前言
这篇不出意外就是 Google S2 整个系列的最终篇了。这篇里面会把 regionCoverer 算法都讲解清楚。至于 Google S2 库里面还有很多其他的小算法,代码同样也很值得阅读和学习,这里也就不一一展开了,有兴趣的读者可以把整个库都读一遍。
在写这篇文章的同时,发现了库的作者的一些新的 commit ,比如 2017年12月4号的 commit f9610db2b871b54b17d36d4da6a4d6a2aab6018d,这次提交的改动更改了 README,别看只改了文档,其实里面内容很多。
-For an analogous library in C++, see
-https://code.google.com/archive/p/s2-geometry-library/, and in Java, see
-https://github.com/google/s2-geometry-library-java
------------------------------------------------------------------------------------
+For an analogous library in C++, see https://github.com/google/s2geometry, in
+Java, see https://github.com/google/s2-geometry-library-java, and Python, see
+https://github.com/google/s2geometry/tree/master/src/python
可以看到他们把原来存在 Google 官方私有代码仓库里面的代码放到了 github。之前都只能在代码归档里面查看 C++ 代码,现在直接可以在 github 上查看了。方便了很多。
+More details about S2 in general are available on the S2 Geometry Website
+[s2geometry.io](https://s2geometry.io/).
在这次 commit 里面还提到了一个新的网站,这个网站我发现也是最近才发布出来的。因为笔者我连续关注 S2 每个 commit 了快半年了。网上每个关于 S2 的资源都有关注,这个网站非常新。关于这个网站文章最后会提到,这里就不详细说了。
从这个提交开始,笔者认为 Google S2 可能被重视起来了,也有可能打算大力推广了。
好了,正式进入正题。
一. 空间类型
在 Google S2 中能进行 RegionCovering 的有以下几种类型。基本上都是必须满足 Region interface 的。
1. Cap 球帽
Cap 代表由中心和半径限定的盘形区域。从技术上讲,这种形状被称为“球形帽”(而不是圆盘),因为它不是平面的。帽子代表被飞机切断的球体的一部分。帽的边界是由球面与平面的交点所定义的圆。帽子是一个封闭的组合,即它包含了它的边界。 大多数情况下,无论在平面几何中使用光盘,都可以使用球冠。帽的半径是沿着球体表面测量的(而不是通过内部的直线距离)。因此,一个半径为 π/ 2 的帽是一个半球,半径为 π 的帽覆盖整个球。 中心是单位球面上的一个点。(因此需要它是单位长度)帽子也可以由其中心点和高度来定义。高度是从中心点到截断平面的距离。还有支持“空”和“全”的上限,分别不包含任何点数和所有点数。 下面是帽高(h),帽半径(r),帽中心的最大弦长(d)和帽底部半径(a)之间的一些有用关系。
h = 1 - cos(r)
= 2 * sin^2(r/2)
d^2 = 2 * h
= a^2 + h^2
2. Loop 循环
Loop 代表一个简单的球面多边形。它由一系列顶点组成,其中第一个顶点隐含地被认为是连接到最后一个顶点的。所有的 loop 被定义为具有 CCW 方向,即 loop 的内部在边的左侧。这意味着包围一个小区域的顺时针 loop 被解释为包围非常大的区域的 CCW 的 loop。 loop 不允许有任何重复的顶点(不管是否相邻)。不允许相邻的边相交,而且不允许长度为180度的边(即,相邻的顶点不能是相反的)。loop 必须至少有3个顶点(下面讨论的“空”和“全” loop 除外)。 有两个特殊的 loop:EmptyLoop 不包含点,FullLoop 包含所有点。这些 loop 没有任何边,但为了保持每一个 loop 都可以表示为顶点链的不变量,它们被定义为每个只有一个顶点。
3. Polygon 多边形
多边形表示一个零或多个 loop 的序列;同样,一个 loop 的左手边方向定义为它的内部。 当多边形初始化时,给定的 loop 自动转换为“孔”的组成的规范形式。loop 被重新排序以对应于嵌套层次的预定义遍历方式。 多边形可以表示具有多边形边界的球体的任何区域,包括整个球体(称为“完整”多边形)。完整的多边形由一个完整的 loop 组成,而空的多边形完全没有 loop。 使用 FullPolygon() 来构造一个完整的多边形。 Polygon 的零值被视为空的多边形。
想要 多个 loop 构成一个 Polygon 多边形,必须满足以下4个条件:
- loop 不能交叉,即 loop 的边界可能不与任何其他 loop 的内部和外部相交。
- loop 不共享边缘,即如果 loop 包含边缘 AB,则其他 loop 可能不包含 AB 或 BA。
- loop 可以共享顶点,但是在单个 loop 中不会出现两次顶点(参见S2Loop)。
- 不能有空的 loop。full loop 可能只出现在完整的 full polygon 中。
4. Rect 矩形
Rect 代表一个封闭的经纬度矩形。它也是 Region 类型。它能够表示空的和完整的矩形以及单个点。它有一个 AddPoint 方法,可以方便地为一组点构造边界矩形,包括跨越180度子午线的点集。
5. Region 区域
区域表示单位球体上的二维区域。 这个接口的目的是让复杂的区域近似为更简单的区域。该接口仅限于计算近似值的方法。
S2 区域表示单位球体上的二维区域。它是一个具有各种具体子类型的抽象接口,如盘形,矩形,多段线,多边形,几何集合,缓冲形状等。 这个接口的主要目的是使复杂区域近似为更简单的区域。因此,接口只能用于计算近似值的方法,而不是具有各种各样的由所有子类型实现的虚拟方法。
6. Shape 形状
Shape 算是一切图形或者形状的“基类”了。它可以最灵活的方式表示几何多边形。它是由边缘的集合构成的,可选地定义内部。由给定 Shape 表示的所有几何图形必须具有相同的尺寸,这意味着 Shape 可以表示一组点,一组多边形或一组多边形。 Shape 被定义为一个接口,以便让客户端更加方便的控制底层的数据表示。有时一个 Shape 没有自己的数据,而是包装其他类型的数据。 Shape 操作通常在 ShapeIndex 上定义,而不是单独的形状。 ShapeIndex 只是一个 Shapes 集合,可能有不同的维度(例如10个点和3个多边形),组织成一个数据结构,以便高效的访问。 Shape 的边缘由从 0 开始的连续范围的边缘 ID 索引。边缘被进一步细分为链,其中每个链由端到端连接的一系列边(多段线)组成。例如,表示两条折线 AB 和 CDE 的形状将具有分成两条链(AB)和(CD,DE)的三条边(AB,CD,DE)。类似地,代表5个点的形状将具有由一个边缘组成的5个链。 Shape具有允许使用全局编号(边缘ID)或在特定链中访问边的方法。全局编号对于大多数情况来说是足够的,但链表示对于某些算法(如交集(请参阅BooleanOperation))非常有用。
S2 中总共定义了两个用于表示几何的可扩展接口:S2Shape 和 S2Region。
它们两者不同点是:
S2Shape 的目的是灵活地表示多边形几何。 (这不仅包括多边形,还包括点和折线)。大部分的核心 S2 操作将与任何实现 S2Shape 接口的类一起工作。
S2Region 的目的是计算几何的近似值。例如,有计算边界矩形和圆盘的方法,S2RegionCoverer 可以用来逼近一个区域,以任意期望的精度作为单元的集合。与S2Shape 不同,S2Region 可以表示非多边形几何形状,例如球帽(S2Cap)。
除去上面说的这几种常用的类型以外,还有以下这些中间类型或者更加底层的类型可以供开发者使用。
- S2LatLngRect - 经纬度坐标系中的矩形。
- S2Polyline - 折线。
- S2CellUnion - 一个近似为S2CellIds集合的区域。RegionCoverer 转换以后都是这种类型。
- S2ShapeIndexRegion - 点,多义线和多边形的任意集合。
- S2ShapeIndexBufferedRegion - 定义和 S2ShapeIndexRegion 一样,只是扩大了给定的半径。
- S2RegionUnion - 任意区域的集合。
- S2RegionIntersection - 任意其他区域的交集部分。
最后,额外说一句,S2RegionTermIndexer 这个类型是支持索引和查询任何类型的S2Region,也就是上述说的所有的类型。可以使用 S2RegionTermIndexer 来索引一组多段线,然后查询哪些多段线与给定的多边形相交。
二. RegionCoverer 举例
RegionCoverer 主要是要找到一个能覆盖当前区域的近似最优解(为何不是最优解?)
