作为 Go 并发原语的第一篇文章,一定绕不开 Go 的并发哲学。从 Tony Hoare 写的 Communicating Sequential Processes 这篇文章说起,这篇经典论文算是 Go 语言并发原语的根基。
一. What is CSP
CSP 的全程是 Communicating Sequential Processes,直译,通信顺序进程。这一概念起源自 1978 年 ACM 期刊中 Charles Antony Richard Hoare 写的经典同名论文。感兴趣的读者可以看 Reference 中的第一个链接看原文。在这篇文章中,Hoare 在文中用 CSP 来描述通信顺序进程能力,姑且认为这是一个虚构的编程语言。该语言描述了并发过程之间的交互作用。从历史上看,软件的进步主要依靠硬件的改进,这些改进可以使 CPU 更快,内存更大。Hoare 认识到,想通过硬件提高使得代码运行速度快 10 倍,需要付出 10 倍以上的机器资源。这并没有从根本改善问题。
1. 术语和一些例子
尽管并发相对于传统的顺序编程具有许多优势,但由于其会出错的性质,它未能获得广泛的欢迎。Hoare 借助 CSP 引入了一种精确的理论,可以在数学上保证程序摆脱并发的常见问题。Hoare 在他的 Learning CSP(这是计算机科学中引用第三多的神书!)一书中,使用“进程微积分”来表明可以处理死锁和不确定性,就像它们是普通进程中的最终事件一样。进程微积分是一种对并发系统进行数学化建模的方式,并且提供了代数法则来进行这些系统的变换来分析它们的不同属性,并发和效率。
为了防止数据被多线程破坏,Hoare 提出了临界区的概念。进程进入临界区后可以获得对共享数据的访问。在进入临界区之前,所有其他的进程必须验证和更新这一共享变量的值。退出临界区时,进程必须再次验证所有进程具有相同的值。
保持数据完整性的另一种技术是通过使用互斥信号量或互斥量。互斥锁是信号量的特定子类,它仅允许一个进程一次访问该变量。信号量是一个受限制的访问变量,它是防止并发中竞争的经典解决方案。其他尝试访问该互斥锁的进程将被阻止,并且必须等待直到当前进程释放该互斥锁。释放互斥锁后,只有一个等待的进程可以访问该变量,所有其他进程继续等待。
1970年代初期,Hoare 基于互斥量的概念开发了一种称为监视器的概念。根据 IBM 编写的 Java 编程语言 CSP 教程:
“A monitor is a body of code whose access is guarded by a mutex. Any process wishing to execute this code must acquire the associated mutex at the top of the code block and release it at the bottom. Because only one thread can own a mutex at a given time, this effectively ensures that only the owing thread can execute a monitor block of code.”
monitor 可以帮助防止数据被破坏和线程死锁。在 CSP 论文中为了说明清楚进程之间的通信,Hoare 利用 ?和 !号代表了输入和输出。!代表发送输入到一个进程,?号代表读取一个进程的输出。每个指令需要指定具体是一个输出变量(从一个进程中读取一个变量的情况),还是目的地(将输入发送到一个进程的情况)。一个进程的输出应该直接流向另一个进程的输入。

上图是从 CSP 文章中截图的一些例子,Hoare 简单的举了下面这个例子:
[c:character; west?c ~ east!c]
上述代码的意思是读取 west 输出的所有字符,然后把它们一个个的输出到 east 中。这个过程不断的重复,直到 west 终止。从描述上看,这一特性完完全全是 channel 的雏形。
2. 哲学家问题
文章的最后,回到了经典的哲学家问题。
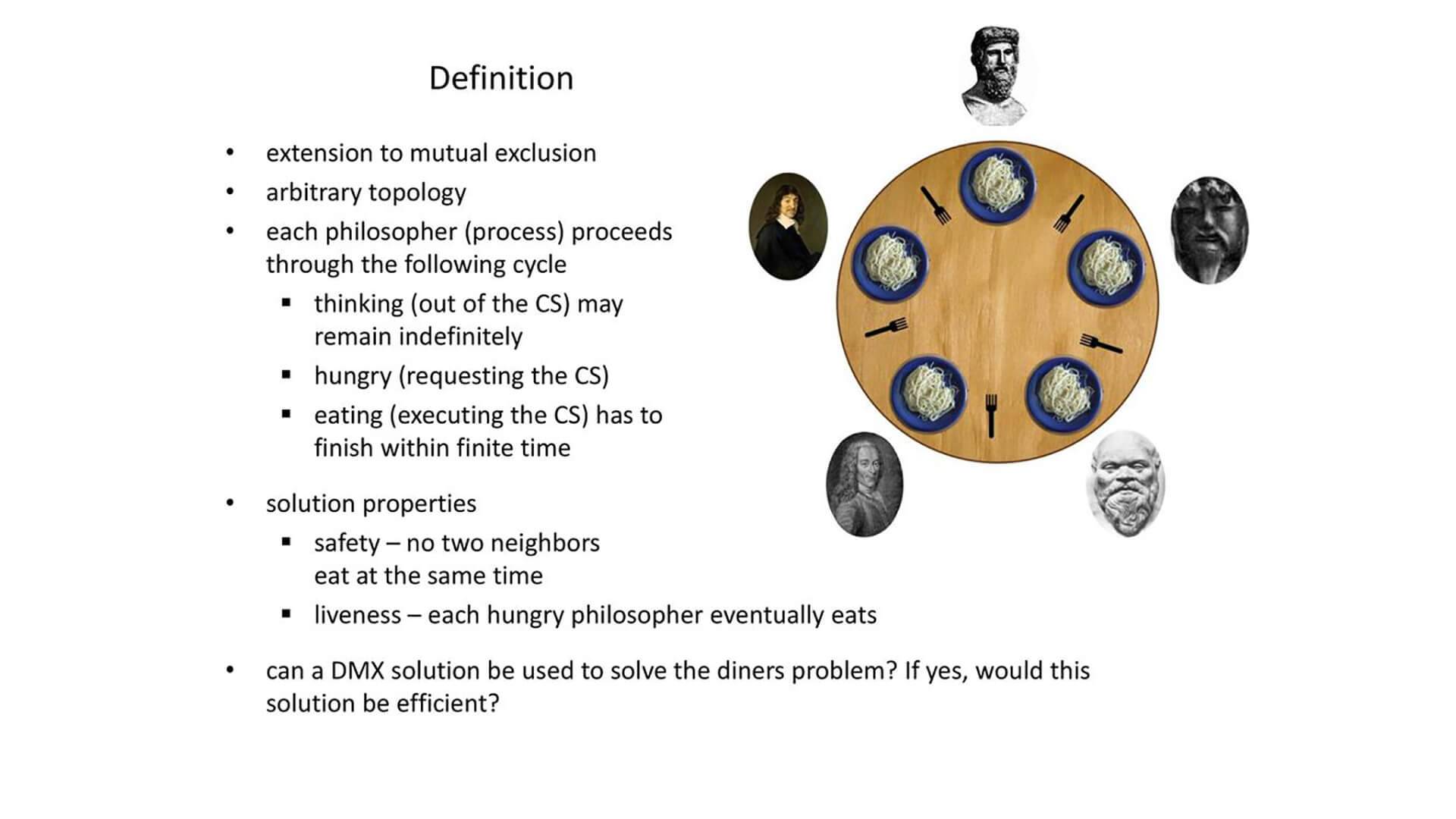
在哲学家问题中,Hoare 将 philosopher 的行为描述如下:
PHIL = *[... during ith lifetime ... --->,
THINK;
room!enter( );
fork(0!pickup( ); fork((/+ 1) rood 5)!pickup( );
EAT;
fork(i)!putdown( ); fork((/+ 1) mod 5)!putdown( );
room!exit( )
]
每个叉子由坐在两边的哲学家使用或者放下:
FORK =
*[phil(0?pickup( )--* phil(0?putdown( )
0phil((i - 1)rood 5)?pickup( ) --* phil((/- l) raod 5)?putdown( )
]
整个哲学家在房间中的行为可以描述为:
ROOM = occupancy:integer; occupancy .--- 0;
,[(i:0..4)phil(0?enter ( ) --* occupancy .--- occupancy + l
11(i:0..4)phil(0?exit ( ) --~ occupancy .--- occupancy - l
]
决定如何向等待的进程分配资源的任务称为调度。Hoare 将调度分为两个事件:
- processes 请求资源
- 将资源分配给 processes
那么这个哲学家问题可以转换成 PHIL 和 FORK 这两个组件并发的过程:
[room::ROOM I [fork( i:0..4)::FORK I Iphil( i:0..4)::PHIL].
