六进制提供字面值。
3. 术语
本文使用以下术语:
Header Field:一个名称/值 name-value 对。名称和值都被视为八位字节的不透明序列。
Dynamic Table:动态表(请参阅第 2.3.2 节)是将存储的 header 字段与索引值相关联的表。该表是动态的,并且特定于编码或解码上下文。
Static Table:静态表(请参阅第 2.3.1 节)是将经常出现的 header 字段与索引值静态关联的表。该表是有序的,只读的,始终可访问的,并且可以在所有编码或解码上下文之间共享。
Header List:header 列表是 header 字段的有序集合,这些 header 字段经过联合编码,可以包含重复的 header 字段。HTTP/2 header 块中包含的 header 字段的完整列表是 header 列表。
Header Field Representation:header 字段可以编码形式表示为字面或索引(请参见第 2.4 节)。
Header Block:header 字段表示形式的有序列表,解码后会产生完整的 header 列表。
二. 压缩过程概述
本规范未描述编码器的具体算法。相反,它精确定义了解码器的预期工作方式,从而允许编码器产生此定义允许的任何编码。
1. Header List Ordering
HPACK 保留 header 列表内 header 字段的顺序。编码器必须根据其在原始 header 列表中的顺序对 header 块中的 header 字段表示进行排序。解码器必须根据其在 header 块中的顺序对已解码 header 列表中的 header 字段进行排序。
2. Encoding and Decoding Contexts
为了解压缩 header 块,解码器只需要维护一个动态表(参见第 2.3.2 节)作为解码上下文。不需要其他动态状态。
当用于双向通信时(例如在 HTT P中),由端点维护的编码和解码动态表是完全独立的,即请求和响应动态表是分开的。
3. Indexing Tables
HPACK 使用两个表将 header 字段与索引相关联。静态表(请参阅第 2.3.1 节)是预定义的,并包含公共 header 字段(其中大多数带有空值)。动态表(请参阅第 2.3.2 节)是动态的,编码器可以使用它来索引已编码 header 列表中重复的 header 字段。
这两个表被合并到一个用于定义索引值的地址空间中(请参阅第 2.3.3 节)。
(1) 静态表
静态表由 header 字段的预定义静态列表组成。其条目在附录 A 中定义。
(2) 动态表
动态表包含以先进先出的顺序维护的 header 字段列表。动态表中的第一个条目和最新条目在最低索引处,而动态表的最旧条目在最高索引处。
动态表最初是空的。当每个 header 块被解压缩时,将添加条目。动态表可以包含重复的条目(即,具有相同名称和相同值的条目)。因此,解码器不得将重复的条目视为错误。
编码器决定如何更新动态表,因此可以控制动态表使用多少内存。为了限制解码器的存储需求,动态表的 size 受到严格限制(请参见第 4.2 节)。
解码器在处理 header 字段表示列表时更新动态表(请参见第 3.2 节)。
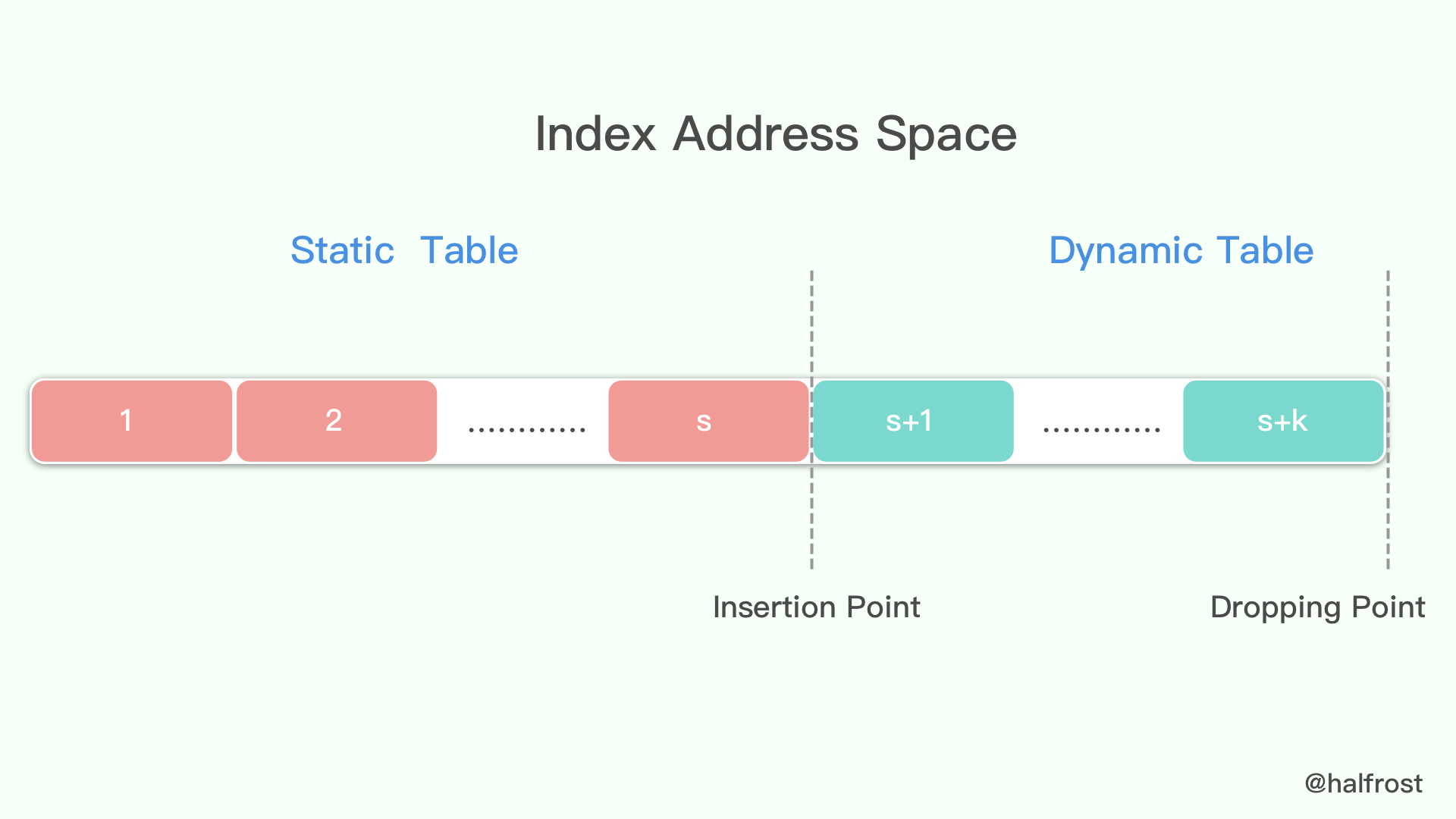
(3) 索引地址空间
静态表和动态表被组合到单个索引地址空间中。
在 1 和静态表的长度(包括在内)之间的索引是指静态表中的元素(请参阅第 2.3.1 节)。