转换条件主要有3个,MaxLevel, MaxCells, MinLevel。MaxCells 决定了最大 cell 的个数,但是太接近最大值以后又会导致覆盖面积太大,不精确。所以最大个数仅仅是限制在满足最大精度的条件下最多不能超过这个个数。由于这一点导致并不是满足 MaxCells 的最优解。
举几个例子:
下面是一个半径为 10 公里的 cap,并且这个 cap 位于 3 个 face 夹角处,我们假设需要最大个数为 10 的 cell 去覆盖它。结果如下:
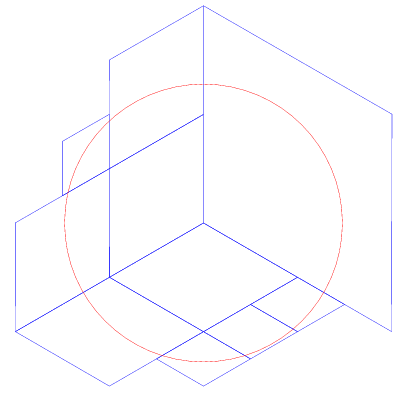
相同的设置,我们把个数改到 20,如下:
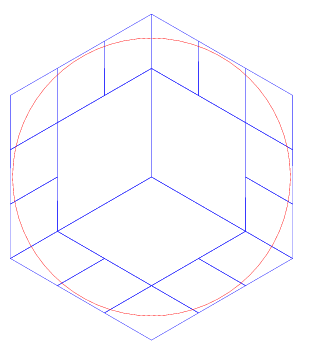
还是相同的配置,把个数改到 50 个:
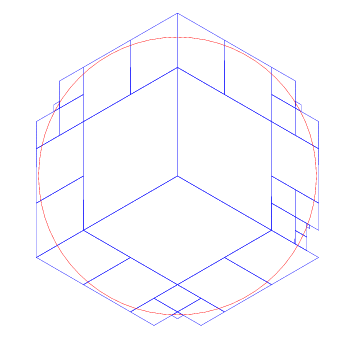
到目前,精确度马马虎虎,边缘部门覆盖的还是多于原始的 cap 了,我们继续提高精度,把个数调整到 200 。
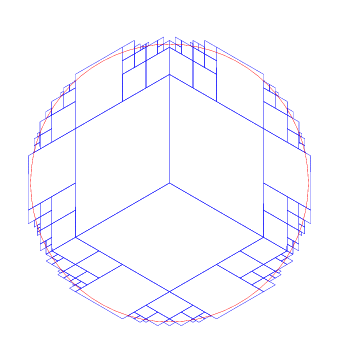
200 个看似比较精确了,我们再提高一下,提高到 1000,看看会出现什么结果。
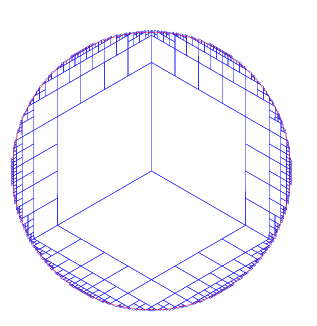
代码配置上虽然设置的 1000 个,实际只有 706 个 cell。原因是代码上虽然是按照 1000 个计算的,但是实际算法处理上还会进行 cell 剪枝后的合并。所以最终个数会小于 1000 个。
再看一个例子,下面这个矩形是表示一个纬度/经度矩形从北纬 60 度延伸到北纬 80 度,从 -170 度经度延伸到 +170 度。覆盖范围限于 8 个单元。请注意,中间的洞被完全覆盖。这明显是不符合我们的意图的。