从请求到授予资源的时间就是等待时间。在 CSP 中,有几种技术可以防止无限的等待时间。
- 限制资源使用并提高资源可用性。
- 先进先出(FIFO)将资源分配给等待时间最长的进程。
- 面包店算法Carnegie Melon. Bakery Algorithm
3. 缺陷
在确定性程序中,如果环境恒定,结果将是相同的。 由于并发基于非确定性,因此环境不会影响程序。给定所选的路径,程序则可以运行几次并收到不同的结果。为了确保并发程序的准确性,程序员必须能够在整体水平上考虑其程序的执行。
但是,尽管 Hoare 引入了正式的方法,但仍然缺少任何验证正确程序的证明方法。CSP 只能发现已知问题,而不能发现未知问题。虽然基于 CSP 的商业应用程序(例如ConAn)可以检测到错误的存在,但是不能检测没有错误的情况,(无法验证正确性)。尽管 CSP 为我们提供了编写可以避免常见并发错误的程序的工具,但是正确程序的证明仍然是 CSP 中尚未解决的领域。
4. 未来
CSP 在生物学和化学领域具有巨大的潜力,可以对自然界中的复杂系统进行建模。 由于该行业面临许多现存的逻辑问题,因此尚未在行业中广泛使用。在关于 CSP 开发 25 周年的会议上,Hoare 指出,尽管有许多由 Microsoft 资助的研究项目,但比尔·盖茨(Bill Gates)忽略了 Microsoft 何时能够将 CSP 的研究成果商业化的问题。
Hoare 提醒他的听众,动态过程领域仍然需要更多的研究。当前,计算机科学界陷入了顺序思维的范式。随着 Hoare 建立正式的并发方法的基础,科学界已做好准备成为并行编程的下一个革命。
5. Go 并发哲学
在 Go 语言发布之前,很少有语言从底层为并发原语提供支持。大多数语言还是支持共享和内存访问同步到 CSP 的消息传递方法。Go 语言算是最早将 CSP 原则纳入其核心的语言之一。内存访问同步的方式并不是不好,只是在高并发的场景下有时候难以正确的使用,特别是在超大型,巨型的程序中。基于此,并发能力被认为是 Go 语言天生优势之一。追其根本,还是因为 Go 基于 CSP 创造出来的一系列易读,方便编写的并发原语。
Go 语言除了 CSP 并发原语以外,还支持通过内存访问同步。sync 与其他包中的结构体与方法可以让开发者创建 WaitGroup,互斥锁和读写锁,cond,once,sync.Pool。在 Go 语言的官方 FAQ 中,描述了如何选择这些并发原语:
为了尊重 mutex,sync 包实现了 mutex,但是我们希望 Go 语言的编程风格将会激励人们尝试更高等级的技巧。尤其是考虑构建你的程序,以便一次只有一个 goroutine 负责某个特定的数据。
不要通过共享内存进行通信。建议,通过通信来共享内存。(Do not communicate by sharing memory; instead, share memory by communicating)这是 Go 语言并发的哲学座右铭。相对于使用 sync.Mutex 这样的并发原语。虽然大多数锁的问题可以通过 channel 或者传统的锁两种方式之一解决,但是 Go 语言核心团队更加推荐使用 CSP 的方式。
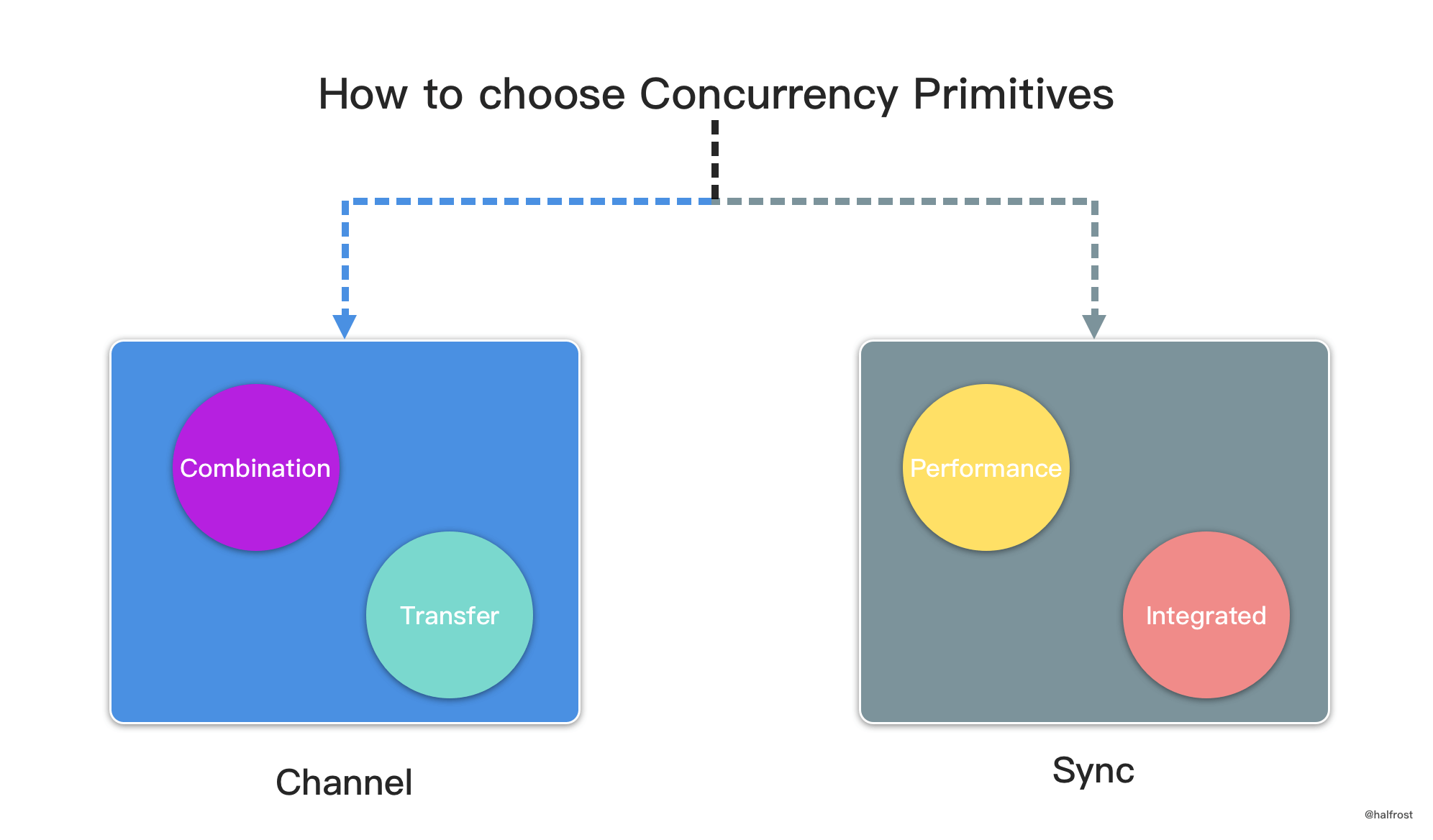
关于如何选择并发原语的问题,本文作为第一篇文章必然需要解释清楚。Go 中的并发原语主要分为 2 大类,一个是 sync 包里面的,另一个是 channel。sync 包里面主要是 WaitGroup,互斥锁和读写锁,cond,once,sync.Pool 这一类。在 2 种情况下推荐使用 sync 包:
- 对性能要求极高的临界区
- 保护某个结构内部状态和完整性
关于保护某个结构内部的状态和完整性。例如 Go 源码中如下代码:
var sum struct {
sync.Mutex
i int
}
//export Add
func Add(x int) {
defer func() {
recover()
}()
sum.Lock()
sum.i += x
sum.Unlock()
var p *int
*p = 2
}
sum 这个结构体不想将内部的变量暴露在结构体之外,所以使用 sync.Mutex 来保护线程安全。
相对于 sync 包,channel 也有 2 种情况:
- 输出数据给其他使用方
- 组合多个逻辑
输出数据给其他使用方的目的是转移数据的使用权。并发安全的实质是保证同时只有一个并发上下文拥有数据的所有权。channel 可以很方便的将数据所有权转给其他使用方。另一个优势是组合型。如果使用 sync 里面的锁,想实现组合多个逻辑并且保证并发安全,是比较困难的。但是使用 channel + select 实现组合逻辑实在太方便了。以上就是 CSP 的基本概念和何时选择 channel 的时机。下一章从 channel 基本数据结构开始详细分析 channel 底层源码实现。
以下代码基于 Go 1.16
二. 基本数据结构
channel 的底层源码和相关实现在 src/runtime/chan.go 中。
type hchan struct {
qcount uint // 队列中所有数据总数
dataqsiz uint // 环形队列的 size
buf unsafe.Pointer // 指向 dataqsiz 长度的数组
elemsize uint16 // 元素大小
closed uint32
elemtype *_type // 元素类型
sendx uint // 已发送的元素在环形队列中的位置
recvx uint // 已接收的元素在环形队列中的位置
recvq waitq // 接收者的等待队列
sendq waitq // 发送者的等待队列
lock mutex
}
lock 锁保护 hchan 中的所有字段,以及此通道上被阻塞的 sudogs 中的多个字段。持有 lock 的时候,禁止更改另一个 G 的状态(特别是不要使 G 状态变成ready),因为这会因为堆栈 shrinking 而发生死锁。
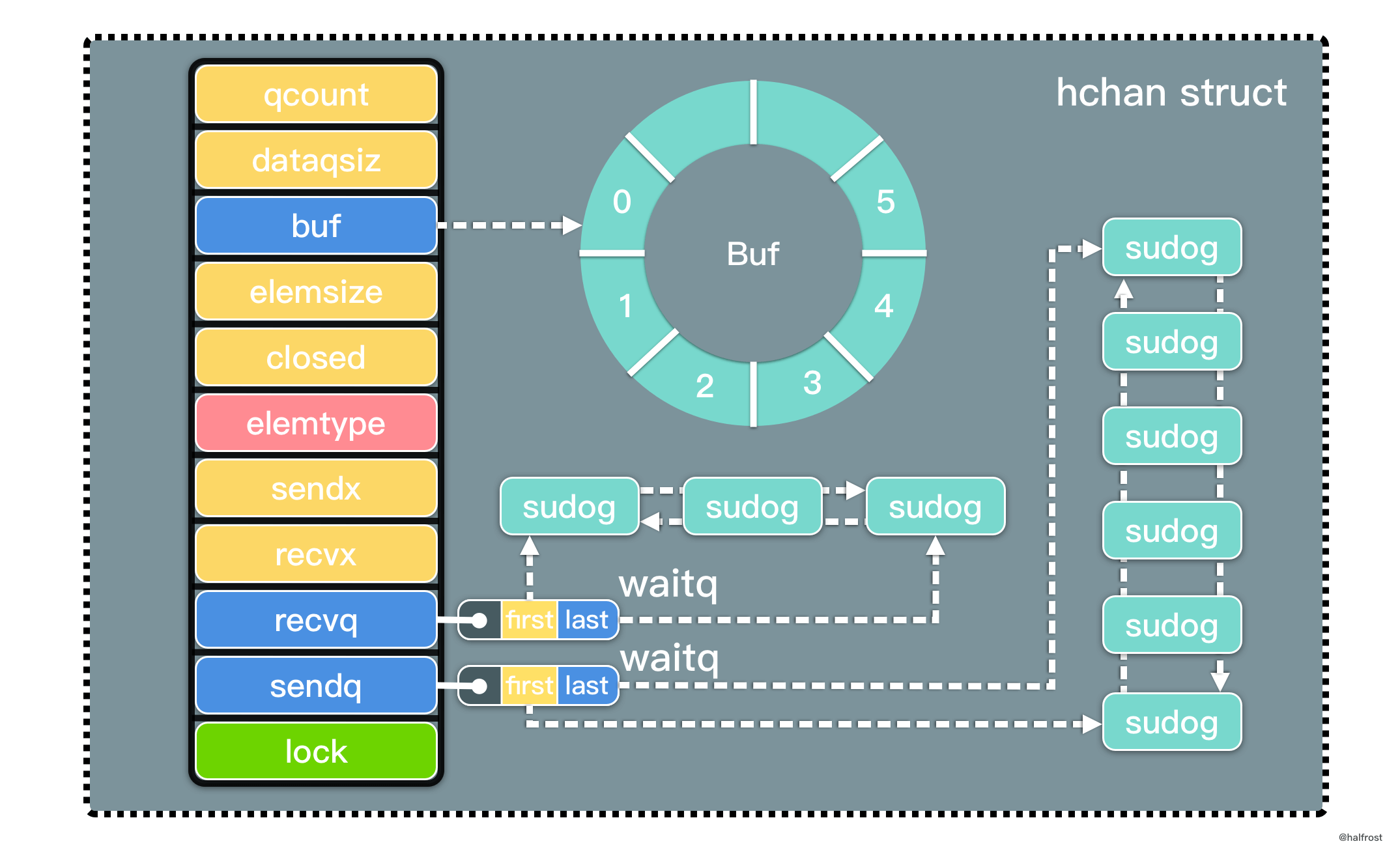
recvq 和 sendq 是等待队列,waitq 是一个双向链表:
type waitq struct {
first *sudog
last *sudog
}
channel 最核心的数据结构是 sudog。sudog 代表了一个在等待队列中的 g。sudog 是 Go 中非常重要的数据结构,因为 g 与同步对象关系是多对多的。一个 g 可以出现在许多等待队列上,因此一个 g 可能有很多sudog。并且多个 g 可能正在等待同一个同步对象,因此一个对象可能有许多 sudog。sudog 是从特殊池中分配出来的。使用 acquireSudog 和 releaseSudog 分配和释放它们。
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // 指向数据 (可能指向栈)
acquiretime int64
releasetime int64
ticket uint32
isSelect bool
success bool
parent *sudog // semaRoot 二叉树
waitlink *sudog // g.waiting 列表或者 semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
sudog 中所有字段都受 hchan.lock 保护。acquiretime、releasetime、ticket 这三个字段永远不会被同时访问。对 channel 来说,waitlink 只由 g 使用。对 semaphores 来说,只有在持有 semaRoot 锁的时候才能访问这三个字段。isSelect 表示 g 是否被选择,g.selectDone 必须进行 CAS 才能在被唤醒的竞争中胜出。success 表示 channel c 上的通信是否成功。如果 goroutine 在 channel c 上传了一个值而被唤醒,则为 true;如果因为 c 关闭而被唤醒,则为 false。
三. 创建 Channel
创建 channel 常见代码:
ch := make(chan int)
编译器编译上述代码,在检查 ir 节点时,根据节点 op 不同类型,进行不同的检查,如下源码:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
case ir.OMAKECHAN:
n := n.(*ir.MakeExpr)
return walkMakeChan(n, init)
......