严格大于静态表长度的索引是指动态表中的元素(请参见第 2.3.2 节)。 减去静态表的长度即可找到动态表的索引。
严格大于两个表的长度之和的索引必须视为解码错误。
对于 s 的静态表 size 和 k 的动态表 size ,下图显示了整个有效索引地址空间
4. Header Field Representation
编码的 header 字段可以表示为索引或字面。
有索引的表示形式定义了一个 header 字段,作为对静态表或动态表中条目的引用(请参见第 6.1 节);字面表示形式通过指定其 name 和 value 来定义 header 字段。header 字段 name 可以用字面形式表示,也可以作为对静态表或动态表中条目的引用。header 字段 value 按字面表示。定义了三种不同的字面表示形式:
-
在动态表的开头添加 header 字段作为新条目的字面表示形式(请参见第 6.2.1 节)。
-
不将 header 字段添加到动态表的字面表示形式(请参见第 6.2.2 节)。
-
不将 header 字段添加到动态表的字面表示形式,另外规定该 header 字段始终使用字面表示形式,尤其是在由中介程序重新编码时(请参阅第 6.2.3 节)。此表示旨在保护 header 字段值,这些 header 字段值通过压缩以后就不会受到威胁(有关更多详细信息,请参见第 7.1.3 节)。
为了保护敏感的 header 字段值(请参阅第 7.1 节),可以从安全考虑出发选择这些字面表示形式之一。
header 字段 name 或 header 字段 value 的字面表示可以直接或使用静态霍夫曼代码对八位字节序列进行编码(请参见第 5.2 节)
三. header 块的解码
1. Header Block Processing
解码器顺序处理 header 块以重建原始 header 列表。
header 块是 header 字段表示形式的串联。第 6 节中介绍了不同的可能的 header 字段表示形式。
一旦 header 字段被解码并添加到重建的 header 列表中,就不能删除 header 字段。添加到 header 列表的 header 字段可以安全地传递到应用程序。
通过将结果 header 字段传递给应用程序,除了动态表所需的内存外,还需要使用最少的临时内存来实现解码器。
2. Header Field Representation Processing
在本节中定义了对 header 块进行处理以获得 header 列表的过程。为了确保解码将成功产生 header 列表,解码器必须遵守以下规则。
header 块中包含的所有 header 字段表示形式将按照它们出现的顺序进行处理,如下所示。有关各种 header 字段表示形式的格式的详细信息以及一些其他处理指令,请参见第 6 节。
_indexed representation_需要执行以下操作:
- 与静态表或动态表中被引用条目相对应的 header 字段被附加到解码后的 header 列表中。
动态表中未添加的 “_literal representation_” 需要执行以下操作:
- header 字段被附加到解码的 header 列表中。
在动态表中添加了 “_literal representation_” 需要执行以下操作:
- header 字段被附加到解码的 header 列表中。
- header 字段插入在动态表的开头。这种插入可能导致驱逐动态表中的先前条目(请参见第 4.4 节)。