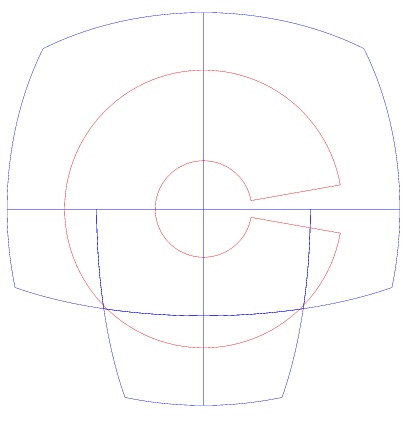
我们把 cell 的个数提高到 20 个。中间的孔依旧被填补上了。
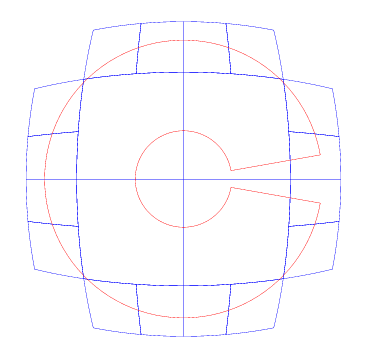
我们把参数调节到 100 个,其他配置都完全一样。现在中间的孔有一定样子了。但是日期线附近的空白还是没有出来。
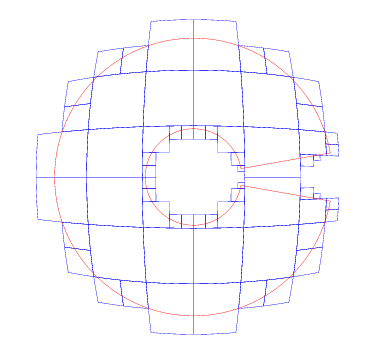
最后把参数调整到 500 个。现在中间的孔就比较完整的显示出来了。
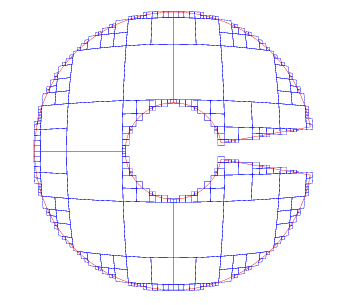
在举几个我们实际项目中用到的例子。下面是上海的一个网格的边缘。我们先用
defaultCoverer := &s2.RegionCoverer{MaxLevel: 16, MaxCells: 100, MinLevel: 13}
去转换,得到的结果如下:
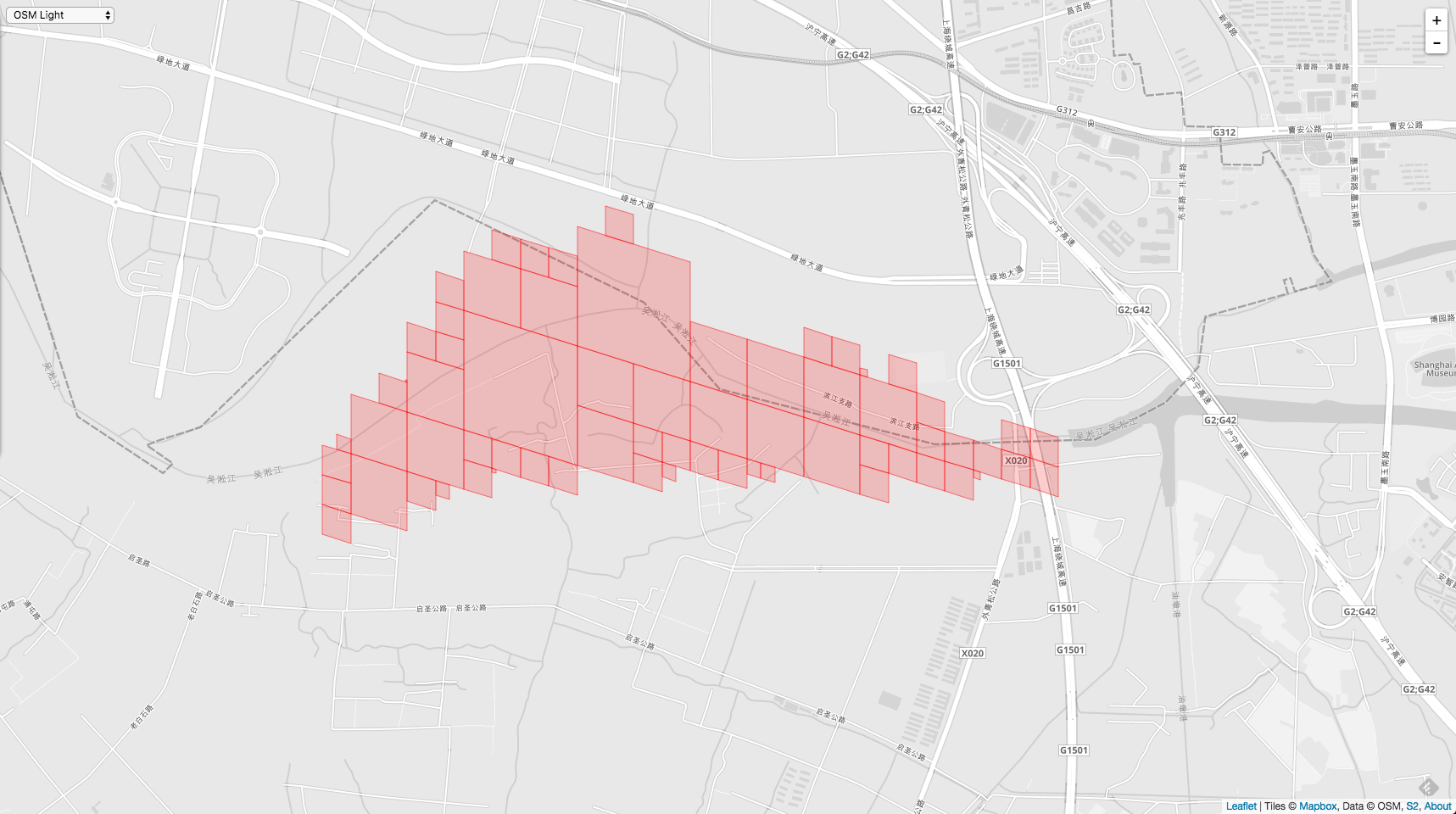
defaultCoverer := &s2.RegionCoverer{MaxLevel: 30, MaxCells: 1000, MinLevel: 1}
精确度提高到1000,结果就会如下:
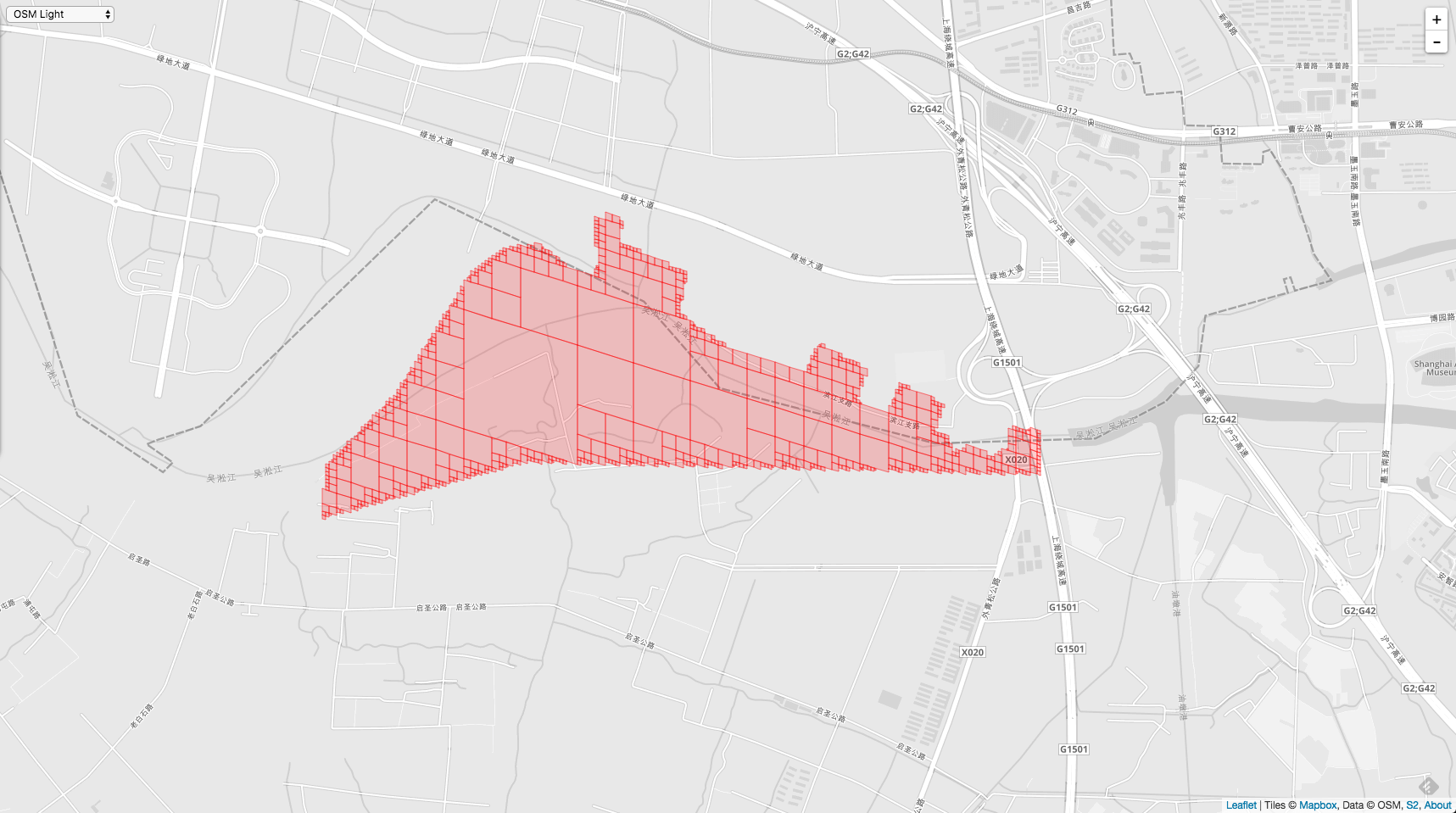
还有一些区域更大的情况,比如一个省,湖北省:
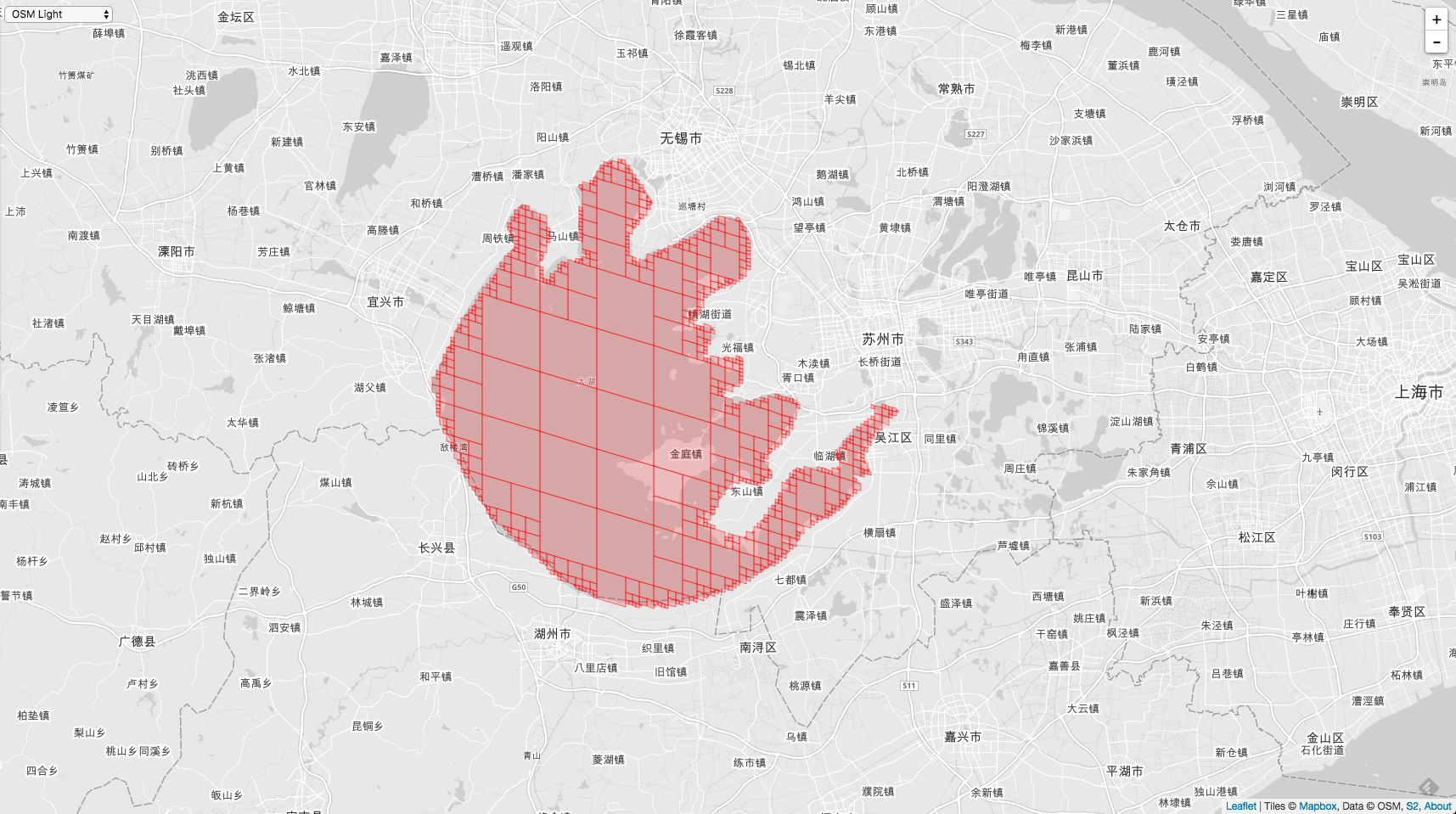
或者一个湖,太湖:
最后在举一个 polygon 的例子。我们知道 polygon 是由多个 loop 组成的:
loops := []*s2.Loop{}
loops = append(loops, loop1)