}
编译器会检查每一种类型,walkExpr1() 的实现就是一个 switch-case,函数末尾没有 return,因为每一个 case 都会 return 或者返回 panic。这样做是为了与存在类型断言的情况中返回的内容做区分。walk 具体处理 OMAKECHAN 类型节点的逻辑如下:
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
size := n.Len
fnname := "makechan64"
argtype := types.Types[types.TINT64]
if size.Type().IsKind(types.TIDEAL) || size.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makechan"
argtype = types.Types[types.TINT]
}
return mkcall1(chanfn(fnname, 1, n.Type()), n.Type(), init, reflectdata.TypePtr(n.Type()), typecheck.Conv(size, argtype))
}
上述代码默认调用 makechan64() 函数。类型检查时如果 TIDEAL 大小在 int 范围内。将 TUINT 或 TUINTPTR 转换为 TINT 时出现大小溢出的情况,将在运行时在 makechan 中进行检查。如果在 make 函数中传入的 channel size 大小在 int 范围内,推荐使用 makechan()。因为 makechan() 在 32 位的平台上更快,用的内存更少。
makechan64() 和 makechan() 函数方法原型如下:
func makechan64(chanType *byte, size int64) (hchan chan any)
func makechan(chanType *byte, size int) (hchan chan any)
makechan64() 方法只是判断一下传入的入参 size 是否还在 int 范围之内:
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
创建 channel 的主要实现在 makechan() 函数中:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 编译器检查数据项大小不能超过 64KB
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 检查对齐是否正确
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 缓冲区大小检查,判断是否溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// 队列或者元素大小为 zero 时
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race 竞争检查利用这个地址来进行同步操作
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素不包含指针时。一次分配 hchan 和 buf 的内存。
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指针时
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 设置属性
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
上面这段 makechan() 代码主要目的是生成 *hchan 对象。重点关注 switch-case 中的 3 种情况:
- 当队列或者元素大小为 0 时,调用 mallocgc() 在堆上为 channel 开辟一段大小为 hchanSize 的内存空间。
- 当元素类型不是指针类型时,调用 mallocgc() 在堆上开辟为 channel 和底层 buf 缓冲区数组开辟一段大小为 hchanSize + mem 连续的内存空间。
- 默认情况元素类型中有指针类型,调用 mallocgc() 在堆上分别为 channel 和 buf 缓冲区分配内存。
完成第一步的内存分配之后,再就是 hchan 数据结构其他字段的初始化和 lock 的初始化。值得说明的一点是,当存储在 buf 中的元素不包含指针时,Hchan 中也不包含 GC 关心的指针。buf 指向一段相同元素类型的内存,elemtype 固定不变。SudoG 是从它们自己的线程中引用的,因此垃圾回收的时候无法回收它们。受到垃圾回收器的限制,指针类型的缓冲 buf 需要单独分配内存。官方在这里加了一个 TODO,垃圾回收的时候这段代码逻辑需要重新考虑。
就是因为 channel 的创建全部调用的 mallocgc(),在堆上开辟的内存空间,channel 本身会被 GC 自动回收。有了这一性质,所以才有了下文关闭 channel 中优雅关闭的方法。
四. 发送数据
向 channel 中发送数据常见代码:
ch <- 1
编译器编译上述代码,在检查 ir 节点时,根据节点 op 不同类型,进行不同的检查,如下源码:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
case ir.OSEND:
n := n.(*ir.SendStmt)
return walkSend(n, init)
......
}
walkExpr1() 函数在创建 channel 提到了,这里不再赘述。操作类型是 OSEND,对应调用 walkSend() 函数:
func walkSend(n *ir.SendStmt, init *ir.Nodes) ir.Node {
n1 := n.Value
n1 = typecheck.AssignConv(n1, n.Chan.Type().Elem(), "chan send")
n1 = walkExpr(n1, init)
n1 = typecheck.NodAddr(n1)
return mkcall1(chanfn("chansend1", 2, n.Chan.Type()), nil, init, n.Chan, n1)
}
// entry point for c <- x from compiled code
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
walkSend() 函数中主要逻辑调用了 chansend1(),而 chansend1() 只是 chansend() 的“外壳”。所以 channel 发送数据的核心实现在 chansend() 中。根据 channel 的阻塞和唤醒,又可以分为 2 部分逻辑代码。接下来笔者讲 chansend() 代码拆成 4 部分详细分析。
1. 异常检查
chansend() 函数一开始先进行异常检查:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 判断 channel 是否为 nil
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, funcPC(chansend))
}
// 简易快速的检查
if !block && c.closed == 0 && full(c) {
return false
}
......
}
chansend() 一上来对 channel 进行检查,如果被 GC 回收了会变为 nil。朝一个为 nil 的 channel 发送数据会发生阻塞。gopark 会引发以 waitReasonChanSendNilChan 为原因的休眠,并抛出 unreachable 的 fatal error。当 channel 不为 nil,再开始检查在没有获取锁的情况下会导致发送失败的非阻塞操作。
当 channel 不为 nil,并且 channel 没有 close 时,还需要检查此时 channel 是否做好发送的准备,即判断 full(c)
func full(c *hchan) bool {
if c.dataqsiz == 0 {
// 假设指针读取是近似原子性的
return c.recvq.first == nil
}
// 假设读取 uint 是近似原子性的
return c.qcount == c.dataqsiz
}
full() 方法作用是判断在 channel 上发送是否会阻塞(即通道已满)。它读取单个字节大小的可变状态(recvq.first 和 qcount),尽管答案可能在一瞬间是 true,但在调用函数收到返回值时,正确的结果可能发生了更改。值得注意的是 dataqsiz 字段,它在创建完 channel 以后是不可变的,因此它可以安全的在任意时刻读取。
回到 chansend() 异常检查中。一个已经 close 的 channel 是不可能从“准备发送”的状态变为“未准备好发送”的状态。所以在检查完 channel 是否 close 以后,就算 channel close 了,也不影响此处检查的结果。可能有读者疑惑,“能不能把检查顺序倒一倒?先检查是否 full(),再检查是否 close?”。这样倒过来确实能保证检查 full() 的时候,channel 没有 close。但是这种做法也没有实质性的改变。channel 依旧可以在检查完 close 以后再关闭。其实我们依赖的是 chanrecv() 和 closechan() 这两个方法在锁释放后,它们更新这个线程 c.close 和 full() 的结果视图。
2. 同步发送
channel 异常状态检查以后,接下来的代码是发送的逻辑。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
......
}
在发送之前,先上锁,保证线程安全。并再一次检查 channel 是否关闭。如果关闭则抛出 panic。加锁成功并且 channel 未关闭,开始发送。如果有正在阻塞等待的接收方,通过 dequeue() 取出头部第一个非空的 sudog,调用 send() 函数:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
send() 函数主要完成了 2 件事:
-
- 调用 sendDirect() 函数将数据拷贝到了接收变量的内存地址上
-
- 调用 goready() 将等待接收的阻塞 goroutine 的状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable。下一轮调度时会唤醒这个接收的 goroutine。
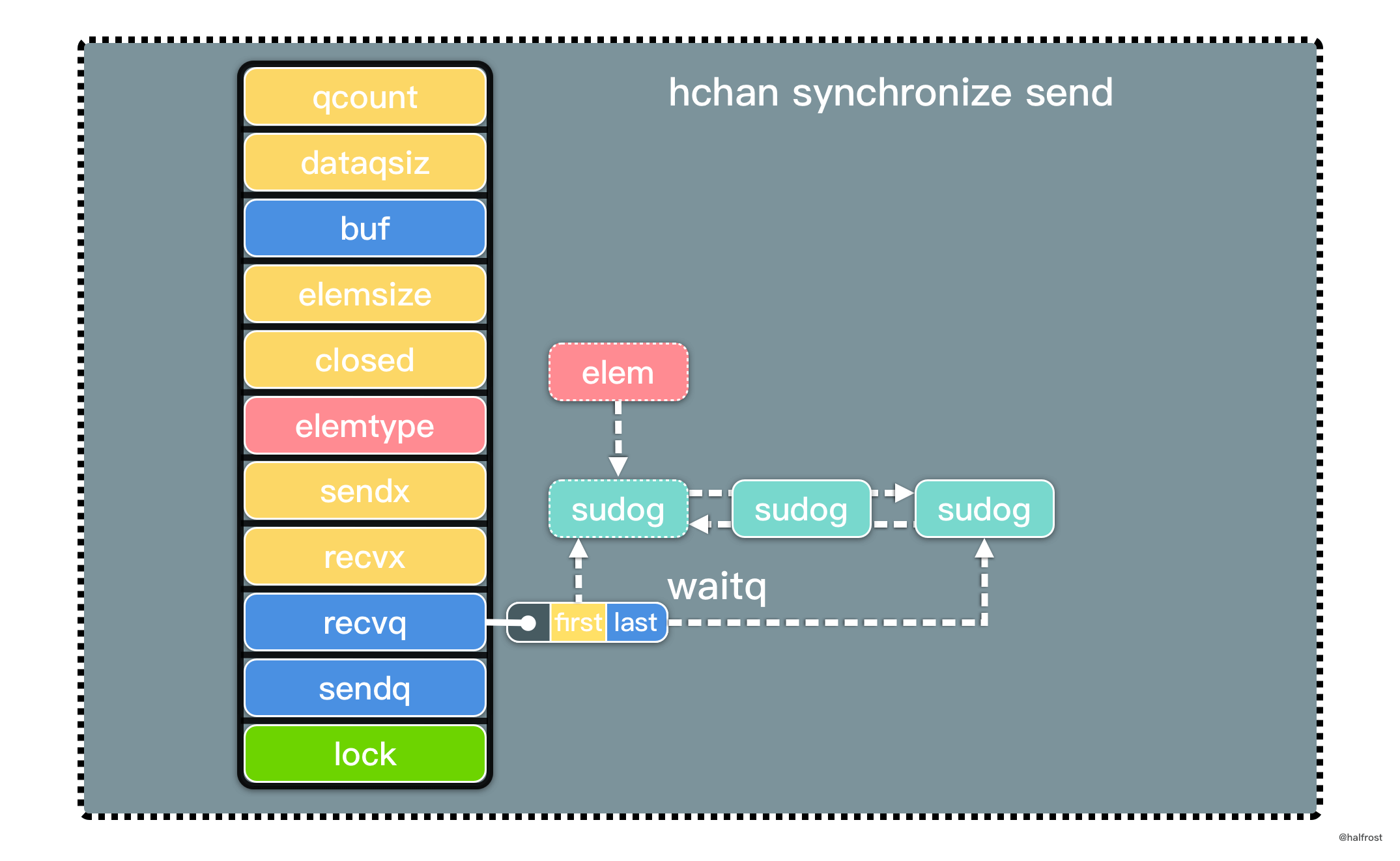
这里重点说说 goready() 的实现。理解了它的源码,就能明白为什么往 channel 中发送数据并非立即可以从接收方获取到。
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
func ready(gp *g, traceskip int, next bool) {
......