四. 动态表管理

为了限制解码器端的存储要求,动态表的 size 受到限制。
动态字典上下文有关,需要为每个 HTTP/2 连接维护不同的字典。
1. Calculating Table Size
动态表的 size 是其表项 size 的总和。条目的 size 是其 name 的长度(以八位字节为单位)(如第 5.2 节中所定义),value 的长度(以八位字节为单位)和 32 的总和。条目的 size 是使用其 name 和 value 的长度来计算的,而无需应用任何霍夫曼编码。
注意:额外的 32 个八位字节说明了与条目相关的估计开销。例如,使用两个 64 位指针引用条目的 name 和 value 以及使用两个 64 位整数来计数对该 name 和 value 的引用次数的条目结构,该数据结构将具有 32 个八位字节的开销。(64*2*2/8=32 字节)
2. Maximum Table Size
使用 HPACK 的协议确定允许编码器用于动态表的最大 size 。在 HTTP/2 中,此值由 SETTINGS_HEADER_TABLE_SIZE 设置来确定(请参见[HTTP2]的 6.5.2 节)。
编码器可以选择使用小于此最大 size 的容量(请参阅第 6.3 节),但是所选 size 必须保持小于或等于协议设置的最大容量。
动态表最大 size 的变化是因为动态表 size 的更新引起的(请参见第 6.3 节)。动态表 size 更新必须在更改动态表 size 之后的第一个 header 块的开头进行。在 HTTP/2 中,这遵循 settings 的确认(请参阅 [HTTP2]的 6.5.3 节)。
在传输两个 header 块之间,可能会发生多次最大表 size 的更新。如果在此间隔中,这个 size 更改一次以上的话,那么就必须在动态表 size 更新中,用信号通知在该间隔中出现的,最小的最大表 size 。一定会发出最终最大 size 的信号,从而导致最多两个动态表 size 的更新。这样可确保解码器能够基于动态表 size 的减小执行逐出(请参见第 4.3 节)。
使用此机制通过将最大 size 设置为 0,从动态表中完全清除条目,然后可以将其恢复。
HTTP/2 提倡使用尽可能少的连接数,头部压缩是其中一个重要的原因:在同一个连接上产生的请求和响应越多,动态字典累积的越全,头部压缩的效果就越好。
3. Entry Eviction When Dynamic Table Size Changes
只要减小了动态表的最大 size,就会从动态表的末尾逐出条目,直到动态表的 size 小于或等于最大 size 为止。
4. Entry Eviction When Adding New Entries
在将新条目添加到动态表之前,将从动态表的末尾逐出条目,直到动态表的 size 小于或等于(最大 size -新条目大小)或直到表为空。
如果新条目的 size 小于或等于最大 size,则会将该条目添加到表中。 尝试添加大于最大 size 的条目不是错误;尝试添加大于最大 size 的条目会导致该表清空所有现有条目,并导致表为空。
新条目可以引用动态表中条目 A 的 name,当将该新条目添加到动态表中时,该条目 A 将被逐出。请注意,如果在插入新条目之前从动态表中删除了引用条目,则应避免删除引用 name。
五. 基本类型表示
HPACK 编码使用两种原始类型:无符号的可变长度整数和八位字节串。
1. Integer Representation