loops = append(loops, loop2)
polygon := s2.PolygonFromLoops(loops)
defaultCoverer := &s2.RegionCoverer{MaxLevel: 16, MaxCells: 100, MinLevel: 8}
fmt.Println("---- polygon-----")
cvr = defaultCoverer.Covering(polygon)
for i := 0; i < len(cvr); i++ {
fmt.Printf("%d,\n", cvr[i])
}
fmt.Printf("------------\n")
下面一次是两个 loop 在地图上的样子。
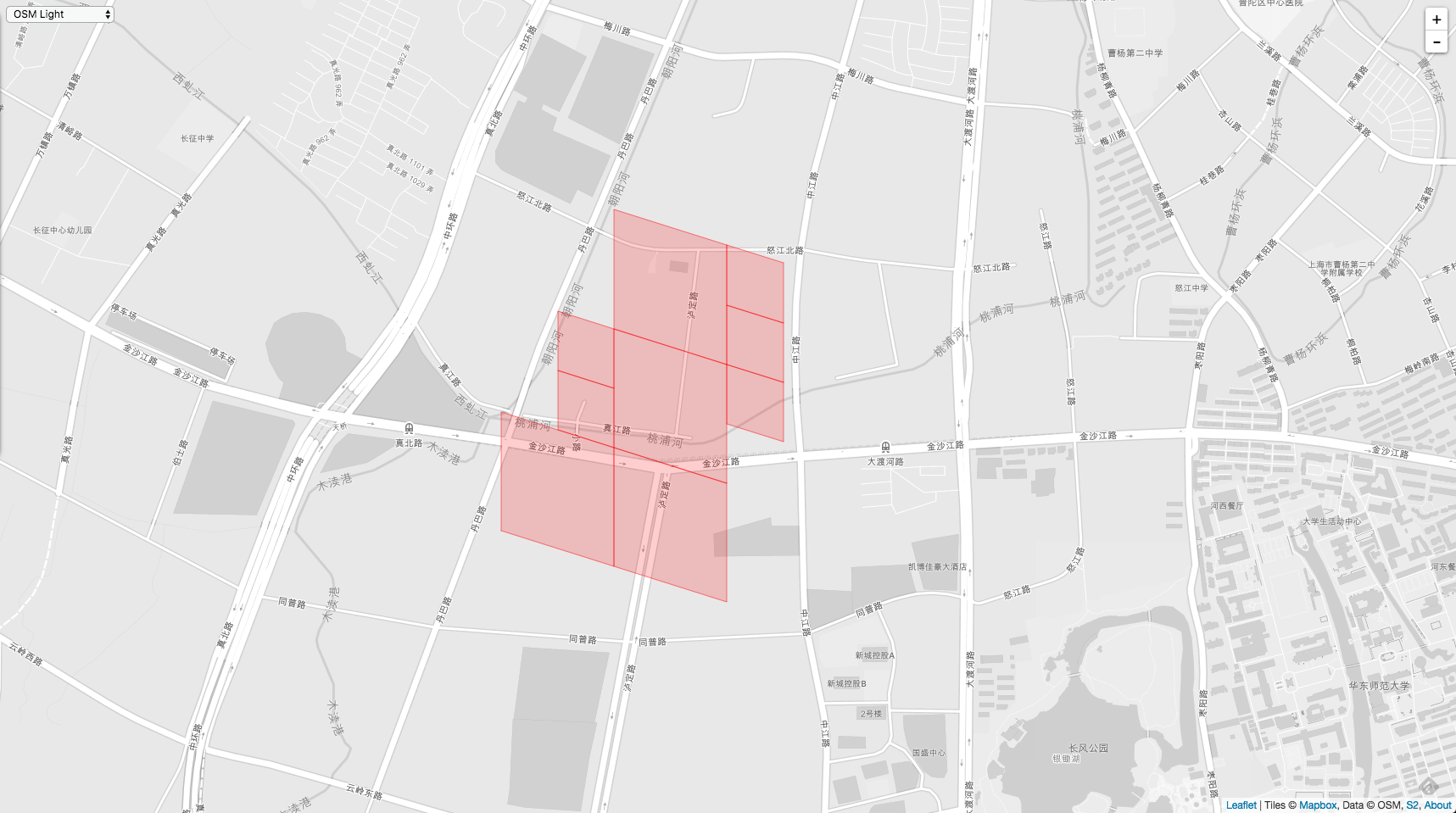
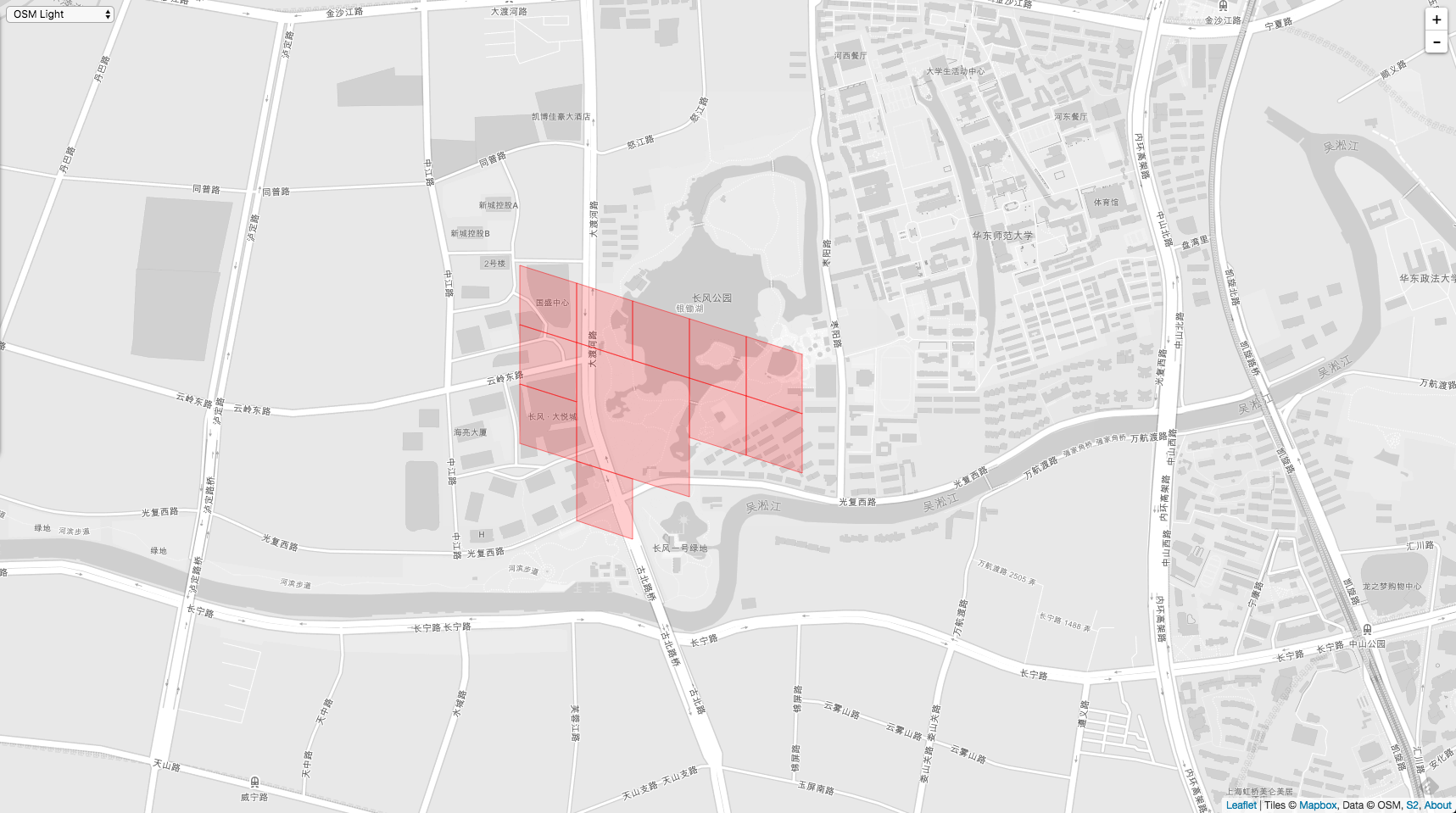
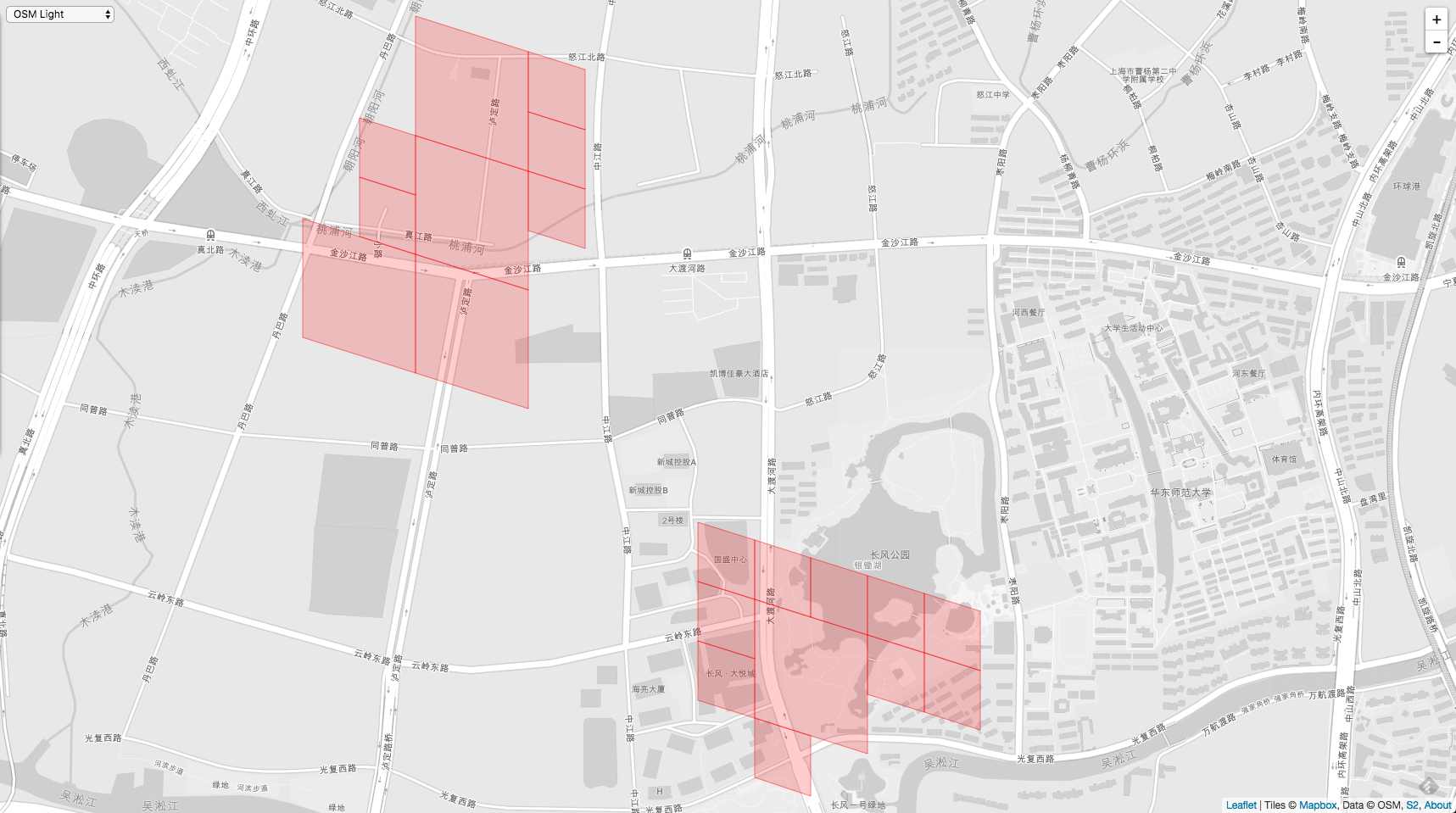
最后是 polygon,它包含了以上2个 loop。
三. RegionCoverer 核心算法 Covering 的实现
这一章节详细分析一下 Covering 是如何实现的。
最常见的用法就是下面几行:
rc := &s2.RegionCoverer{MaxLevel: 30, MaxCells: 5}
r := s2.Region(CapFromCenterArea(center, area))
covering := rc.Covering(r)
上面例子展示的是最多转换以后 CellUnion 里面有5个 CellID。上面这三行覆盖的区域是一个 Cap。
type RegionCoverer struct {