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(_g_.m.p.ptr(), gp, next)
wakep()
releasem(mp)
}
在 runqput() 函数的作用是把 g 绑定到本地可运行的队列中。此处 next 传入的是 true,将 g 插入到 runnext 插槽中,等待下次调度便立即运行。因为这一点导致了虽然 goroutine 保证了线程安全,但是在读取数据方面比数组慢了几百纳秒。
| Read | Channel | Slice |
|---|---|---|
| Time | x * 100 * nanosecond | 0 |
| Thread safe | Yes | No |
所以在写测试用例的某些时候,需要考虑到这个微弱的延迟,可以适当加 sleep()。再比如刷 LeetCode 题目的时候,并非无脑使用 goroutine 就能带来 runtime 的提升,例如 509. Fibonacci Number,感兴趣的同学可以用 goroutine 来写一写这道题,笔者这里实现了goroutine 解法,性能方面完全不如数组的解法。
3. 异步发送
如果初始化 channel 时创建的带缓冲区的异步 Channel,当接收者队列为空时,这是会进入到异步发送逻辑:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
......
}
如果 qcount 还没有满,则调用 chanbuf() 获取 sendx 索引的元素指针值。调用 typedmemmove() 方法将发送的值拷贝到缓冲区 buf 中。拷贝完成,需要维护 sendx 索引下标值和 qcount 个数。这里将 buf 缓冲区设计成环形的,索引值如果到了队尾,下一个位置重新回到队头。
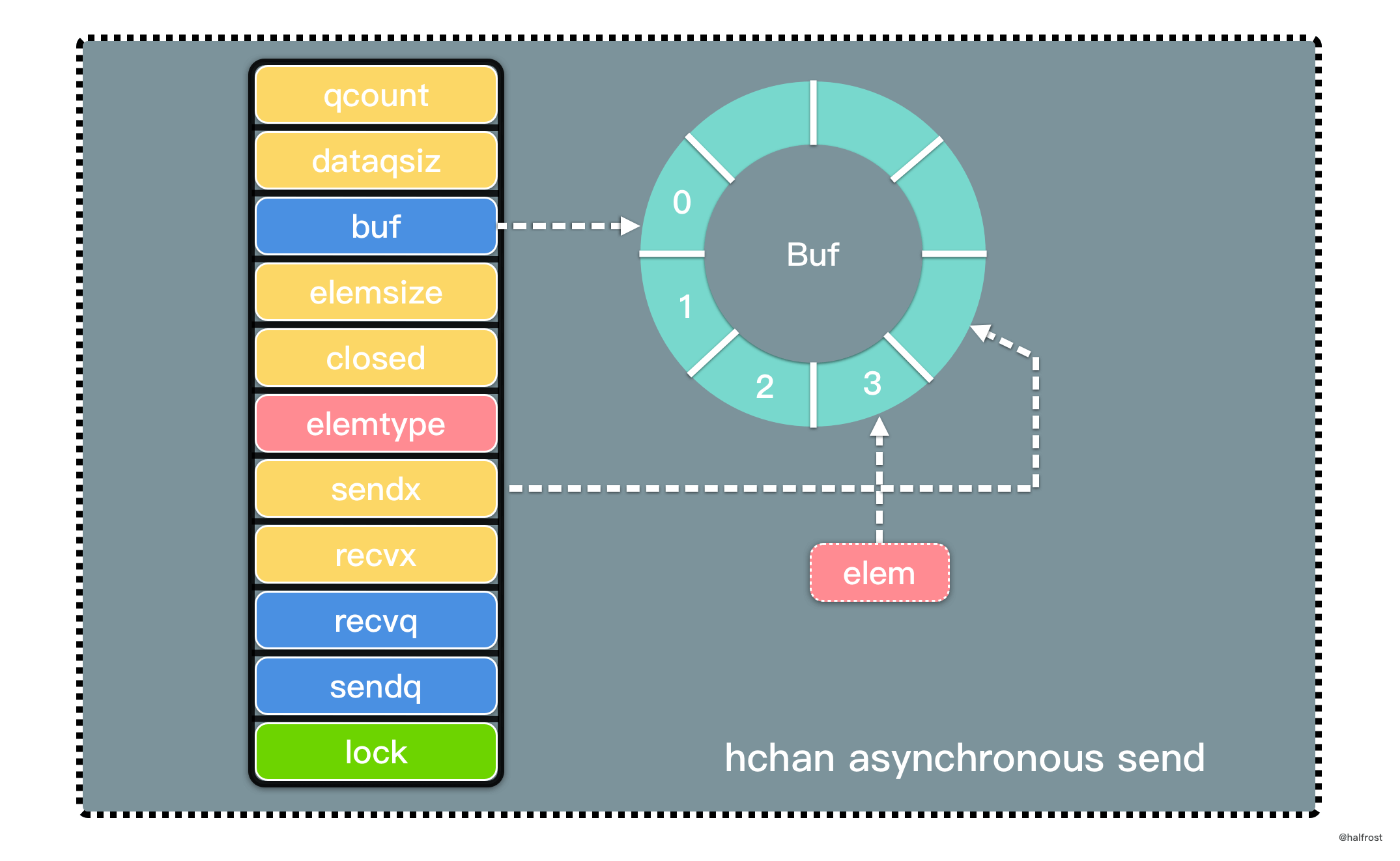
至此,两种直接发送的逻辑分析完了,接下来是发送时 channel 阻塞的情况。
4. 阻塞发送
当 channel 处于打开状态,但是没有接收者,并且没有 buf 缓冲队列或者 buf 队列已满,这时 channel 会进入阻塞发送。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if !block {
unlock(&c.lock)
return false
}
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
KeepAlive(ep)
......
}
- 调用 getg() 方法获取当前 goroutine 的指针,用于绑定给一个 sudog。
- 调用 acquireSudog() 方法获取一个 sudog,可能是新建的 sudog,也有可能是从缓存中获取的。设置好 sudog 要发送的数据和状态。比如发送的 Channel、是否在 select 中和待发送数据的内存地址等等。
- 调用 c.sendq.enqueue 方法将配置好的 sudog 加入待发送的等待队列。
- 设置原子信号。当栈要 shrink 收缩时,这个标记代表当前 goroutine 还 parking 停在某个 channel 中。在 g 状态变更与设置 activeStackChans 状态这两个时间点之间的时间窗口进行栈 shrink 收缩是不安全的,所以需要设置这个原子信号。
- 调用 gopark 方法挂起当前 goroutine,状态为 waitReasonChanSend,阻塞等待 channel。
- 最后,KeepAlive() 确保发送的值保持活动状态,直到接收者将其复制出来。 sudog 具有指向堆栈对象的指针,但 sudog 不能被当做堆栈跟踪器的 root。发送的数值是分配在堆上,这样可以避免被 GC 回收。
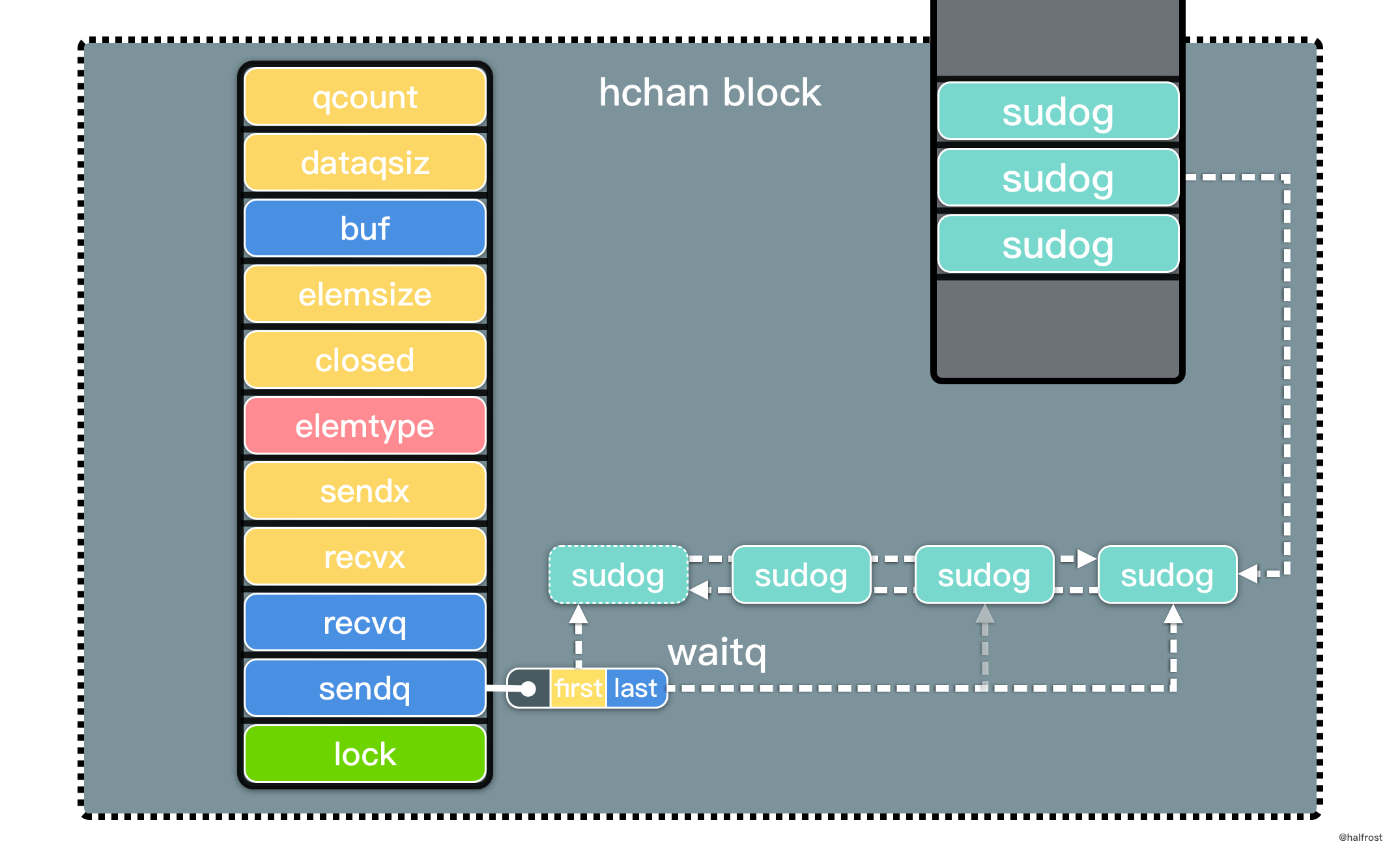
这里提一下 sudog 的二级缓存复用体系。在 acquireSudog() 方法中:
func acquireSudog() *sudog {
mp := acquirem()
pp := mp.p.ptr()
// 如果本地缓存为空
if len(pp.sudogcache) == 0 {
lock(&sched.sudoglock)
// 首先尝试将全局中央缓存存一部分到本地
for len(pp.sudogcache) < cap(pp.sudogcache)/2 && sched.sudogcache != nil {
s := sched.sudogcache
sched.sudogcache = s.next
s.next = nil
pp.sudogcache = append(pp.sudogcache, s)
}
unlock(&sched.sudoglock)
// 如果全局中央缓存是空的,则 allocate 一个新的
if len(pp.sudogcache) == 0 {
pp.sudogcache = append(pp.sudogcache, new(sudog))
}
}
// 从尾部提取,并调整本地缓存
n := len(pp.sudogcache)
s := pp.sudogcache[n-1]
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
if s.elem != nil {
throw("acquireSudog: found s.elem != nil in cache")
}
releasem(mp)
return s
}
上述代码涉及到 2 个新的重要的结构体,由于这 2 个结构体特别复杂,暂时此处只展示和 acquireSudog() 有关的部分:
type p struct {
......