整数用于表示 name 索引,header 字段索引或字符串长度。整数表示可以在八位字节内的任何位置开始。为了优化处理,整数表示总是在八位字节的末尾结束。
整数分为两部分:填充当前八位字节的前缀和可选的八位字节列表,如果整数值不适合该前缀,则使用这些可选的八位字节。前缀的位数(称为 N)是整数表示的参数。
如果整数值足够小,即严格小于 2^N-1,则将其编码在 N 位前缀中。
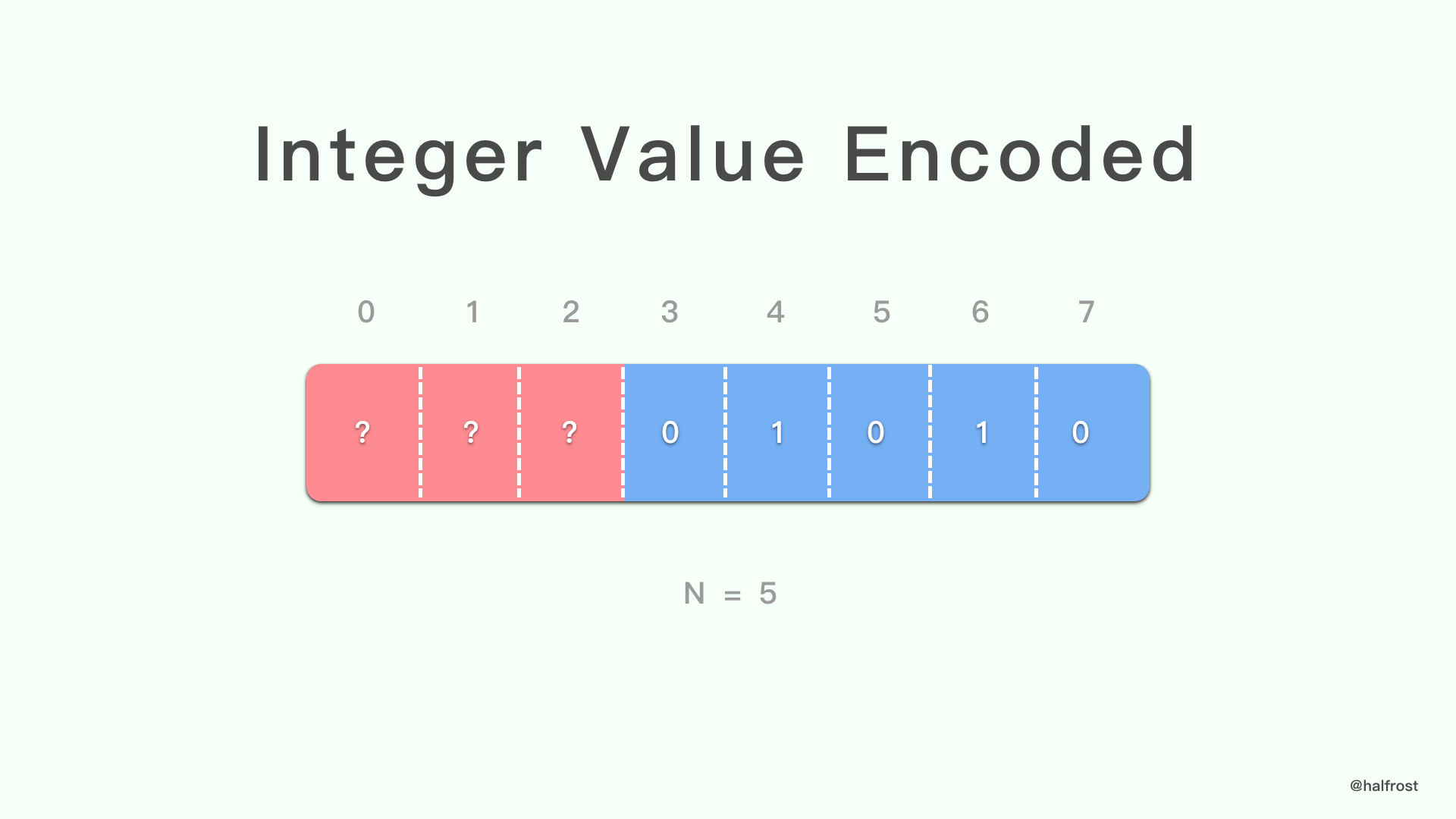
上图的例子中,N = 5,所以能表示的最大的整数是 2^5-1 = 31
如果整数数值大于 2^N-1,则将前缀的所有位设置为 1,并使用一个或多个八位字节的列表对减少了 2^N-1 的值进行编码。每个八位字节的最高有效位用作连续标志:除了列表中的最后一个八位字节,其值均设置为 1。八位字节的其余位用于对减小的值进行编码。
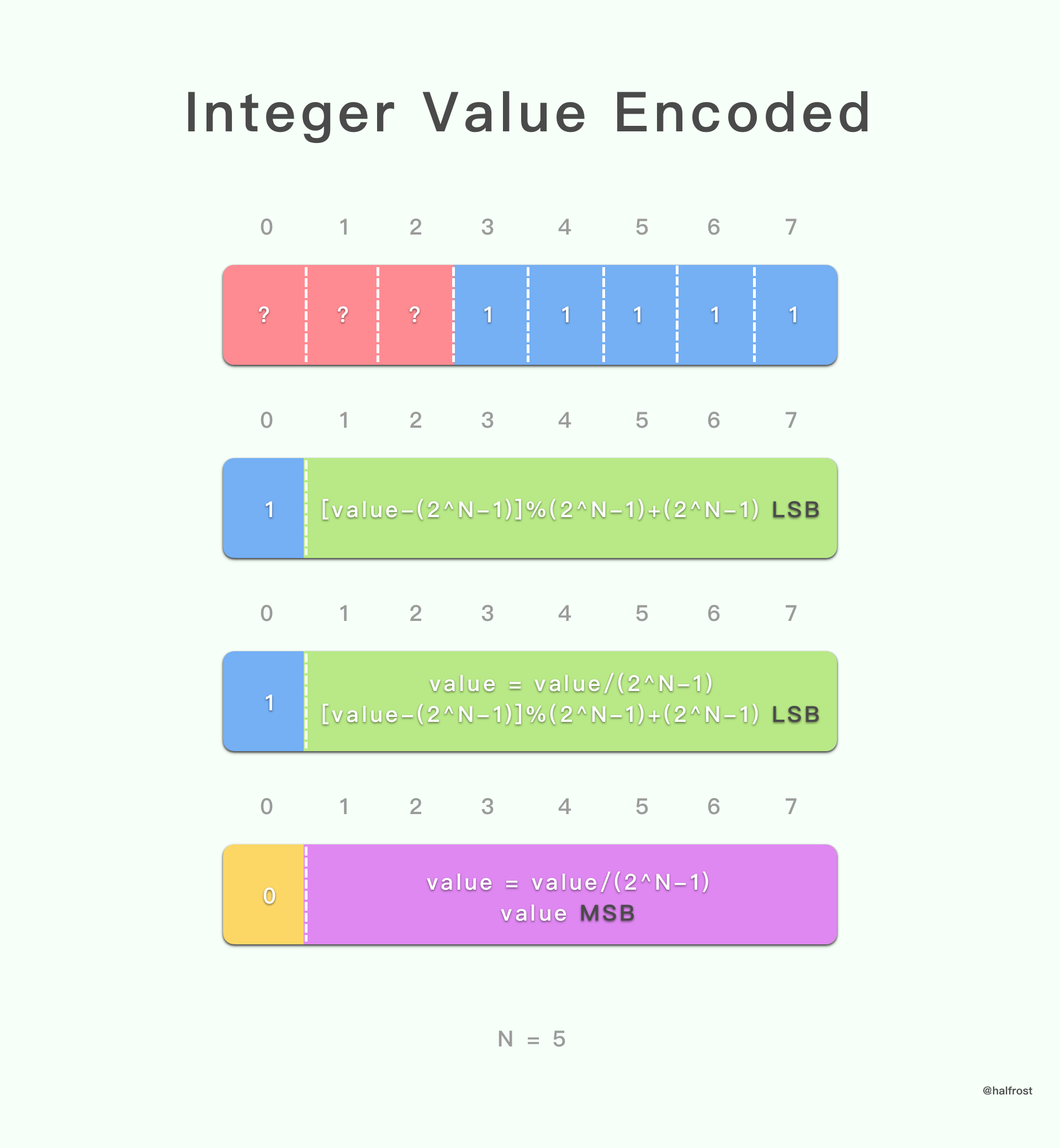
从八位字节列表中解码整数值是通过反转八位字节在列表中的顺序开始的。 然后,对于每个八位字节,将其最高有效位删除。八位字节的其余位被级联起来,结果值增加 2^N-1 以获得整数值。
前缀 size N 始终在 1 到 8 位之间。从八位字节边界开始的整数将具有 8 位前缀。
表示整数 I 的伪代码如下:
if I < 2^N - 1, encode I on N bits
else
encode (2^N - 1) on N bits
I = I - (2^N - 1)
while I >= 128
encode (I % 128 + 128) on 8 bits
I = I / 128
encode I on 8 bits
用于解码整数 I 的伪代码如下:
decode I from the next N bits
if I < 2^N - 1, return I
else
M = 0
repeat
B = next octet
I = I + (B & 127) * 2^M
M = M + 7
while B & 128 == 128
return I
附录 C.1 中提供了说明整数编码的示例。
整数表示形式允许使用不确定大小的值。编码器也可能发送大量的零值,这可能浪费八位字节,并可能使整数值溢出。超出实现限制的整数编码(值或八位字节长度)必须视为解码错误。基于实现方的约束,可以为整数的每种不同用途设置不同的限制。
2. String Literal Representation
header 字段 name 和 header 字段 value 可以表示为字符串字面量。可以通过直接编码字符串字面的八位字节或使用霍夫曼代码将字符串字面编码为八位字节序列(请参见[HUFFMAN])
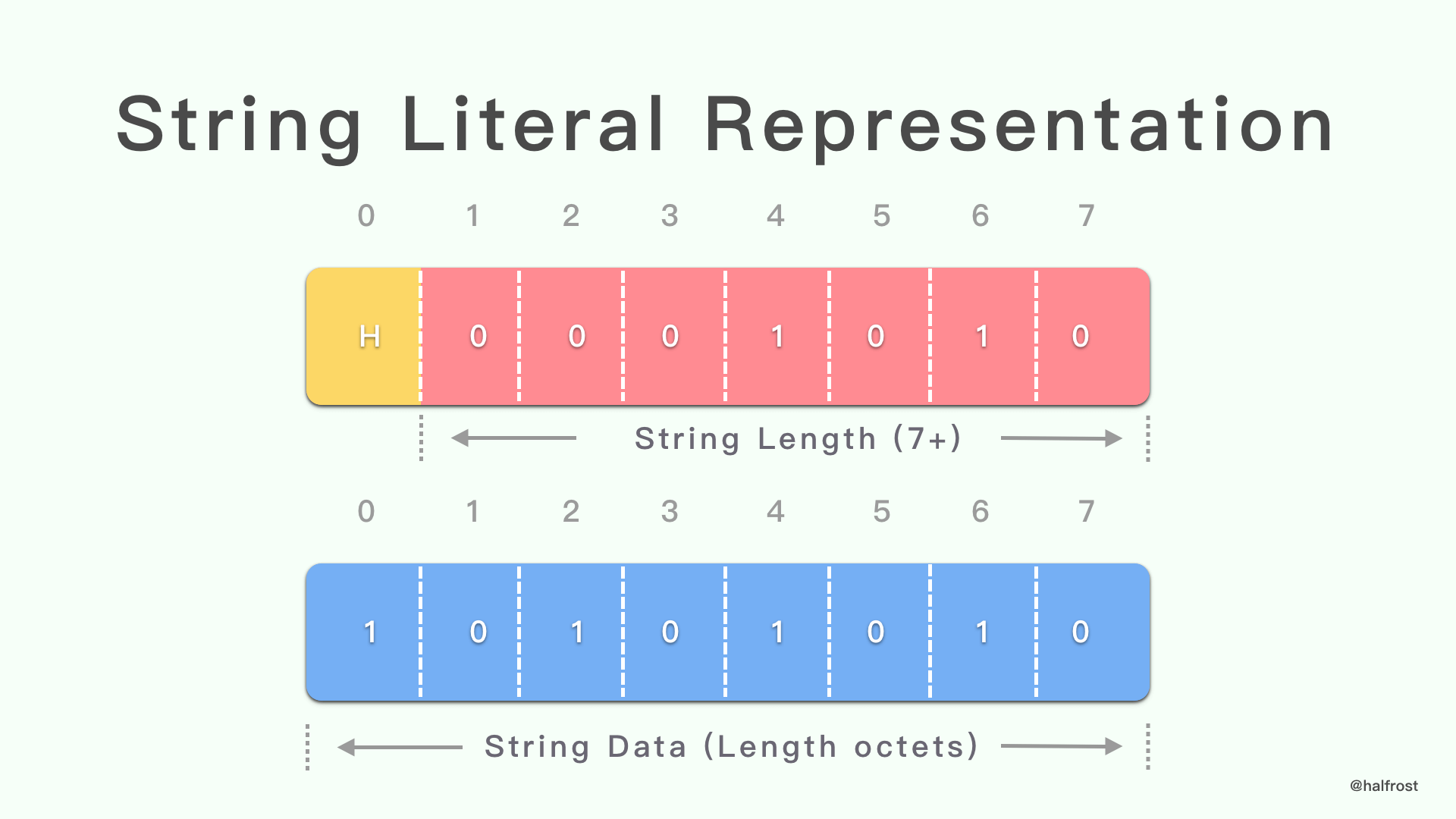
字符串字面表示形式包含以下字段:
-
H:
一位标志 H,指示字符串的八位字节是否经过霍夫曼编码。 -
String Length:
用于编码字符串字面的八位字节数,编码为带有 7 位前缀的整数(请参阅第 5.1 节)。 -
String Data:
字符串字面的编码数据。如果 H 为'0',则编码后的数据为字符串字面量的原始八位字节。如果 H 为'1',则编码数据为字符串字面量的霍夫曼编码。
使用霍夫曼编码的字符串字面量使用 附录 B 中定义的霍夫曼代码进行编码(有关示例,请参见 附录 C.4 中的示例以及 附录 C.6 中的响应示例)。编码的数据是与字符串字面的每个八位字节相对应的代码的按位级联。