MinLevel int // the minimum cell level to be used.
MaxLevel int // the maximum cell level to be used.
LevelMod int // the LevelMod to be used.
MaxCells int // the maximum desired number of cells in the approximation.
}
RegionCoverer 是一个结构体,实际上里面是包含4个元素的。MinLevel、MaxLevel、MaxCells,这3个应该不用解释了,用的很多。关键要说明说明 LevelMod。
LevelMod 这个值一旦设置了以后,在进行 RegionCover 转换的时候,选取的 Cell Level 只能是 (level - MinLevel) % LevelMod = 0,即 (level - MinLevel) 只能是 LevelMod 的倍数,满足这个条件的 Cell Level 才会被选取。这能有效地允许S2 CellID 层级的分支因子增加。当前的参数取值只能是0,1,2,3,对应的分支因子是0,4,16,64 。
再来谈谈算法的核心思想。
RegionCover 可以被抽象成这样一种问题,给定一个区域,用尽可能精确的 Cell 去覆盖它,但是个数最多不要超过 MaxCells 的个数,问如何去找到这些 Cell ?
这个问题就是一个近视最优解的问题。如果想最精确,方案当然是边缘部分全部都用 MaxLevel 去铺(Level 越大,格子越小)这样就最精确。但是这样会导致 Cell 的个数陡增,远远超过 MaxCells,这样就又不符合要求了。那如何能在 <= MaxCells 的情况下还能最精确的覆盖给定的区域呢?