sudogcache []*sudog
sudogbuf [128]*sudog
......
}
type schedt struct {
......
sudoglock mutex
sudogcache *sudog
......
}
sched.sudogcache 是全局中央缓存,可以认为它是“一级缓存”,它会在 GC 垃圾回收执行 clearpools 被清理。p.sudogcache 可以认为它是“二级缓存”,是本地缓存不会被 GC 清理掉。
chansend 最后的代码逻辑是当 goroutine 唤醒以后,解除阻塞的状态:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}
sudog 算是对 g 的一种封装,里面包含了 g,要发送的数据以及相关的状态。goroutine 被唤醒后会完成 channel 的阻塞数据发送。发送完最后进行基本的参数检查,解除 channel 的绑定并释放 sudog。
func releaseSudog(s *sudog) {
if s.elem != nil {
throw("runtime: sudog with non-nil elem")
}
if s.isSelect {
throw("runtime: sudog with non-false isSelect")
}
if s.next != nil {
throw("runtime: sudog with non-nil next")
}
if s.prev != nil {
throw("runtime: sudog with non-nil prev")
}
if s.waitlink != nil {
throw("runtime: sudog with non-nil waitlink")
}
if s.c != nil {
throw("runtime: sudog with non-nil c")
}
gp := getg()
if gp.param != nil {
throw("runtime: releaseSudog with non-nil gp.param")
}
// 防止 rescheduling 到了其他的 P
mp := acquirem()
pp := mp.p.ptr()
// 如果本地缓存已满
if len(pp.sudogcache) == cap(pp.sudogcache) {
// 转移一半本地缓存到全局中央缓存中
var first, last *sudog
for len(pp.sudogcache) > cap(pp.sudogcache)/2 {
n := len(pp.sudogcache)
p := pp.sudogcache[n-1]
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
if first == nil {
first = p
} else {
last.next = p
}
last = p
}
lock(&sched.sudoglock)
// 将提取的链表挂载到全局中央缓存中
last.next = sched.sudogcache
sched.sudogcache = first
unlock(&sched.sudoglock)
}
pp.sudogcache = append(pp.sudogcache, s)
releasem(mp)
}
releaseSudog() 虽然释放了 sudog 的内存,但是它会被 p.sudogcache 这个“二级缓存”缓存起来。
chansend() 函数最后返回 true 表示成功向 Channel 发送了数据。
5. 小结
关于 channel 发送的源码实现已经分析完了,针对 channel 各个状态做一个小结。
| Channel Status | Result | |
|---|---|---|
| Write | nil | 阻塞 |
| Write | 打开但填满 | 阻塞 |
| Write | 打开但未满 | 成功写入值 |
| Write | 关闭 | panic |
| Write | 只读 | Compile Error |
channel 发送过程中包含 2 次有关 goroutine 调度过程:
-
- 当接收队列中存在 sudog 可以直接发送数据时,执行
goready()将 g 插入 runnext 插槽中,状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable,等待下次调度便立即运行。
- 当接收队列中存在 sudog 可以直接发送数据时,执行
-
- 当 channel 阻塞时,执行
gopark()将 g 阻塞,让出 cpu 的使用权。
- 当 channel 阻塞时,执行
需要强调的是,通道并不提供跨 goroutine 的数据访问保护机制。如果通过通道传输数据的一份副本,那么每个 goroutine 都持有一份副本,各自对自己的副本做修改是安全的。当传输的是指向数据的指针时,如果读和写是由不同的 goroutine 完成的,那么每个 goroutine 依旧需要额外的同步操作。
五. 接收数据
从 channel 中接收数据常见代码:
tmp := <-ch
tmp, ok := <-ch
先看等号左边赋值一个值的情况,编译器编译上述代码,在检查 ir 节点时,根据节点 op 不同类型,进行不同的检查,如下源码:
// walkAssign walks an OAS (AssignExpr) or OASOP (AssignOpExpr) node.
func walkAssign(init *ir.Nodes, n ir.Node) ir.Node {
......
switch as.Y.Op() {
default:
as.Y = walkExpr(as.Y, init)
case ir.ORECV:
// x = <-c; as.Left is x, as.Right.Left is c.
// order.stmt made sure x is addressable.
recv := as.Y.(*ir.UnaryExpr)
recv.X = walkExpr(recv.X, init)
n1 := typecheck.NodAddr(as.X)
r := recv.X // the channel
return mkcall1(chanfn("chanrecv1", 2, r.Type()), nil, init, r, n1)
......
}
as 是入参 ir 节点强制转化成 AssignStmt 类型。AssignStmt 这个类型是赋值的一个说明:
type AssignStmt struct {
miniStmt
X Node
Def bool
Y Node
}
Y 是等号右边的值,它是 Node 类型,里面包含 op 类型。walkAssign 是检查赋值语句,如果 Y.Op() 是 ir.ORECV 类型,说明是 channel 接收的过程。调用 chanrecv1() 函数。as.X 是赋值语句左边的元素,它是接收 channel 中的值,所以它必须是可寻址的。
当从 channel 中读取数据等号左边是 2 个值的时候,编译器在 walkExpr1 中检查这个赋值语句:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
......
case ir.OAS2RECV:
n := n.(*ir.AssignListStmt)
return walkAssignRecv(init, n)
......
}
n.Op() 是 ir.OAS2RECV 类型,将 n 强转成 AssignListStmt 类型:
type AssignListStmt struct {
miniStmt
Lhs Nodes
Def bool
Rhs Nodes
}
AssignListStmt 和 AssignStmt 作用一样,只是 AssignListStmt 表示等号两边赋值语句不再是一个对象,而是多个。回到 walkExpr1() 中,如果是 ir.OAS2RECV 类型,调用 walkAssignRecv() 继续检查。
func walkAssignRecv(init *ir.Nodes, n *ir.AssignListStmt) ir.Node {
init.Append(ir.TakeInit(n)...)
r := n.Rhs[0].(*ir.UnaryExpr) // recv
walkExprListSafe(n.Lhs, init)
r.X = walkExpr(r.X, init)
var n1 ir.Node
if ir.IsBlank(n.Lhs[0]) {
n1 = typecheck.NodNil()
} else {
n1 = typecheck.NodAddr(n.Lhs[0])
}
fn := chanfn("chanrecv2", 2, r.X.Type())
ok := n.Lhs[1]
call := mkcall1(fn, types.Types[types.TBOOL], init, r.X, n1)
return typecheck.Stmt(ir.NewAssignStmt(base.Pos, ok, call))
}
Lhs[0] 是实际接收 channel 值的对象,Lhs[1] 是赋值语句左边第二个 bool 值。赋值语句右边由于只有一个 channel,所以这里 Rhs 也只用到了 Rhs[0]。
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
综合上述的分析,2 种不同的 channel 接收方式会转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是最终核心逻辑还是在 runtime.chanrecv 中。
1. 异常检查
chanrecv() 函数一开始先进行异常检查:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if debugChan {
print("chanrecv: chan=", c, "\n")
}
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 简易快速的检查
if !block && empty(c) {
if atomic.Load(&c.closed) == 0 {
return
}
if empty(c) {
// channel 不可逆的关闭了且为空
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
chanrecv() 一上来对 channel 进行检查,如果被 GC 回收了会变为 nil。从一个为 nil 的 channel 中接收数据会发生阻塞。gopark 会引发以 waitReasonChanReceiveNilChan 为原因的休眠,并抛出 unreachable 的 fatal error。当 channel 不为 nil,再开始检查在没有获取锁的情况下会导致接收失败的非阻塞操作。
这里进行的简易快速的检查,检查中状态不能发生变化。这一点和 chansend() 函数有区别。在 chansend() 简易快速的检查中,改变顺序对检查结果无太大影响,但是此处如果检查过程中状态发生变化,如果发生了 racing,检查结果会出现完全相反的错误的结果。例如以下这种情况:channel 在第一个和第二个 if 检查时是打开的且非空,于是在第二个 if 里面 return。但是 return 的瞬间, channel 关闭且空。这样判断出来认为 channel 是打开的且非空。明显是错误的结果,实际上 channel 是关闭且空的。同理检查是否为空的时候也会发生状态反转。为了防止错误的检查结果,c.closed 和 empty() 都必须使用原子检查。
func empty(c *hchan) bool {
// c.dataqsiz 是不可变的
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}
这里总共检查了 2 次 empty(),因为第一次检查时, channel 可能还没有关闭,但是第二次检查的时候关闭了,在 2 次检查之间可能有待接收的数据到达了。所以需要 2 次 empty() 检查。
不过就算按照上述源码检查,细心的读者可能还会举出一个反例,例如,关闭一个已经阻塞的同步的 channel,最开始的 !block && empty(c) 为 false,会跳过这个检查。这种情况不能算在正常 chanrecv() 里面。上述是不获取锁的情况检查会接收失败的情况。接下来在获取锁的情况下再次检查一遍异常情况。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
......
如果 channel 已经关闭且不存在缓存数据了,则清理 ep 指针中的数据并返回。这里也是从已经关闭的 channel 中读数据,读出来的是该类型零值的原因。
2. 同步接收
同 chansend 逻辑类似,检查完异常情况,紧接着是同步接收。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
......
在 channel 的发送队列中找到了等待发送的 goroutine。取出队头等待的 goroutine。如果缓冲区的大小为 0,则直接从发送方接收值。否则,对应缓冲区满的情况,从队列的头部接收数据,发送者的值添加到队列的末尾(此时队列已满,因此两者都映射到缓冲区中的同一个下标)。同步接收的核心逻辑见下面 recv() 函数:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// 从 sender 里面拷贝数据
recvDirect(c.elemtype, sg, ep)
}
} else {
// 这里对应 buf 满的情况
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// 将数据从 buf 中拷贝到接收者内存地址中
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 将数据从 sender 中拷贝到 buf 中
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
需要注意的是由于有发送者在等待,所以如果存在缓冲区,那么缓冲区一定是满的。这个情况对应发送阶段阻塞发送的情况,如果缓冲区还有空位,发送的数据直接放入缓冲区,只有当缓冲区满了,才会打包成 sudog,插入到 sendq 队列中等待调度。注意理解这一情况。
接收时主要分为 2 种情况,有缓冲且 buf 满和无缓冲的情况:
- 无缓冲。ep 发送数据不为 nil,调用 recvDirect() 将发送队列中 sudog 存储的 ep 数据直接拷贝到接收者的内存地址中。
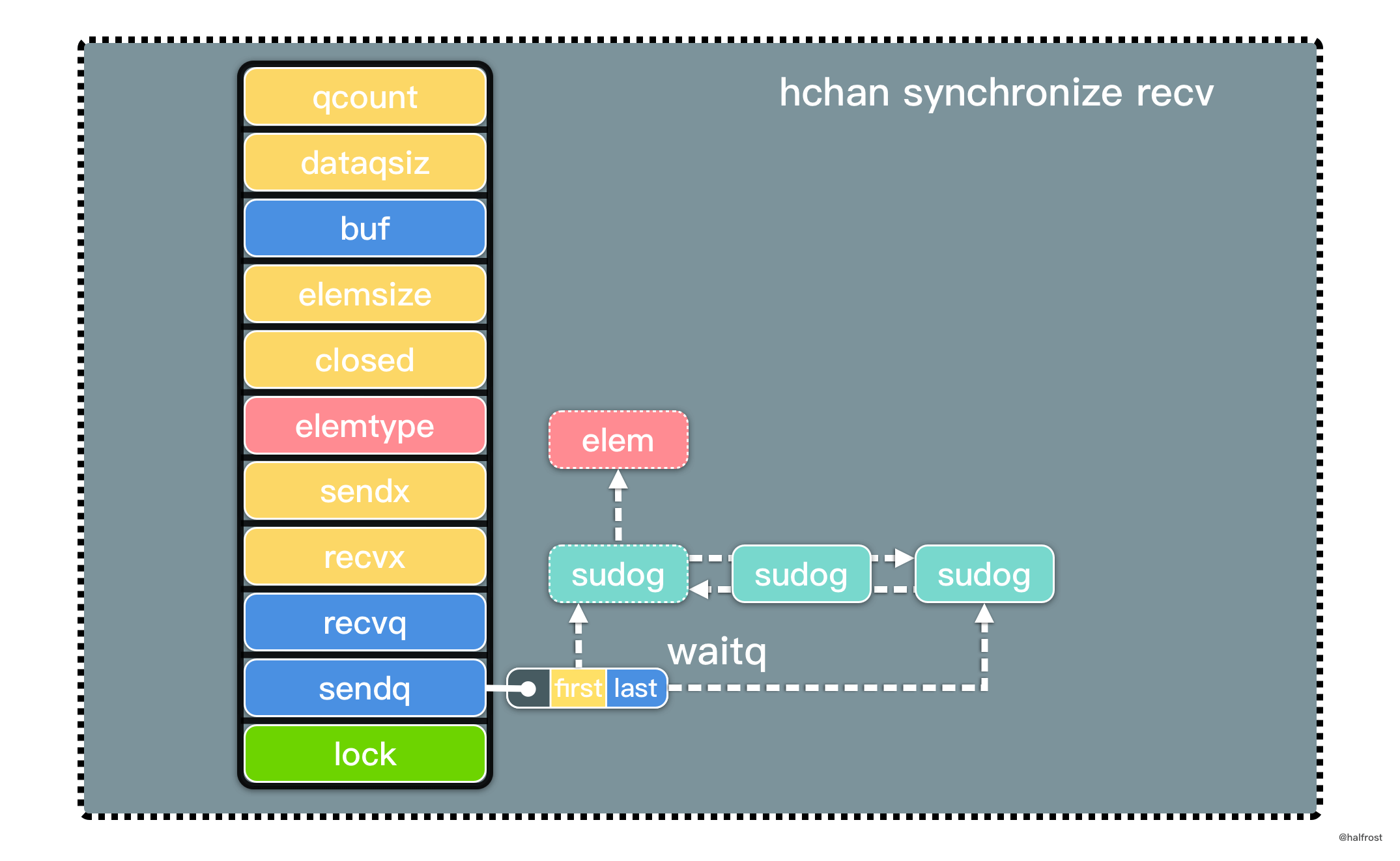
-
有缓冲并且 buf 满。有 2 次 copy 操作,先将队列中 recvx 索引下标的数据拷贝到接收方的内存地址,再将发送队列头的数据拷贝到缓冲区中,释放一个 sudog 阻塞的 goroutine。
有缓冲且 buf 满的情况需要注意,取数据从缓冲队列头取出,发送的数据放在队列尾部,由于 buf 装满,取出的 recvx 指针和发送的 sendx 指针指向相同的下标。
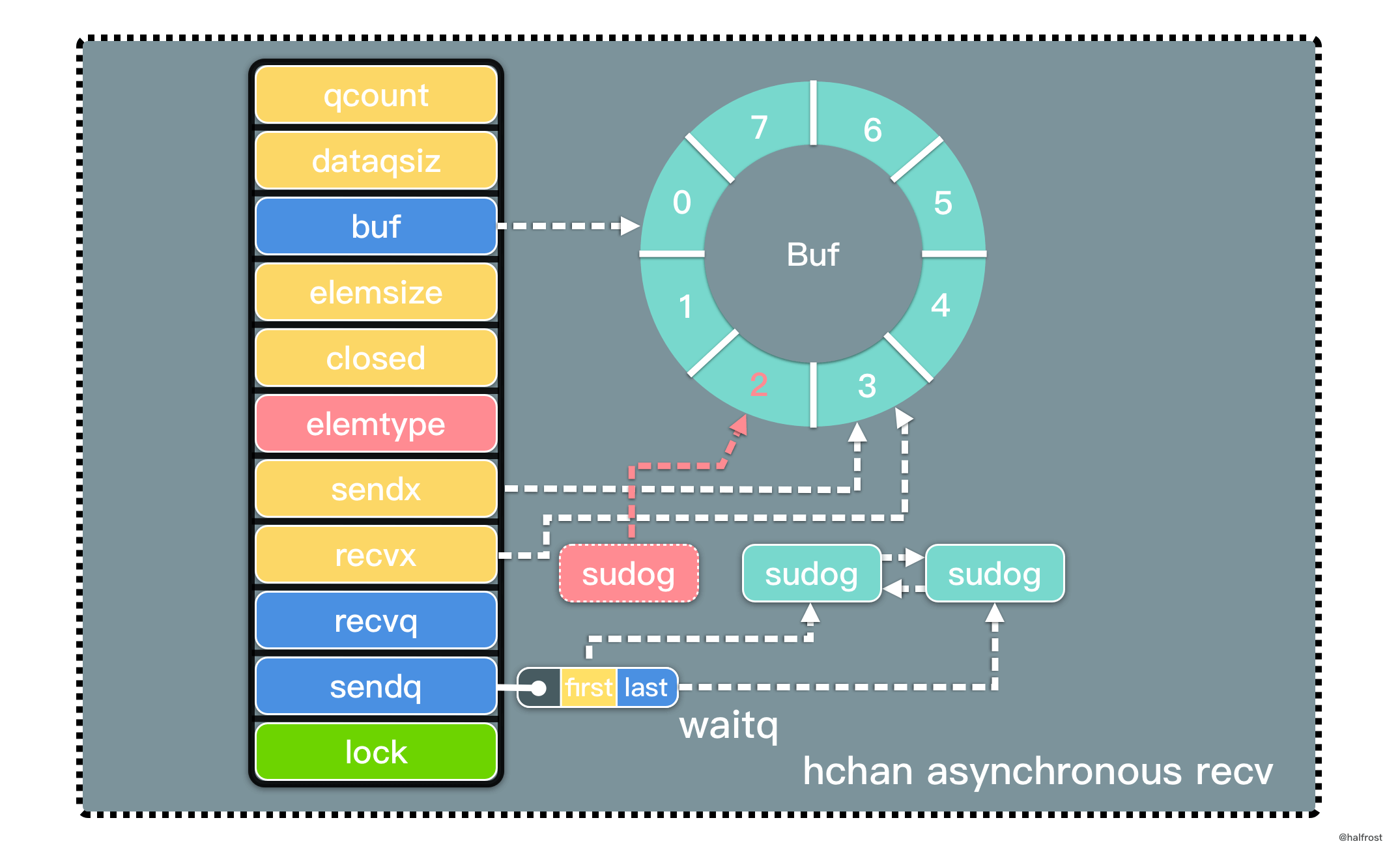
最后调用 goready() 将等待接收的阻塞 goroutine 的状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable。下一轮调度时会唤醒这个发送的 goroutine。这部分逻辑和同步发送中一致,关于 goready() 底层实现的代码不在赘述。
3. 异步接收
如果 Channel 的缓冲区中包含一些数据时,从 Channel 中接收数据会直接从缓冲区中 recvx 的索引位置中取出数据进行处理:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
if c.qcount > 0 {
// 直接从队列中接收
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
......
上述代码比较简单,如果接收数据的内存地址 ep 不为空,则调用 runtime.typedmemmove() 将缓冲区内的数据拷贝到内存中,并通过 typedmemclr() 清除队列中的数据。
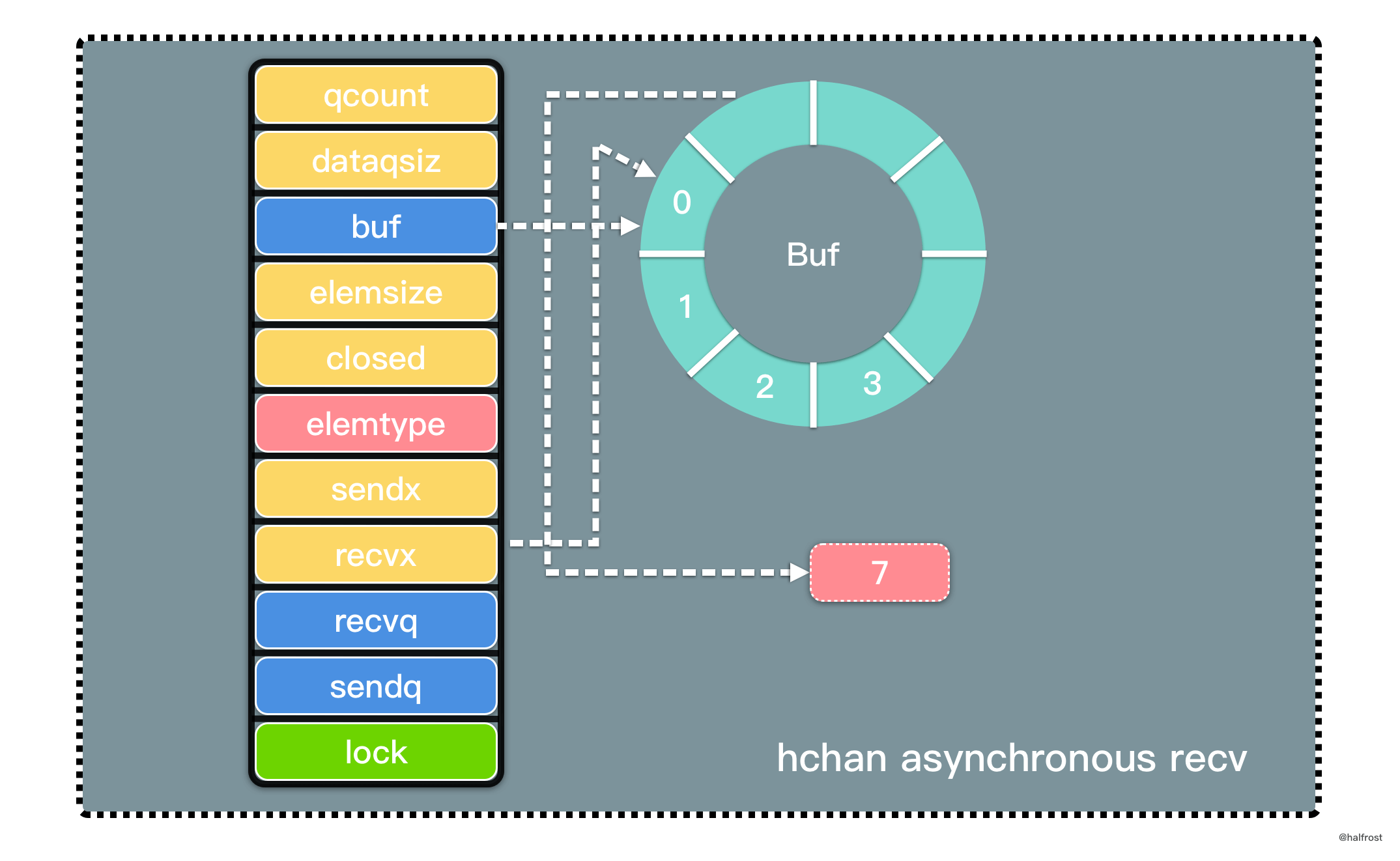
维护 recvx 下标,如果移动到了环形队列的队尾,下标需要回到队头。最后减少 qcount 计数器并释放持有 Channel 的锁。
4. 阻塞接收
如果 channel 发送队列上没有待发送的 goroutine,并且缓冲区也没有数据时,将会进入到最后一个阶段阻塞接收:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
......
- 调用 getg() 方法获取当前 goroutine 的指针,用于绑定给一个 sudog。
- 调用 acquireSudog() 方法获取一个 sudog,可能是新建的 sudog,也有可能是从缓存中获取的。设置好 sudog 要发送的数据和状态。比如发送的 Channel、是否在 select 中和待发送数据的内存地址等等。
- 调用 c.recvq.enqueue 方法将配置好的 sudog 加入待发送的等待队列。
- 设置原子信号。当栈要 shrink 收缩时,这个标记代表当前 goroutine 还 parking 停在某个 channel 中。在 g 状态变更与设置 activeStackChans 状态这两个时间点之间的时间窗口进行栈 shrink 收缩是不安全的,所以需要设置这个原子信号。
- 调用 gopark 方法挂起当前 goroutine,状态为 waitReasonChanReceive,阻塞等待 channel。
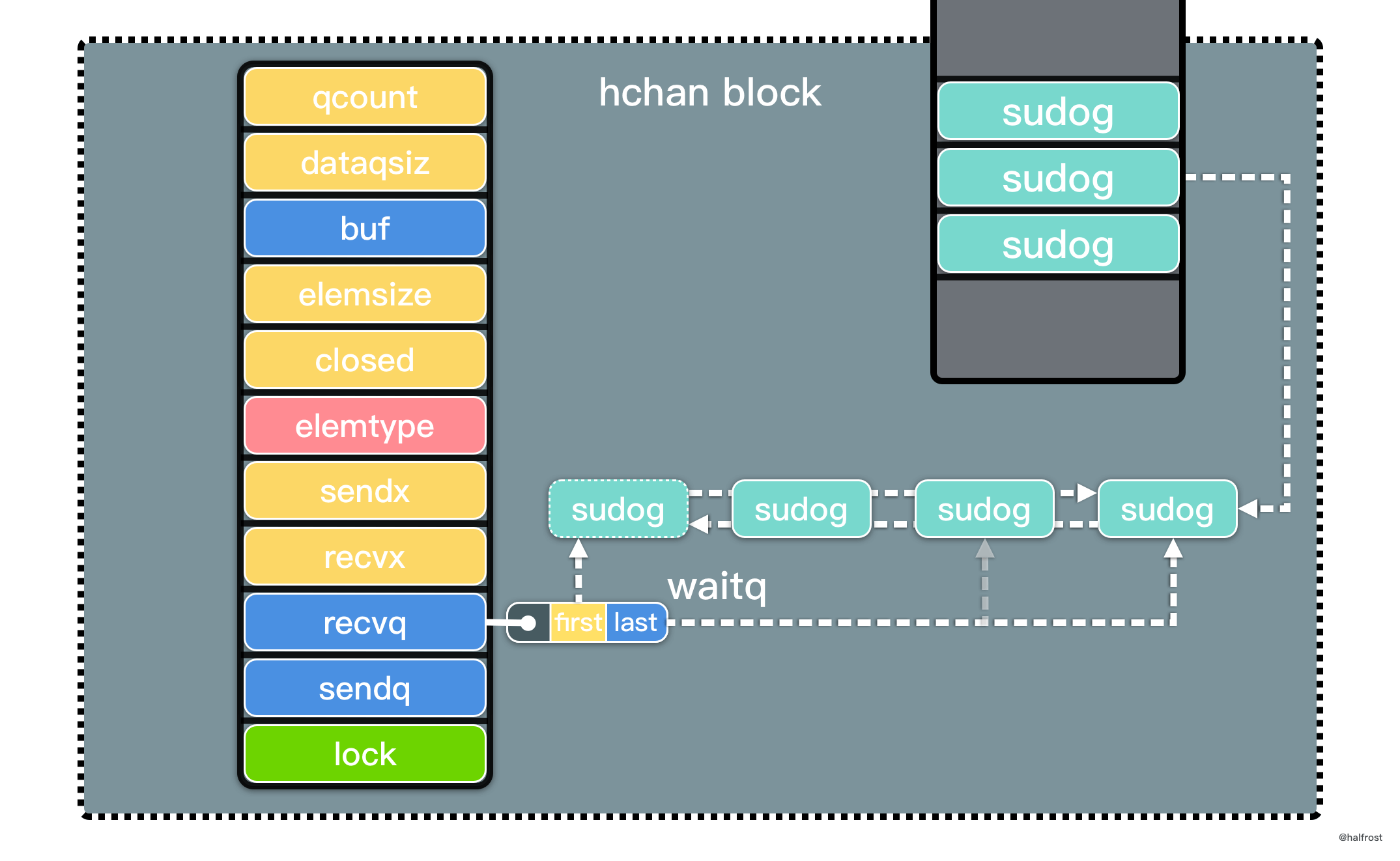
上面这段代码与 chansend() 中阻塞发送几乎完全一致,区别在于最后一步没有 KeepAlive(ep)。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
// 被唤醒
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
goroutine 被唤醒后会完成 channel 的阻塞数据接收。接收完最后进行基本的参数检查,解除 channel 的绑定并释放 sudog。
5. 小结
关于 channel 接收的源码实现已经分析完了,针对 channel 各个状态做一个小结。
| Channel status | Result | |
|---|---|---|
| Read | nil | 阻塞 |
| Read | 打开且非空 | 读取到值 |
| Read | 打开但为空 | 阻塞 |
| Read | 关闭 | <默认值>, false |
| Read | 只读 | Compile Error |
chanrecv 的返回值有几种情况:
tmp, ok := <-ch
| Channel status | Selected | Received |
|---|---|---|
| nil | false | false |
| 打开且非空 | true | true |
| 打开但为空 | false | false |
| 关闭且返回值是零值 | true | false |
received 值会传递给读取 channel 外部的 bool 值 ok,selected 值不会被外部使用。
channel 接收过程中包含 2 次有关 goroutine 调度过程:
- 当 channel 为 nil 时,执行 gopark() 挂起当前的 goroutine。
- 当发送队列中存在 sudog 可以直接接收数据时,执行 goready()将 g 插入 runnext 插槽中,状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable,等待下次调度便立即运行。
- 当 channel 缓冲区为空,且没有发送者时,这时 channel 阻塞,执行 gopark() 将 g 阻塞,让出 cpu 的使用权并等待调度器的调度。
六. 关闭 Channel
关于 channel 常见代码:
close(ch)
编译器会将其转换为 runtime.closechan() 方法。
1. 异常检查
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, funcPC(closechan))
racerelease(c.raceaddr())
}
c.closed = 1
......
}
关闭一个 channel 有 2 点需要注意,当 Channel 是一个 nil 空指针或者关闭一个已经关闭的 channel 时,Go 语言运行时都会直接 panic。上述 2 种情况都不存在时,标记 channel 状态为 close。
2. 释放所有 readers 和 writers
关闭 channel 的主要工作是释放所有的 readers 和 writers。
func closechan(c *hchan) {
......
var glist gList
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
......
}
上述代码是回收接收者的 sudog。将所有的接收者 readers 的 sudog 等待队列(recvq)加入到待清除队列 glist 中。注意这里是先回收接收者。就算从一个 close 的 channel 中读取值,不会发生 panic,顶多读到一个默认零值。
func closechan(c *hchan) {
......
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
......
}
再回收发送者 writers。回收步骤和回收接收者是完全一致的,将发送者的等待队列 sendq 中的 sudog 放入待清除队列 glist 中。注意这里可能会产生 panic。在第四章发送数据中分析过,往一个 close 的 channel 中发送数据,会产生 panic,这里不再赘述。
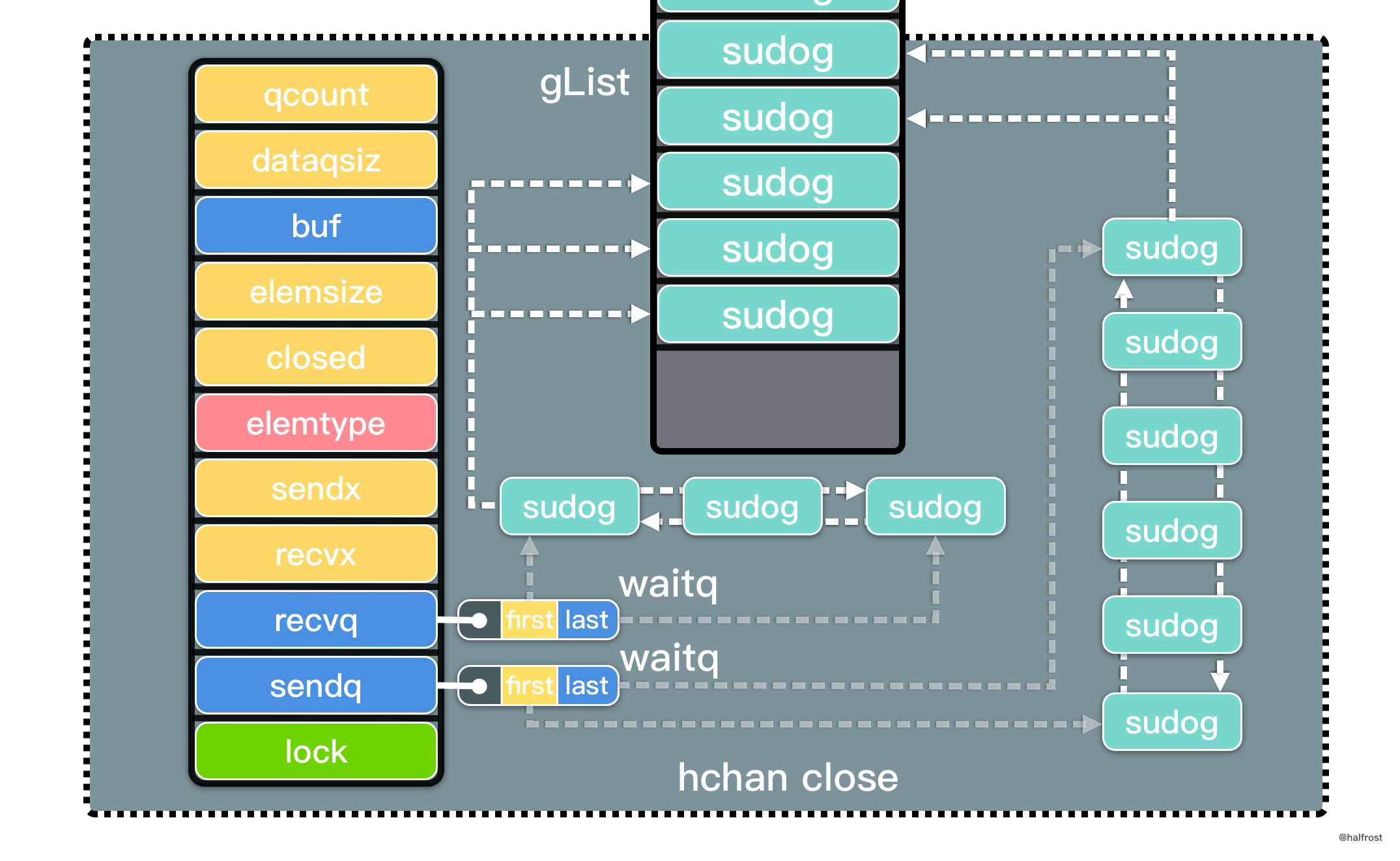
3. 协程调度
最后一步更改 goroutine 的状态。
func closechan(c *hchan) {
......
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
......
}
最后会为所有被阻塞的 goroutine 调用 goready 触发调度。将所有 glist 中的 goroutine 状态从 _Gwaiting 设置为 _Grunnable 状态,等待调度器的调度。
4. 优雅关闭
“Channel 有几种优雅的关闭方法?” 这种问题常常出现在面试题中,究其原因是因为 Channel 创建容易,但是关闭“不易”:
- 在不改变 Channel 自身状态的条件下,无法知道它是否已经关闭。“不易”之一,关闭时机未知。
- 如果一个 Channel 已经关闭,重复关闭 Channel 会导致 panic。“不易”之二,不能无脑关闭。
- 往一个 close 的 Channel 内写数据,也会导致 panic。“不易”之三,写数据之前也需要关注是否 close 的状态。
| Channel Status | Result | |
|---|---|---|
| close | nil | panic |
| close | 打开且非空 | 关闭 Channel;读取成功,直到 Channel 耗尽数据,然后读取产生值的默认值 |
| close | 打开但为空 | 关闭 Channel;读到生产者的默认值 |
| close | 关闭 | panic |
| close | 只读 | Compile Error |
那究竟什么时候关闭 Channel 呢?由上面三个“不易”,可以浓缩为 2 点:
- 不能简单的从消费者侧关闭 Channel。
- 如果有多个生产者,它们不能关闭 Channel。
解释一下这 2 个问题。第一个问题,消费者不知道 Channel 何时该关闭。如果关闭了已经关闭的 Channel 会导致 panic。而且分布式应用通常有多个消费者,每个消费者的行为一致,这么多消费者都尝试关闭 Channel 必然会导致 panic。第二个问题,如果有多个生产者往 Channel 内写入数据,这些生产者的行为逻辑也都一致,如果其中一个生产者关闭了 Channel,其他的生产者还在往里写,这个时候会 panic。所以为了防止 panic,必须解决上面这 2 个问题。
关闭 Channel 的方式就 2 种:
- Context
- done channel
Context 的方式在本篇文章不详细展开,详细的可以查看笔者 Context 的那篇文章。本节聊聊 done channel 的做法。假设有多个生产者,有多个消费者。在生产者和消费者之间增加一个额外的辅助控制 channel,用来传递关闭信号。
type session struct {
done chan struct{}
doneOnce sync.Once
data chan int
}
func (sess *session) Serve() {
go sess.loopRead()
sess.loopWrite()
}
func (sess *session) loopRead() {
defer func() {
if err := recover(); err != nil {
sess.doneOnce.Do(func() { close(sess.done) })
}
}()
var err error
for {
select {
case <-sess.done:
return
default:
}
if err == io.ErrUnexpectedEOF || err == io.EOF {
goto failed
}
}
failed:
sess.doneOnce.Do(func() { close(sess.done) })
}
func (sess *session) loopWrite() {
defer func() {
if err := recover(); err != nil {
sess.doneOnce.Do(func() { close(sess.done) })
}
}()
var err error
for {
select {
case <-sess.done:
return
case sess.data <- rand.Intn(100):
}
if err != nil {
goto done
}
}
done:
if err != nil {
log("sess: loop write failed: %v, %s", err, sess)
}
}
func (sess *session) ForceClose() {
sess.doneOnce.Do(func() { close(sess.done) })
}
消费者侧发送关闭 done channel,由于消费者有多个,如果每一个都关闭 done channel,会导致 panic。所以这里用 doneOnce.Do() 保证只会关闭 done channel 一次。这解决了第一个问题。生产者收到 done channel 的信号以后自动退出。多个生产者退出时间不同,但是最终肯定都会退出。当生产者全部退出以后,data channel 最终没有引用,会被 gc 回收。这也解决了第二个问题,生产者不会去关闭 data channel,防止出现 panic。
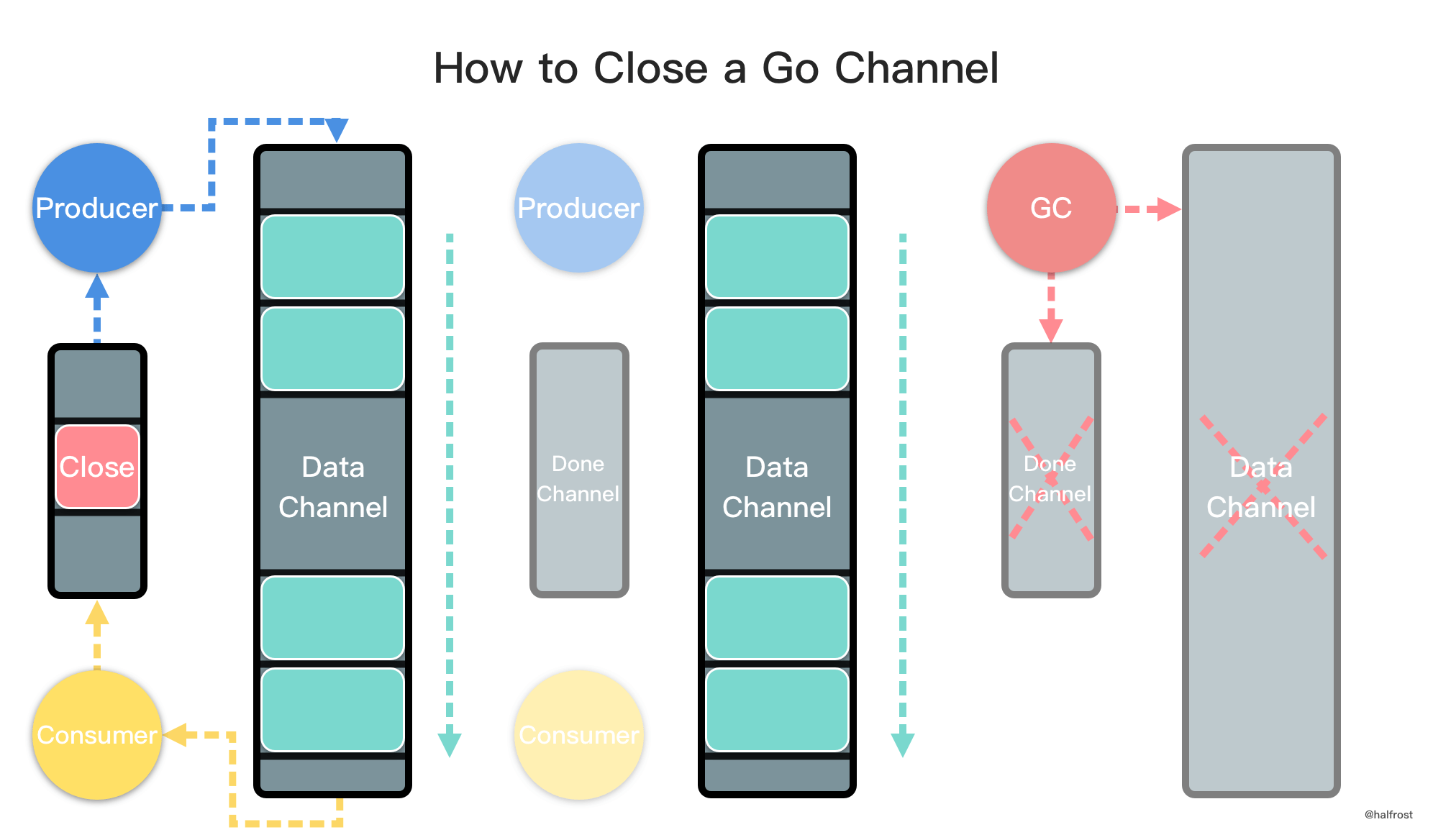
总结一下 done channel 的做法:消费者利用辅助的 done channel 发送信号,并先开始退出协程。生产者接收到 done channel 的信号,也开始退出协程。最终 data channel 无人持有,被 gc 回收关闭。
Reference:
ACM Communicating sequential processes
Stanford project about csp