由于霍夫曼编码的数据并不总是在八位字节的边界处结束,因此在其后插入填充,直到下一个八位字节的边界。为避免将此填充误解为字符串字面的一部分,使用了与 EOS(end-of-string)符号相对应的代码的最高有效位。
在解码时,编码数据末尾的不完整代码将被视为填充和丢弃。严格长于 7 位的填充必须被视为解码错误。与 EOS 符号的代码的最高有效位不对应的填充必须被视为解码错误。包含 EOS 符号的霍夫曼编码的字符串字面必须被视为解码错误。
六. 二进制格式
本节描述每种不同的 header 字段表示形式的详细格式以及动态表大小更新指令。
1. 索引 header 字段表示
索引 header 字段表示可标识静态表或动态表中的条目(请参见第 2.3 节)。
索引的 header 字段表示会将 header 字段添加到已解码的 header 列表中,如第 3.2 节所述。
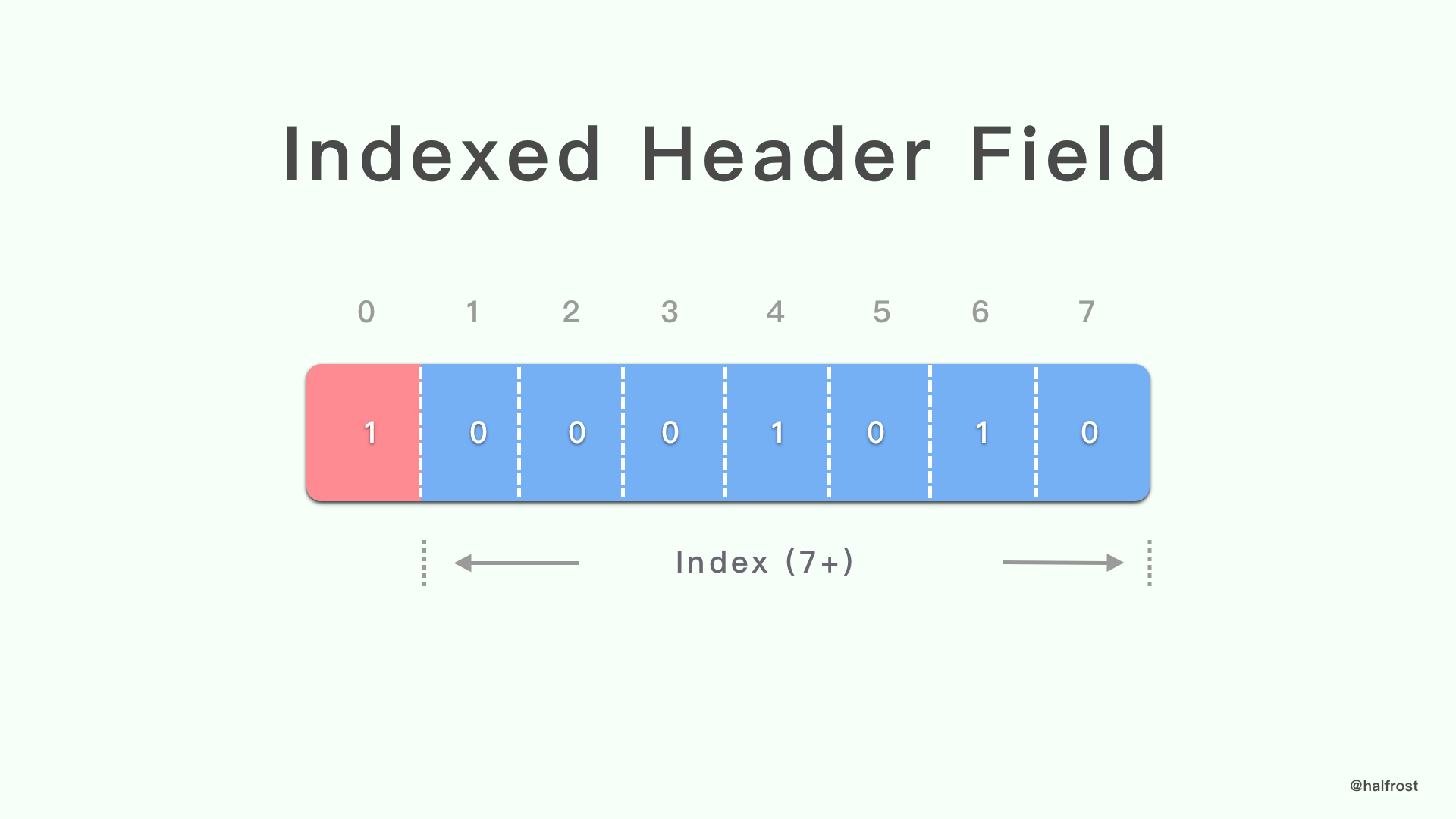
上面这种情况对应的是 Name 和 Value 都在索引表(包括静态表和动态表)中。
索引 header 字段以 1 位模式 “1” 开头,后跟匹配 header 字段的索引,以 7 位前缀的整数表示(请参阅第 5.1 节)。
不使用索引值 0。如果在索引 header 域表示中发现了索引值 0,则必须将其视为解码错误。
2. 字面 header 字段标识
header 字段表示形式包含字面 header 字段 value。header 字段名称 name 以字面形式提供,也可以通过引用静态表或动态表中的现有表条目来提供(请参见第 2.3 节)。
本规范定义了字面 header 字段表示形式的三种形式:带索引,不带索引以及从不索引。
(1). 带增量索引的字面 header 字段
具有增量索引表示形式的字面 header 字段会将 header 字段附加到已解码的 header 列表中,并将其作为新条目插入动态表中。
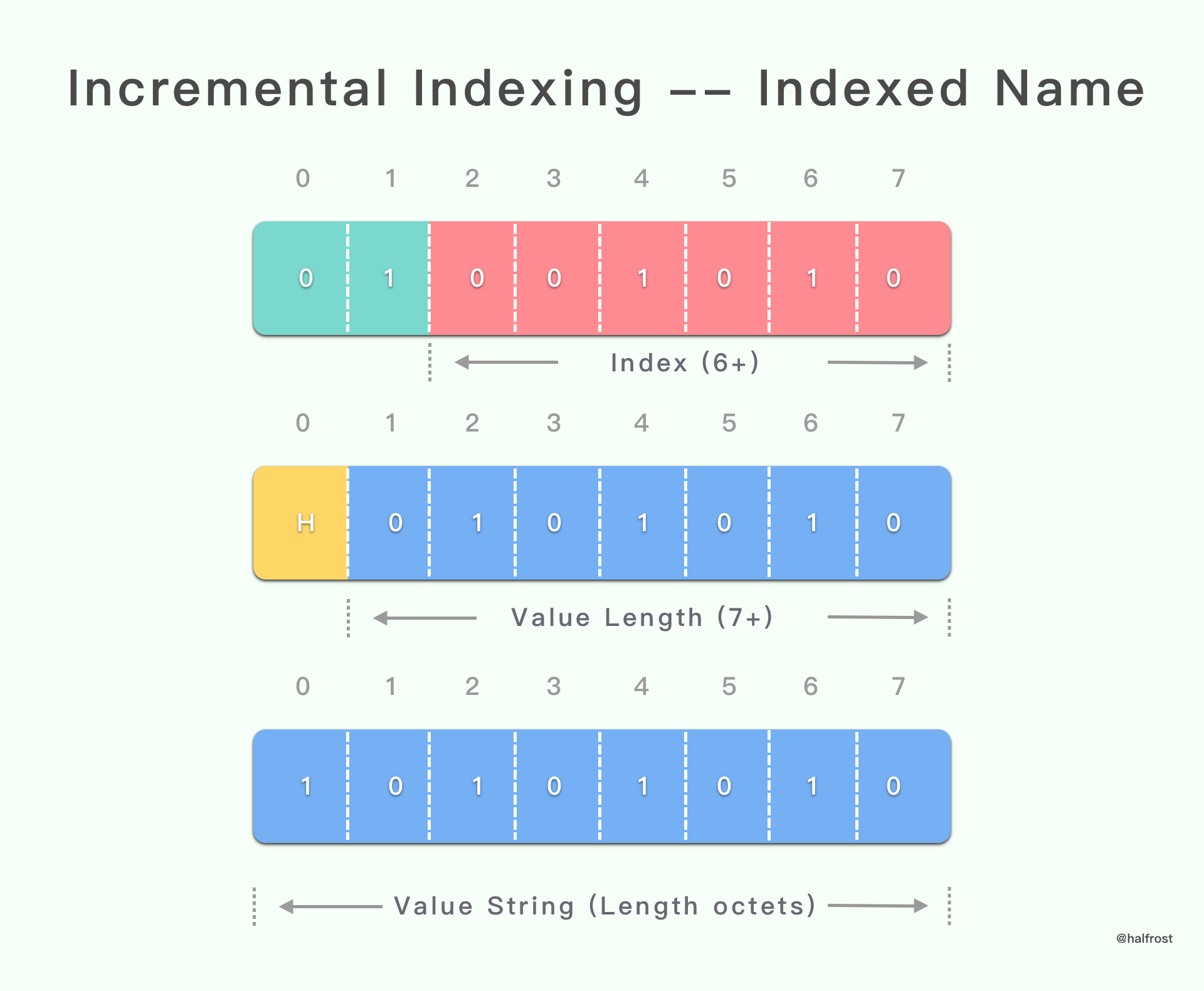
上面这种情况对应的是 Name 在索引表(包括静态表和动态表)中,Value 需要编码传递,并同时新增到动态表中。
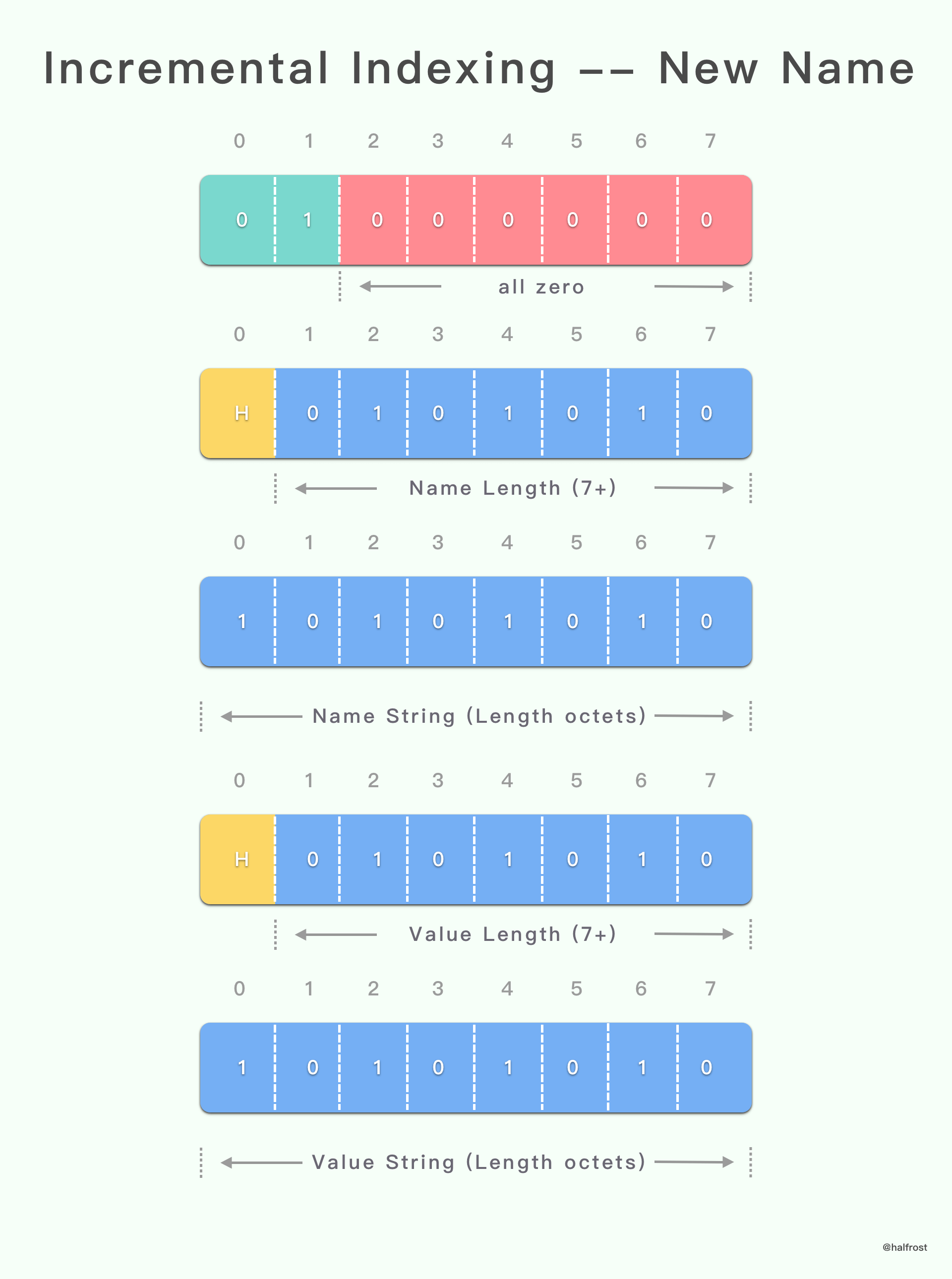
上面这种情况对应的是 Name 和 Value 都需要编码传递,并同时新增到动态表中。
具有增量索引表示的字面 header 字段以 “01” 2 位模式开头。
如果 header 字段名称 name 与存储在静态表或动态表中的条目的 header 字段名称 name 匹配,则可以使用该条目的索引表示 header 字段名称 name。在这种情况下,条目的索引表示为带有 6 位前缀的整数(请参阅第 5.1 节)。此值一般为非零值。
否则,header 字段名称 name 表示为字符串字面(请参见第 5.2 节)。使用值 0 代替 6 位索引,后跟 header 字段名称 name。
两种形式的 header 字段名称 name 表示形式之后跟着的是以字符串字面表示的 header 字段值 value(参见第 5.2 节)。
(2). 不带索引的字面 header 字段
没有索引表示形式的字面 header 字段会使在不更改动态表的情况下将 header 字段附加到已解码的 header 列表中。

上面这种情况对应的是 Name 在索引表(包括静态表和动态表)中,Value 需要编码传递,并不新增到动态表中。