有几点需要提前说明的是:
- MinLevel 优先级高于 MaxCells(注意这里不是 MaxLevel),即低于给定 Level 的 Cell 永远都不会被使用,即使用一个它能替代掉很多面积小(Level 大)的 Cell。
- 对于 MaxCells 的最小取值范围,如果某一种情况要求的是所需的最小单元数量(例如,如果该区域与所有六个面单元相交),则可以返回多达6个单元。 如果碰巧位于三个立方体面的交点处,即使对于非常小的凸起区域也可能返回多达3个单元格。
- 如果 MinLevel 对于近似的区域来说都太大了,那么 MaxCells 是会失去约束的限制,可以返回任意数量的单元格。
- 如果 MaxCells 小于4,即使该区域是凸的,比如 cap 或者 rect ,最终覆盖的面积也要比原生区域大。所以这种情况开发者心里要清楚。
好了,接下来从源码开始看起。RegionCoverer 转换的核心函数就是这个了。
func (rc *RegionCoverer) Covering(region Region) CellUnion {
covering := rc.CellUnion(region)
covering.Denormalize(maxInt(0, minInt(maxLevel, rc.MinLevel)), maxInt(1, minInt(3, rc.LevelMod)))
return covering
}
从这个函数实现我们可以看到,转换实际上就分为2步,一步是 Normalize Cell + 转换,另外一步是 Denormalize Cell。
(一). CellUnion
CellUnion 方法的具体实现:
func (rc *RegionCoverer) CellUnion(region Region) CellUnion {
c := rc.newCoverer()
c.coveringInternal(region)
cu := c.result
cu.Normalize()
return cu
}
这个方法主要也可以分解成三个部分,新建 newCoverer、coveringInternal、Normalize。
1. newCoverer()
func (rc *RegionCoverer) newCoverer() *coverer {
return &coverer{
minLevel: maxInt(0, minInt(maxLevel, rc.MinLevel)),
maxLevel: maxInt(0, minInt(maxLevel, rc.MaxLevel)),
levelMod: maxInt(1, minInt(3, rc.LevelMod)),
maxCells: rc.MaxCells,
}
}
newCoverer() 方法是初始化一个 coverer 的结构体。maxLevel 是一个之前定义过的常量,maxLevel = 30。coverer 的初始化参数全部都来自于 RegionCoverer 的参数。我们在外部初始化了一个 RegionCoverer ,它主要包含的4个参数,MinLevel,MaxLevel,LevelMod,MaxCells,都会传到这里。上面这段初始化函数里面用到的 maxInt、minInt 主要用来进行非法值的处理。
其实 coverer 结构体里面包含了8个元素项。
type coverer struct {
minLevel int // the minimum cell level to be used.
maxLevel int // the maximum cell level to be used.
levelMod int // the LevelMod to be used.
maxCells int // the maximum desired number of cells in the approximation.
region Region
result CellUnion
pq priorityQueue
interiorCovering bool
}
除去上面初始化的4项,其实它还包含其他重要的4项,这4项会在下面用到。region 要覆盖的区域。result 就是最终转换的结果,结果是一个 CellUnion 的数组,pq 是优先队列 priorityQueue,interiorCovering 是一个 bool 变量,标志的当前转换是否是内部转换。
2. coveringInternal()
接下来看看 coveringInternal 方法。
func (c *coverer) coveringInternal(region Region) {
c.region = region
c.initialCandidates()
for c.pq.Len() > 0 && (!c.interiorCovering || len(c.result) < c.maxCells) {
cand := heap.Pop(&c.pq).(*candidate)
if c.interiorCovering || int(cand.cell.level) < c.minLevel || cand.numChildren == 1 || len(c.result)+c.pq.Len()+cand.numChildren <= c.maxCells {
for _, child := range cand.children {
if !c.interiorCovering || len(c.result) < c.maxCells {
c.addCandidate(child)
}
}
} else {
cand.terminal = true
c.addCandidate(cand)
}
}
c.pq.Reset()
c.region = nil
}
coveringInternal 方法会生成覆盖的方案,并把结果存储在 result 内。覆盖转换的大体策略是:
从立方体的6个面开始。丢弃任何与该区域不相交的形状。然后重复选择与形状相交的最大单元格并将其细分。
coverer 结构体里面的8个元素,前4个是外部传进来初始化的,后4个元素就是在这里被用到的。首先
c.region = region
初始化 coverer 的区域。另外三个元素是 result、pq、interiorCovering 在下面都会被用到。
result 中只是包含将成为最终输出的一部分的满足条件的 Cell,而 pq 优先队列里面包含可能仍然需要继续再细分的 Cell。
如果一个 Cell 100% 完全被包含在覆盖区域内,就会被立即添加到输出中,而完全不和该区域有任何相交的部分的 Cell 会立即丢弃。所以 pq 优先队列中只会包含部分与该区域相交的 Cell。
pq 优先队列出队的策略是:
1. 首先根据 Cell 大小(首先开始是大的 Cell)优先考虑候选人
2. 然后根据相交的孩子的数量(最少的孩子优先级高,先出列)
3. 最后按完全容纳的孩子的数量(最少的孩子优先级高,先出列)
经过 pq 优先队列的筛选以后,最终留下来的 Cell 必定是优先级最低的,即 Cell 面积是比较小的,并且和区域相交的部分较大且和完全容纳孩子数量最多。也就是说和区域边缘上最贴近的 Cell(Cell 覆盖的区域比要覆盖转换的区域多余的部分最少)是会被最终留下来的。
if c.interiorCovering || int(cand.cell.level) < c.minLevel || cand.numChildren == 1 || len(c.result)+c.pq.Len()+cand.numChildren <= c.maxCells {
}
coveringInternal 函数实现中的这个判断条件的意图是:
对于内部覆盖转换,无论候选人有多少孩子,我们都会将其继续不断细分。如果我们在扩大所有孩子之前到达 MaxCells,我们将只使用其中的一些。对于外部覆盖我们不能这样做,因为结果必须覆盖整个地区,所以所有的孩子都必须使用。
candidate.numChildren == 1
在上述的情况下,我们已经有更多的 MaxCells 结果(minLevel太高)的情况下照顾情况。有一个孩子的候选人就算继续细分在这种情况下对最终结果也没有什么影响。
3. initialCandidates()
接下来看看如何初始化候选人的:
func (c *coverer) initialCandidates() {
// Optimization: start with a small (usually 4 cell) covering of the region's bounding cap.
temp := &RegionCoverer{MaxLevel: c.maxLevel, LevelMod: 1, MaxCells: min(4, c.maxCells)}
cells := temp.FastCovering(c.region)
c.adjustCellLevels(&cells)
for _, ci := range cells {
c.addCandidate(c.newCandidate(CellFromCellID(ci)))
}
}
这个函数里面有一个小优化,把区域第一步覆盖转换成4个 Cell 覆盖区域边缘的 Cap。initialCandidates 方法实现中比较重要的两个方法是 FastCovering 和 adjustCellLevels。
4. FastCovering()
func (rc *RegionCoverer) FastCovering(region Region) CellUnion {
c := rc.newCoverer()
cu := CellUnion(region.CellUnionBound())
c.normalizeCovering(&cu)
return cu
}
FastCovering 函数会返回一个 CellUnion 集合,这个集合里面的 Cell 覆盖了给定的区域,但是这个方法的不同之处在于,这个方法速度很快,得到的结果也比较粗糙。当然得到的 CellUnion 集合也是满足 MaxCells, MinLevel, MaxLevel, 和 LevelMod 要求的。只不过结果不尝试去使用 MaxCells 的大值。一般会返回少量的 Cell,所以结果比较粗糙。
所以把 FastCovering 这个函数作为递归细分 Cell 的起点,非常管用。
在这个方法中,会调用 region.CellUnionBound() 方法。这个要看各个 region 区域是如何实现这个 interface 的。
这里以 loop 为例,loop 对 CellUnionBound() 的实现如下:
func (l *Loop) CellUnionBound() []CellID {
return l.CapBound().CellUnionBound()
}
上面方法就是快速计算边界转换的具体实现。也是实现空间覆盖的核心部分。
CellUnionBound 返回覆盖区域的 CellID 数组。 Cell 没有排序,可能有冗余(例如包含其他单元格的单元格),可能覆盖的区域多于必要的区域。
也由于上面这个理由,导致此方法不适用于客户端代码直接使用。 客户通常应该使用 Region.Covering 方法,Covering 方法可以用来控制覆盖物的大小和准确性。 另外,如果你想快速覆盖,不关心准确性,可以考虑调用 FastCovering(它会返回一个由此方法计算出来的被覆盖的清理版本)。
CellUnionBound 实现应该尝试返回覆盖区域的小覆盖(理想情况下为4个或更少),并且可以快速计算。所以 CellUnionBound 方法被 RegionCoverer 用作进一步改进的起点。
func (l *Loop) CapBound() Cap {
return l.bound.CapBound()
}
CapBound 返回一个边界上限,它可能比相应的 RectBound 会有更多的填充。它的边界是保守的,如果 loop 包含点P,那么边界也一定包含这个点。
func (c Cap) CellUnionBound() []CellID {
level := MinWidthMetric.MaxLevel(c.Radius().Radians()) - 1
// If level < 0, more than three face cells are required.
if level < 0 {
cellIDs := make([]CellID, 6)
for face := 0; face < 6; face++ {
cellIDs[face] = CellIDFromFace(face)
}
return cellIDs
}
return cellIDFromPoint(c.center).VertexNeighbors(level)
}
上面这段代码就是转换的最粗糙版本的核心算法了。在这段算法里面核心一步就是算出要找的 level。
level := MinWidthMetric.MaxLevel(c.Radius().Radians()) - 1
这里找到的 Level 就是该 Cap 所能包含的最大的 Cell。
return cellIDFromPoint(c.center).VertexNeighbors(level)
上面这句就是返回了 4 个 Cell,距离 Cap 中心点最近的。当然,如果 Cap 非常大,有可能会返回 6 个 Cell。当然,返回的这些 Cell 是没有经过任何排序的。
5. normalizeCovering()
FastCovering 的最后一步就是 normalizeCovering。
func (c *coverer) normalizeCovering(covering *CellUnion) {
// 1
//
if c.maxLevel < maxLevel || c.levelMod > 1 {
for i, ci := range *covering {
level := ci.Level()
newLevel := c.adjustLevel(minInt(level, c.maxLevel))
if newLevel != level {
(*covering)[i] = ci.Parent(newLevel)
}
}
}
// 2
//
covering.Normalize()
// 3
//
for len(*covering) > c.maxCells {
bestIndex := -1
bestLevel := -1
for i := 0; i+1 < len(*covering); i++ {
level, ok := (*covering)[i].CommonAncestorLevel((*covering)[i+1])
if !ok {
continue
}
level = c.adjustLevel(level)
if level > bestLevel {
bestLevel = level
bestIndex = i
}
}
if bestLevel < c.minLevel {
break
}
(*covering)[bestIndex] = (*covering)[bestIndex].Parent(bestLevel)
covering.Normalize()
}
// 4
//
if c.minLevel > 0 || c.levelMod > 1 {
covering.Denormalize(c.minLevel, c.levelMod)
}
}
normalizeCovering 会对前一步的覆盖转换结果进行进一步的规范化,使其符合当前覆盖参数(MaxCells,minLevel,maxLevel和levelMod)。 这种方法不会尝试最佳结果。 特别是,如果minLevel> 0或者levelMod> 1,那么即使这不是必需的,它也可能返回比期望的 Cell 更多的值。
在上面的代码实现中标注了4处需要注意的地方。
第一处,判断的是,如果 Cell 太小了,或者不满足 levelMod 的条件,就用他们的祖先来替换掉他们。
第二处,是对前一步的结果排序并且进一步简化。
第三处,如果 Cell 数量上还是太多,仍然有太多的 Cell,则用 for 循环去查找两个相邻的 Cell 的最近公共祖先 LCA 并替换掉它们俩,for 循环的顺序就是以 CellID 的顺序进行循环的。
这里用到的 LCA 的具体实现在前面一篇文章里面有详解,文章链接,这里就不再赘述了。
第四处,最后确保得到的结果能满足 minLevel 和 levelMod,最好也能满足 MaxCells。
接下来还需要进一步分析的就是 Normalize() 和 Denormalize() 这两个函数实现了。
6. Normalize()
先看 Normalize()。
func (cu *CellUnion) Normalize() {
sortCellIDs(*cu)
output := make([]CellID, 0, len(*cu)) // the list of accepted cells
for _, ci := range *cu {
// 1
if len(output) > 0 && output[len(output)-1].Contains(ci) {
continue
}
// 2
j := len(output) - 1 // last index to keep
for j >= 0 {
if !ci.Contains(output[j]) {
break
}
j--
}
output = output[:j+1]
// 3
for len(output) >= 3 && areSiblings(output[len(output)-3], output[len(output)-2], output[len(output)-1], ci) {
output = output[:len(output)-3]
ci = ci.immediateParent() // checked !ci.isFace above
}
output = append(output, ci)
}
*cu = output
}
Normalize 这个方法的主要意图是想整理 CellUnion 中各个 CellID,经过排序输出没有冗余的 CellUnion。
排序是第一步。
接下来整理冗余的 Cell 是第二步,也是这个函数实现里面关键的一步。冗余分为2种,一种是完全包含,另外一种是4个小的 Cell 可以合并成一个大的。
先处理是否有一个 Cell 完全包含另外一个 Cell 的情况,这种情况下,被包含的那个 Cell 就是冗余的 Cell,就该被丢弃。对应的是上述代码中标1的地方。
在实现上,我们只需要检查最后接受的单元格。 Cell 首先经过排序以后,如果当前这个候选的 Cell 不被最后接受的 Cell 所包含,那么它就不能被任何先前接受的 Cell 所包含。
同理,如果当前候选的 Cell 包含了之前已经接受过检查的 Cell,那么之前已经在 output 里面的 Cell 也需要被丢弃掉。因为 output 维护的是一个连续的尾序列,前面也提到了 S2 Cell 是被排序了,所以这里就不能破坏它的连续性。这里对应的是上述代码中标2的地方。
最后代码中标3的地方是看是否最后三个单元格加上这个可以合并。 如果连续的3个 Cell 加上当前的 Cell 可以级联到最近的一个父节点上,我们就把它们三个用大的 Cell 替换掉。
经过 Normalize 这一步的“格式化”以后,输出的 Cell 都是有序且无冗余的 Cell。
7. Denormalize()
func (cu *CellUnion) Denormalize(minLevel, levelMod int) {
var denorm CellUnion
for _, id := range *cu {
level := id.Level()
newLevel := level
if newLevel < minLevel {
newLevel = minLevel
}
if levelMod > 1 {
newLevel += (maxLevel - (newLevel - minLevel)) % levelMod
if newLevel > maxLevel {
newLevel = maxLevel
}
}
if newLevel == level {
denorm = append(denorm, id)
} else {
end := id.ChildEndAtLevel(newLevel)
for ci := id.ChildBeginAtLevel(newLevel); ci != end; ci = ci.Next() {
denorm = append(denorm, ci)
}
}
}
*cu = denorm
}
Denormalize 这个函数实现很简单了,它是 normalize 的另一面(名称上虽然是反义)。这个函数是为了“规范” Cell 是否满足覆盖转换之前的几个预定条件:MinLevel、MaxLevel、LevelMOD、MaxCell。
所有 level 小于 minLevel 或者(level-minLevel)不是 levelMod 的倍数的任何 Cell 都会被它的孩子节点替换,直到满足这两个条件或者达到 maxLevel。
Denormalize 函数的意图是确保得到的结果能满足 minLevel 和 levelMod,最好也能满足 MaxCells。
到这里读者也应该清楚为何函数名叫 Denormalize 了吧,为了满足条件,它把大的 Cell 替换成了自己的孩子,小的 Cell,而 Normalize 正好相反,是把4个小的孩子 Cell 用它们直系父亲节点去替换。
分析到这里 FastCovering() 函数也就都分析完毕了。
8. adjustCellLevels()
在回到 initialCandidates() 函数中,在这个函数中 FastCovering() 之后还有一步操作,adjustCellLevels。
c.adjustCellLevels(&cells)
接下来就看看 adjustCellLevels 的具体实现。
func (c *coverer) adjustCellLevels(cells *CellUnion) {
if c.levelMod == 1 {
return
}
var out int
for _, ci := range *cells {
level := ci.Level()
newLevel := c.adjustLevel(level)
if newLevel != level {
ci = ci.Parent(newLevel)
}
if out > 0 && (*cells)[out-1].Contains(ci) {
continue
}
for out > 0 && ci.Contains((*cells)[out-1]) {
out--
}
(*cells)[out] = ci
out++
}
*cells = (*cells)[:out]
}
adjustCellLevels 是用来确保 level> minLevel 的所有 Cell 也能满足 levelMod,必要时可以用祖先替换它们。 小于 minLevel 的这些 Cell ,它们的 Level 的不会被修改(请参阅调整级别)。 最终得到的结果是标准化以确保不存在冗余单元的 CellUnion。
adjustCellLevels 和 Denormalize 有点类似,都是为了满足条件调整 CellUnion。但是两者调整的方向不同,Denormalize 是把 Cell 往孩子的方向替换,adjustCellLevels 是把 Cell 往父亲节点的方向替换。
func (c *coverer) adjustLevel(level int) int {
if c.levelMod > 1 && level > c.minLevel {
level -= (level - c.minLevel) % c.levelMod
}
return level
}
adjustLevel 意图是为了返回更小一级的 Level,以使其满足 levelMod 条件。 小于minLevel的 level 不受影响(因为这些 level 的单元最终会被 Denormalize 函数处理)。
(二). Denormalize
关于 Denormalize 的实现已经在上面分析过了。这里就不再分析了。
(三). 小结
用一张图来表示 Google S2 对整个空间区域覆盖算法实现的全流程:
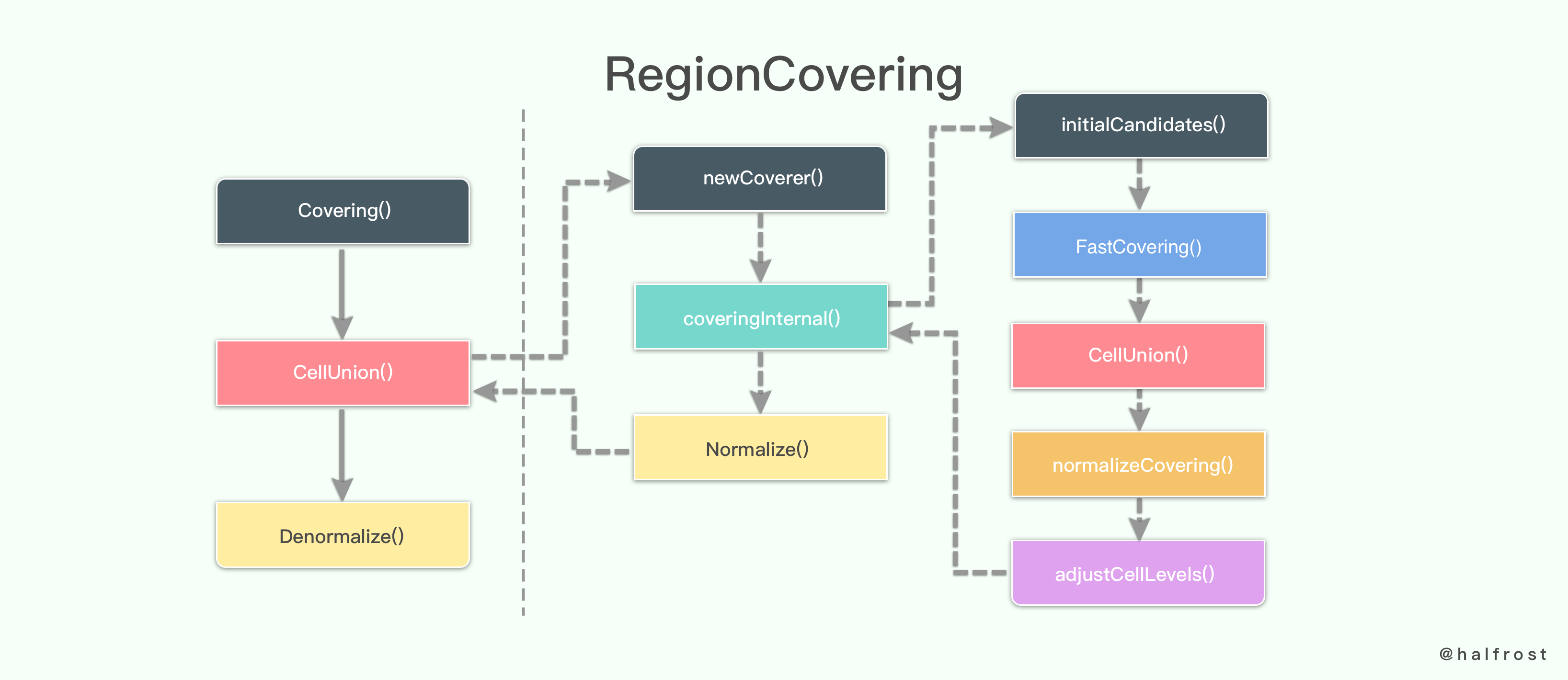
上图中每个关键实现都分析过了,哪个节点还不明白的同学可以回过头往上再翻一翻。
这个近似算法并不是最优算法,但是在实践中效果还不错。输出的结果并不总是使用的满足条件的最多的 Cell 个数,因为这样也不是总能产生更好的近似结果(比如上面举例的,待覆盖的区域整好位于三个面的交点处,得到的结果比原区域要大很多) 并且 MaxCells 对搜索的工作量和最终输出的 Cell 的数量是一种限制。
由于这是一个近似算法,所以不能依赖它输出的稳定性。特别的,覆盖算法的输出结果会在不同的库的版本上有所不同。
这个算法还可以产生内部覆盖的 Cell,内部覆盖的 Cell 指的是完全被包含在区域内的 Cell。如果没有满足条件的 Cell ,即使对于非空区域,内部覆盖 Cell 也可能是空的。
请注意,处于性能考虑,在计算内部覆盖 Cell 的时候,指定 MaxLevel 是明智的做法。否则,对于小的或者零面积的区域,算法可能会花费大量时间将 Cell 细分到叶子 level ,以尝试找到满足条件的内部覆盖的 Cell。
四. 最后

关于空间搜索系列文章到这里也告一段落了,最后当然说一些心得体会了。
在学习和实践空间搜索这块知识的时候,笔者我查看了物理,数学,算法这三方面的资料,从物理和数学2个层次提升了整个空间和时间的认知。虽然目前个人在这方面的认知也许还很浅显,不过对比之前实在是进步了很多。目的也达到了。
最后的最后就是推荐2个网站,这也是微博上提问问到最多的。
第一个问题是:系列文章里面的 S2 Cell 都是怎么画出来的?
这其实是一个人的开源网站,http://s2map.com/,笔者是在这里填入程序算好的 CellID,然后显示出来的。这就相当于是 S2 的可视化研究展示工具了。
第二个问题是:为什么有些代码在 Go 的版本里面没有找到相关实现?
答案是 Go 的版本实现完成度还没有到 100%,个别的还需要去参考 C++ 和 Java 完整版的代码。关于 C++ 和 Java 的源码,Google 已经在几天前把代码从私有代码仓库移到了 Github 上了。更加方便学习与查看了。官方也把一些文档整理到了 https://s2geometry.io/ 这个网站上。初学者建议还是先看官方 API 说明文档。在看完文档以后,原理性的问题还有些疑惑,可以来翻翻笔者这个空间搜索系列文章,希望能对读者有帮助。
空间搜索系列文章:
如何理解 n 维空间和 n 维时空
高效的多维空间点索引算法 — Geohash 和 Google S2
Google S2 中的 CellID 是如何生成的 ?
Google S2 中的四叉树求 LCA 最近公共祖先
神奇的德布鲁因序列
四叉树上如何求希尔伯特曲线的邻居 ?
Google S2 是如何解决空间覆盖最优解问题的?
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub