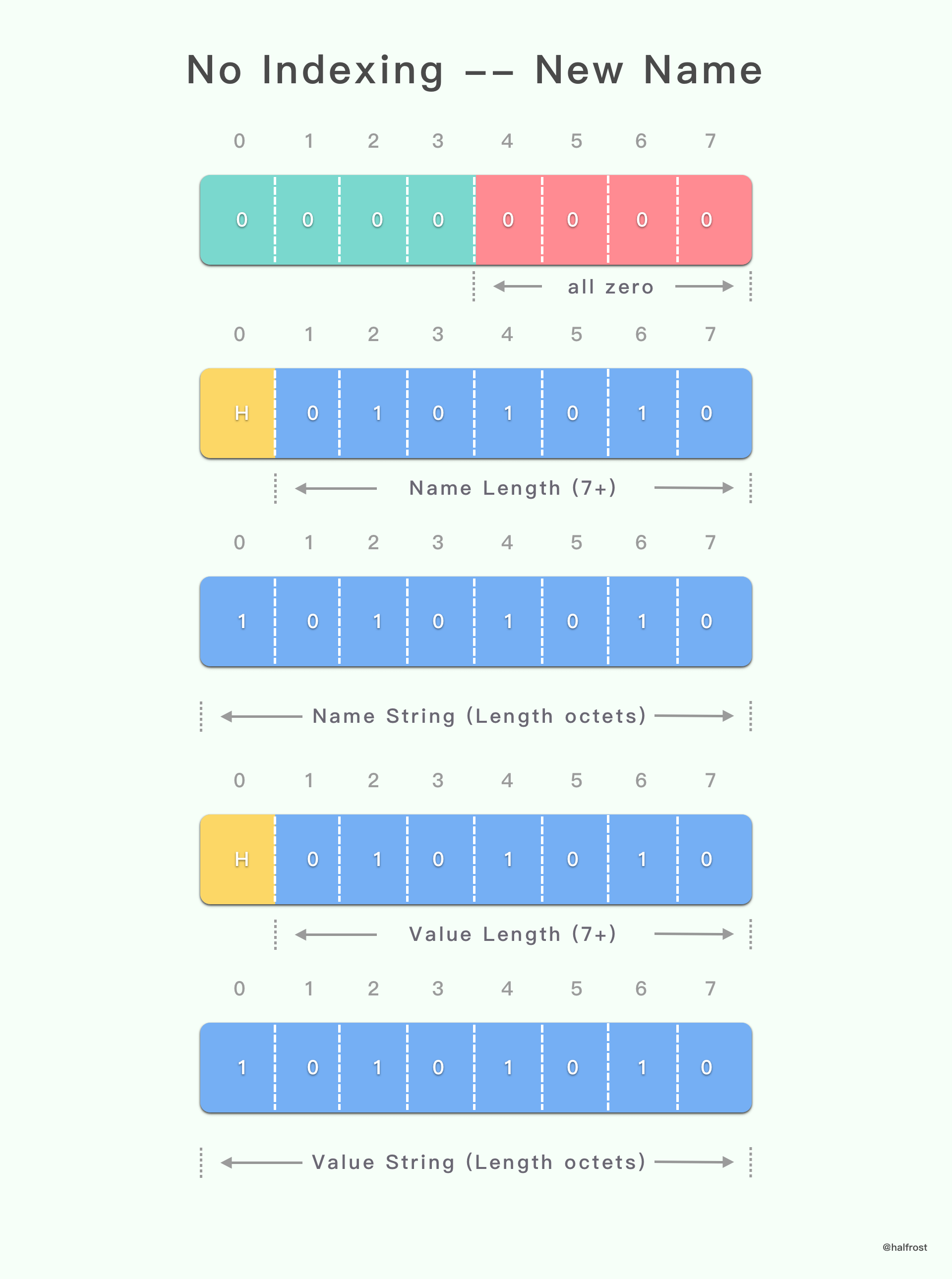
上面这种情况对应的是 Name 和 Value 需要编码传递,并不新增到动态表中。
没有索引表示的字面 header 字段以 “0000” 4 位模式开头。
如果 header 字段名称 name 与存储在静态表或动态表中的条目的 header 字段名称 name 匹配,则可以使用该条目的索引表示 header 字段名称 name。在这种情况下,条目的索引表示为带有 4 位前缀的整数(请参见第 5.1 节)。此值一般为非零值。
否则,header 字段名称 name 表示为字符串字面(请参见第 5.2 节)。使用值 0 代替 4 位索引,后跟 header 字段名称 name。
两种形式的 header 字段名称 name 表示形式之后跟着的是字符串字面的 header 字段值 value(参见第 5.2 节)。
(3). 从不索引的字面 header 字段
字面 header 字段永不索引表示形式会使得在不更改动态表的情况下将 header 字段附加到已解码的 header 列表中。中间件必须使用相同的表示形式来编码该 header 字段。
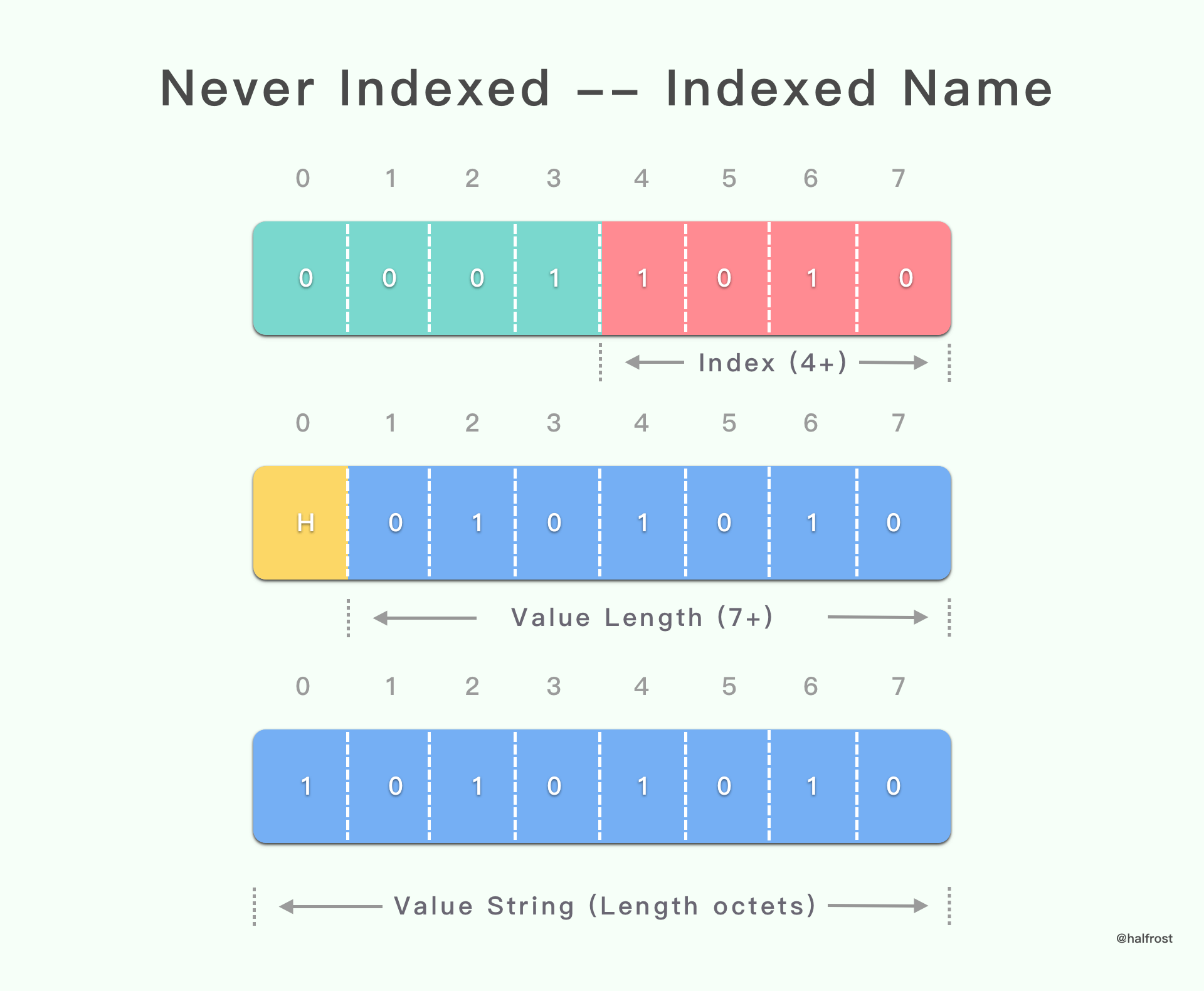
上面这种情况对应的是 Name 在索引表(包括静态表和动态表)中,Value 需要编码传递,并永远不新增到动态表中。

上面这种情况对应的是 Name 和 Value 需要编码传递,并永远不新增到动态表中。
字面 header 字段永不索引的表示形式以 “0001” 4 位模式开头。
当 header 字段表示为永不索引的字面 header 字段时,务必使用此特定字面表示进行编码。特别地,当一个对端发送了一个接收到的 header 域的时候,并且接收到的 header 表示为从未索引的字面 header 域时,它必须使用相同的表示来转发该 header 域。
此表示目的是为了保护 header 字段值 value,通过压缩来保护它们不会被置于风险之中(有关更多详细信息,请参见第 7.1 节)。
该表示形式的编码与不带索引的字面 header 字段相同(请参见第 6.2.2 节)。
3. 动态表大小更新
动态表 size 更新代表更改动态表 size。
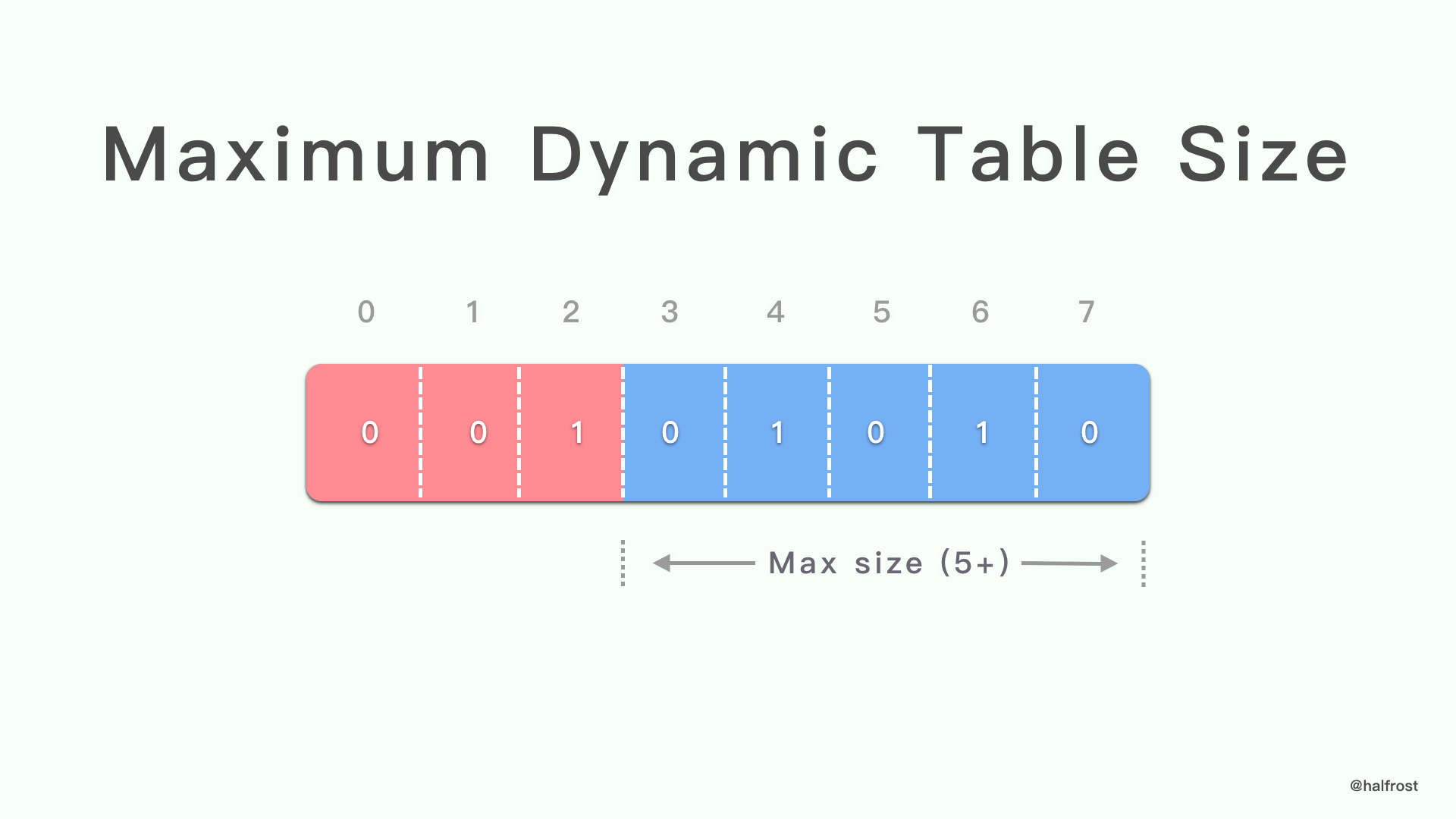
动态表 size 更新从 “001” 3 位模式开始,然后是新的最大 size,以 5 位前缀的整数表示(请参阅第 5.1 节)。
新的最大 size 必须小于或等于协议使用 HPACK 确定的限制。超过此限制的值必须视为解码错误。在 HTTP/2 中,此限制是从解码器接收并由编码器(请参见 [HTTP2]的 6.5.3 节)确认的 SETTINGS_HEADER_TABLE_SIZE (请参见 [HTTP2]的 6.5.2 节)参数的最后一个值。
减小动态表的最大 size 会导致驱逐条目(先进先出)(请参见第 4.3 节)。
动态表大小更新有上述这两种方式,一种是在 HEADERS 帧中直接修改(“001” 3 位模式开始),另外一种方式是通过 SETTINGS 帧中的 SETTINGS_HEADER_TABLE_SIZE 中设置的。
七. 安全注意事项
本节介绍了 HPACK 的潜在安全隐患:
-
将压缩用作基于长度的预测,以验证有关被压缩到共享压缩上下文中的加密的猜想。
-
由于耗尽解码器的处理或存储容量而导致的拒绝服务。
1. 探测动态表状态
HPACK 通过利用 HTTP 等协议固有的冗余性来减少 header 字段编码的长度。这样做的最终目的是减少发送 HTTP 请求或响应所需的数据量。
攻击者可以探测用于编码 header 字段的压缩上下文,攻击者也可以定义要编码和传输的 header 字段,并在编码后观察这些字段的长度。当攻击者可以同时执行这两种操作时,他们可以自适应地修改请求,以确认有关动态表状态的猜想。如果将猜想压缩到较短的长度,则攻击者可以观察编码的长度并推断出猜测是正确的。
即使通过传输层安全性(TLS)协议(请参阅 [TLS12]),这也是有可能被攻击的,因为 TLS 为内容提供加密保护,但仅提供有限的内容长度保护。
注意:填充方案只能对具有这些功能的攻击者提供有限的保护能力,可能对攻击者的影响仅仅只是迫使他增加猜测的次数,来推测与给定猜测相关的长度。填充方案还可以通过增加传输的位数直接抵抗压缩。
诸如 CRIME [CRIME] 之类的攻击证明了这些攻击者的存在。特定攻击利用了 DEFLATE [DEFLATE] 删除基于前缀匹配的冗余这一事实。这使攻击者一次可以确定一个字符,从而将指数时间的 攻击减少为线性时间的攻击。
(1). 适用于 HPACK 和 HTTP
HPACK 通过强制猜测以匹配整个 header 字段值而不是单个字符,来缓解但不能完全阻止以CRIME [CRIME] 为模型的攻击。攻击者只能了解猜测是否正确,因此可以将攻击手段其简化为针对 header 字段值的蛮力猜测。因此,恢复特定 header 字段值的可行性取决于值的熵。结果是,具有高熵的值不太可能成功恢复。但是,低熵值仍然容易受到攻击。
每当两个互不信任的实体在单个 HTTP/2 连接上的接收和发送请求或响应时,就可能发生这种性质的攻击。如果共享的 HPACK 压缩器允许一个实体向动态表添加条目,而另一实体访问这些条目,则可以了解到表的状态。
当中间件发生以下情况时,就会出现来自互不信任实体的请求或响应:
-
从单个连接上的多个客户端向原始服务器发送请求。
-
从多个原始服务器获取响应,并将其在与客户端的共享连接上发送响应。
Web 浏览器还需要假设不同 Web 来源 [ORIGIN] 在同一连接上发出的请求是由互不信任的实体发出的。
(2). 减轻
要求 header 字段具有加密性的 HTTP 用户可以使用具有足以使猜测不可行的熵的值。但是,这作为通用解决方案是不切实际的,因为它会强制 HTTP 的所有用户采取措施减轻攻击。它将对使用 HTTP 的方式施加新的限制。
HPACK 的实现不是在 HTTP 用户上施加约束,而是可以约束压缩的应用方式,以限制动态表探测的潜力。
理想的解决方案基于正在构造 header 字段的实体来隔离对动态表的访问。添加到表中的 header 字段值将归因于一个实体,只有创建特定值的实体才能提取该值。
为了提高此选项的压缩性能,可以将某些条目标记为公共。例如,Web 浏览器可能使 Accept-Encoding header 字段的值在所有请求中都可用。
不太了解 header 字段出处的编码器可能会对具有许多不同值的 header 字段引入惩罚机制,如果攻击者大量尝试去猜测 header 字段值,触发惩罚机制,会导致 header 字段在将来的消息中不再与动态表实体进行比较。这样可以有效地防止了进一步的猜测。
注意:如果攻击者有一个可靠的方法来重新安装值,只是从动态表中删除与 header 字段相对应的条目可能是无效的攻击。例如,在网络浏览器中加载图像的请求通常包含 Cookie header 字段(此类攻击的潜在价值很高的目标),并且网站可以轻松地强制加载图像,从而刷新动态表中的条目。
该响应可能与 header 字段值的长度成反比。与更短的值相比,更短的值更可能以更快的速度或更高的概率将 header 字段标记为不再使用的动态表。
(3). 永不索引的字面
实现方也可以选择不对敏感 header 字段进行压缩,而是将其值编码为字面,从而保护它们。
仅仅只在避免在所有跃点上都进行压缩的情况下,拒绝生成 header 字段的索引表示才有效。永不索引的字面(请参阅第 6.2.3 节)可用于向中间件发出信号,指示有意将特定值作为字面发送。
中间件不得将使用永不索引的字面表示形式的值与将对其进行索引的另一个表示形式重新编码。如果使用 HPACK 进行重新编码,则必须使用永不索引的字面表示。
对于 header 字段使用从不索引的字面表示形式的选择取决于多个因素。由于 HPACK 不能防止猜测整个 header 字段值,因此攻击者更容易恢复短的或低熵的值。因此,编码器可能选择不索引具有低熵的值。
编码器还可能选择不为被认为具有很高价值或对恢复敏感的 header 字段(例如 Cookie 或授权 header 字段)的值增加索引。
相反,如果值被公开了,则编码器可能更喜欢索引值很小或没有值的 header 字段的索引值。例如,User-Agent header 字段在请求之间通常不会发生变化,而是发送到任何服务器。在这种情况下,确认已使用特定的 User-Agent 值提供的价值很小。
请注意,随着新的攻击不断被发现,这些决定使用永不索引的字面表示形式的标准将随着时间的推移而演变。
2. 静态霍夫曼编码
目前还没有针对静态霍夫曼编码的攻击。一项研究表明,使用静态霍夫曼编码表会造成信息泄漏; 但是,同一项研究得出的结论是,攻击者无法利用此信息泄漏来恢复任何有意义的信息量(请参阅 [PETAL])
动态的霍夫曼编码容易受到攻击!
3. 内存管理
攻击者可以尝试使端点耗尽其内存。HPACK 旨在限制端点分配的内存峰值和状态量。
压缩程序使用的内存量受到遵循 HPACK 协议的动态表中定义的最大 size 限制。在 HTTP/2 中,此值由解码器通过设置参数 SETTINGS_HEADER_TABLE_SIZE 来控制的(请参见 [HTTP2]的 6.5.2 节)。此限制既考虑了动态表中存储的数据大小,又考虑了少量的开销。
解码器可以通过为动态表的最大 size 设置适当的值来限制状态存储器的使用量。在 HTTP/2 中,这是通过为 SETTINGS_HEADER_TABLE_SIZE 参数设置适当的值来实现的。编码器可以通过发信号通知动态表 size 小于解码器允许的状态来限制其使用的状态存储器的数量(请参见第 6.3 节)。
编码器或解码器消耗的临时内存量可以通过顺序处理 header 字段来限制。实现方不需要保留 header 字段的完整列表。但是请注意,由于其他原因,应用程序可能有必要保留完整的 header 列表。即使 HPACK 不会强迫这种情况发生,应用程序约束也可能使得它变得有必要。
4. 实现方的限制
HPACK 的实现方需要确保整数的大值,整数的长编码或长字符串字面不会造成安全漏洞。
一个实现必须为它接受的整数值和编码长度设置一个限制(请参阅第 5.1 节)。同样,它必须为字符串字面设置一个限制长度(请参见第 5.2 节)。
Reference:
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub