树状数组或二叉索引树(Binary Indexed Tree),又以其发明者命名为 Fenwick 树,最早由 Peter M. Fenwick 于 1994 年以 A New Data Structure for Cumulative Frequency Tables 为题发表在 SOFTWARE PRACTICE AND EXPERIENCE 上。其初衷是解决数据压缩里的累积频率(Cumulative Frequency)的计算问题,现多用于高效计算数列的前缀和,区间和。针对区间问题,除了常见的线段树解法,还可以考虑树状数组。它可以以 O(log n) 的时间得到任意前缀和 $ \sum_{i=1}^{j}A[i],1<=j<=N $,并同时支持在 O(log n)时间内支持动态单点值的修改(增加或者减少)。空间复杂度 O(n)。
利用数组实现前缀和,查询本来是 O(1),但是对于频繁更新的数组,每次重新计算前缀和,时间复杂度 O(n)。此时树状数组的优势便立即显现。
一. 一维树状数组概念
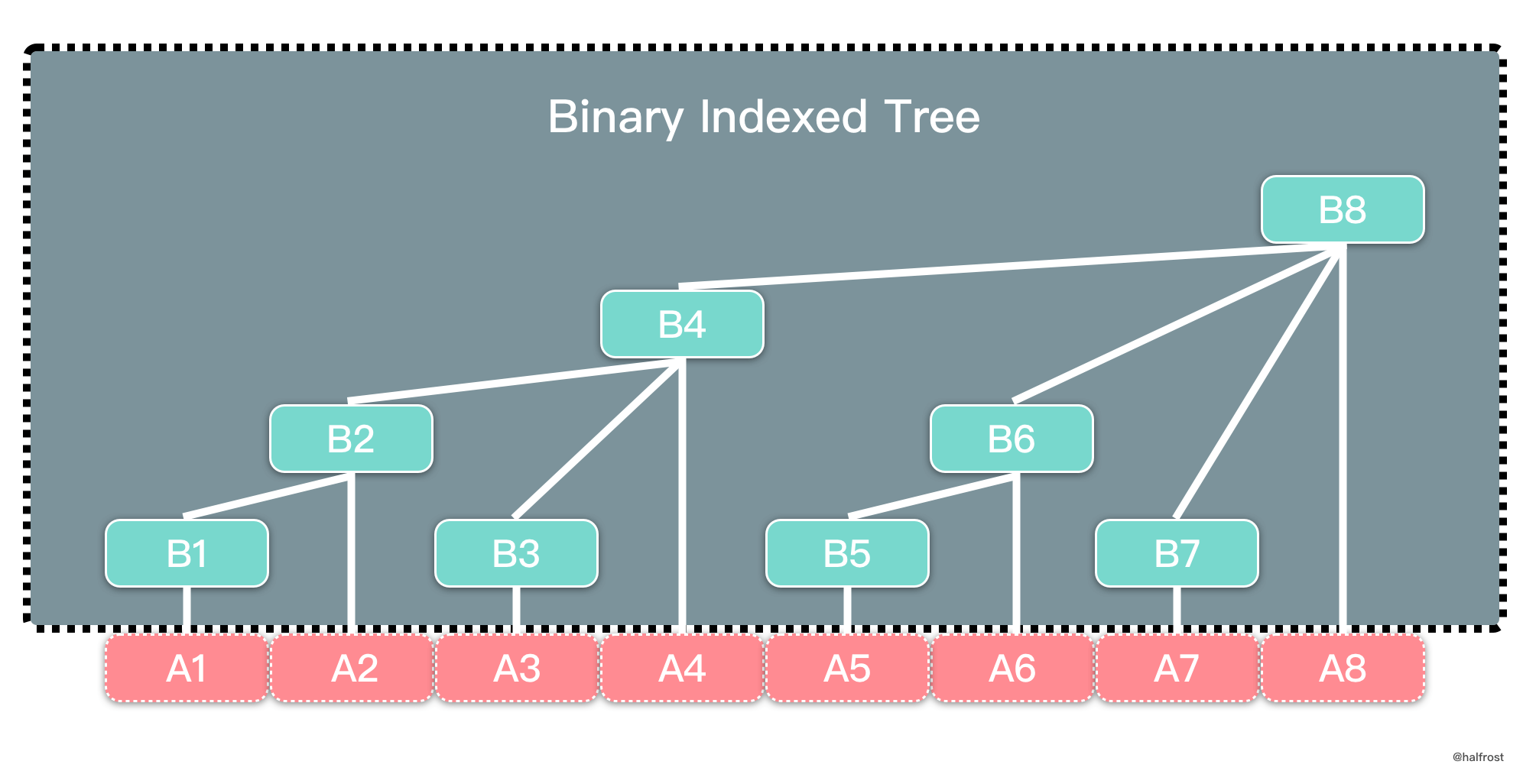
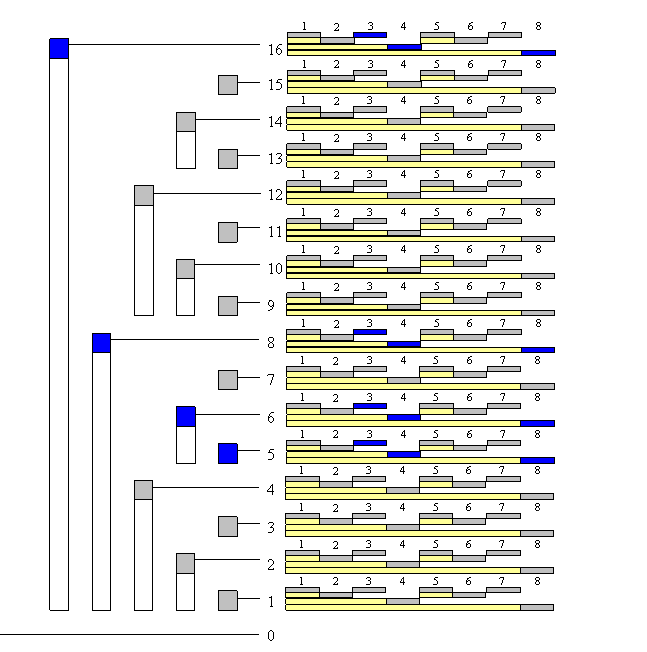
树状数组名字虽然又有树,又有数组,但是它实际上物理形式还是数组,不过每个节点的含义是树的关系,如上图。树状数组中父子节点下标关系是 $parent = son + 2^{k} $,其中 k 是子节点下标对应二进制末尾 0 的个数。
例如上图中 A 和 B 都是数组。A 数组正常存储数据,B 数组是树状数组。B4,B6,B7 是 B8 的子节点。4 的二进制是 100,4 + $2^{2} $ = 8,所以 8 是 4 的父节点。同理,7 的二进制 111,7 + $2^{0} $ = 8,8 也是 7 的父节点。
1. 节点意义
在树状数组中,所有的奇数下标的节点的含义是叶子节点,表示单点,它存的值是原数组相同下标存的值。例如上图中 B1,B3,B5,B7 分别存的值是 A1,A3,A5,A7。所有的偶数下标的节点均是父节点。父节点内存的是区间和。例如 B4 内存的是 B1 + B2 + B3 + A4 = A1 + A2 + A3 + A4。这个区间的左边界是该父节点最左边叶子节点对应的下标,右边界就是自己的下标。例如 B8 表示的区间左边界是 B1,右边界是 B8,所以它表示的区间和是 A1 + A2 + …… + A8。
由数学归纳法可以得出,左边界的下标一定是 $i - 2^{k} + 1 $,其中 i 为父节点的下标,k 为 i 的二进制中末尾 0 的个数。用数学方式表达偶数节点的区间和:
$$B_{i} = \sum_{j = i - 2^{k} + 1}^{i} A_{j}$$
初始化树状数组的代码如下:
// BinaryIndexedTree define
type BinaryIndexedTree struct {
tree []int
capacity int
}
// Init define
func (bit *BinaryIndexedTree) Init(nums []int) {
bit.tree, bit.capacity = make([]int, len(nums)+1), len(nums)+1
for i := 1; i <= len(nums); i++ {
bit.tree[i] += nums[i-1]
for j := i - 2; j >= i-lowbit(i); j-- {
bit.tree[i] += nums[j]
}
}
}
lowbit(i) 函数返回 i 转换成二进制以后,末尾最后一个 1 代表的数值,即 $2^{k} $,k 为 i 末尾 0 的个数。我们都知道,在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理。利用补码,可以 O(1) 算出 lowbit(i)。负数的补码等于正数的原码每位取反再 + 1,加一会使得负数的补码末尾的 0 和正数原码末尾的 0 一样。这两个数进行 & 运算以后,结果即为 lowbit(i):
func lowbit(x int) int {
return x & -x
}
如果还想不通的读者,可以看这个例子,34 的二进制是 $(0010 0010)_{2}$,它的补码是 $(1101 1110)_{2}$。
lowbit(34) 结果是 $2^{k} = 2^{1} = 2$
2. 插入操作
树状数组上的父子的下标满足 $parent = son + 2^{k} $ 关系,所以可以通过这个公式从叶子结点不断往上递归,直到访问到最大节点值为止,祖先结点最多为 logn 个。插入操作可以实现节点值的增加或者减少,代码实现如下:
// Add define
func (bit *BinaryIndexedTree) Add(index int, val int) {
for index <= bit.capacity {
bit.tree[index] += val
index += lowbit(index)
}
}
3. 查询操作
树状数组中查询 [1, i] 区间内的和。按照节点的含义,可以得出下面的关系:
$B_{i} $ 是树状数组存的值。Query 操作实际是一个递归的过程。lowbit(i) 表示 $2^{k} $,其中 k 是 i 的二进制表示中末尾 0 的个数。i - lowbit(i) 将 i 的二进制中末尾的 1 去掉,最多有 $log(i) $ 个 1,所以查询操作最坏的时间复杂度是 O(log n)。查询操作实现代码如下:
// Query define
func (bit *BinaryIndexedTree) Query(index int) int {
sum := 0
for index >= 1 {
sum += bit.tree[index]
index -= lowbit(index)
}
return sum
}
二. 不同场景下树状数组的功能
根据节点维护的数据含义不同,树状数组可以提供不同的功能来满足各种各样的区间场景。下面我们先以上例中讲述的区间和为例,进而引出 RMQ 的使用场景。
1. 单点增减 + 区间求和
这种场景是树状数组最经典的场景。单点增减分别调用 add(i,v) 和 add(i,-v)。区间求和,利用前缀和的思想,求 [m,n] 区间和,即 query(n) - query(m-1)。query(n) 代表 [1,n] 区间内的和,query(m-1) 代表 [1,m-1] 区间内的和,两者相减,即 [m,n] 区间内的和。
LeetCode 对应题目是 307. Range Sum Query - Mutable、327. Count of Range Sum
2. 区间增减 + 单点查询
这种情况需要做一下转化。定义差分数组 $C_{i} $ 代表 $C_{i} = A_{i} - A_{i-1} $。那么:
区间增减:在 [m,n] 区间内每一个数都增加 v,只影响 2 个单点的值:
可以观察看, $C_{m+1}, C_{m+2}, ......, C_{n} $ 值都不变,变化的是 $C_{m}, C_{n+1} $。所以在这种情况下,区间增加只需要执行 add(m,v) 和 add(n+1,-v) 即可。
单点查询这时就是求前缀和了, $A_{n} = \sum_{j=1}^{n}C_{j} $,即 query(n)。
3. 区间增减 + 区间求和
这种情况是上面一种情况的增强版。区间增减的做法和上面做法一致,构造差分数组。这里主要说明区间查询怎么做。先来看 [1,n] 区间和如何求:
其中 $D_{n} = (n - 1) * C_{n} $
所以求区间和,只需要再构造一个 $D_{n} $ 即可。
以此类推,推到更一般的情况:
至此区间查询问题得解。
4. 单点增减 + 区间最值
线段树最基础的运用是区间求和,但是将 sum 操作换成 max 操作以后,也可以求区间最值,并且时间复杂度完全没有变。那树状数组呢?也可以实现相同的功能么?答案是可以的,不过时间复杂度会下降一点。
线段树求区间和,把每个小区间的和计算好,然后依次 pushUp,往上更新。把 sum 换成 max 操作,含义完全相同:取出小区间的最大值,然后依次 pushUp 得到整个区间的最大值。
树状数组求区间和,是将单点增减的增量影响更新到固定区间 $[i-2^{k}+1, i] $。但是把 sum 换成 max 操作,含义就变了。此时单点的增量和区间 max 值并无直接联系。暴力的方式是将该点与区间内所有值比较大小,取出最大值,时间复杂度 O(n * log n)。仔细观察树状数组的结构,可以发现不必枚举所有区间。例如更新 $A_{i} $ 的值,那么受到影响的树状数组下标为 $i-2^{0}, i-2^{1}, i-2^{2}, i-2^{3}, ......, i-2^{k} $,其中 $2^{k} < lowbit(i) \leqslant 2^{k+1} $。需要更新至多 k 个下标,外层循环由 O(n) 降为了 O(log n)。区间内部每次都需要重新比较,需要 O(log n) 的复杂度,总的时间复杂度为 $(O(log n))^2 $。
func (bit *BinaryIndexedTree) Add(index int, val int) {
for index <= bit.capacity {
bit.tree[index] = val
for i := 1; i < lowbit(index); i = i << 1 {
bit.tree[index] = max(bit.tree[index], bit.tree[index-i])
}
index += lowbit(index)
}
}
上面解决了单点更新的问题,再来看区间最值。线段树划分区间是均分,对半分,而树状数组不是均分。在树状数组中 $B_{i} $ 表示的区间是 $[i-2^{k}+1, i] $,据此划分“不规则区间”。对于树状数组求 [m,n] 区间内最值,
- 如果 $ m < n - 2^{k} $,那么 $ query(m,n) = max(query(m,n-2^{k}), B_{n}) $
- 如果 $ m >= n - 2^{k} $,那么 $ query(m,n) = max(query(m,n-1), A_{n}) $
func (bit *BinaryIndexedTree) Query(m, n int) int {
res := 0
for n >= m {
res = max(nums[n], res)
n--
for ; n-lowbit(n) >= m; n -= lowbit(n) {
res = max(bit.tree[n], res)
}
}
return res
}
n 最多经过 $(O(log n))^2 $ 变化,最终 n < m。时间复杂度为 $(O(log n))^2 $。
针对这类问题放一道经典例题《HDU 1754 I Hate It》:
Problem Description
很多学校流行一种比较的习惯。老师们很喜欢询问,从某某到某某当中,分数最高的是多少。这让很多学生很反感。不管你喜不喜欢,现在需要你做的是,就是按照老师的要求,写一个程序,模拟老师的询问。当然,老师有时候需要更新某位同学的成绩。
Input
本题目包含多组测试,请处理到文件结束。
在每个测试的第一行,有两个正整数 N 和 M ( 0<N<=200000,0<M<5000 ),分别代表学生的数目和操作的数目。学生 ID 编号分别从 1 编到 N。第二行包含 N 个整数,代表这 N 个学生的初始成绩,其中第 i 个数代表 ID 为 i 的学生的成绩。接下来有 M 行。每一行有一个字符 C (只取'Q'或'U') ,和两个正整数 A,B。当 C 为 'Q' 的时候,表示这是一条询问操作,它询问 ID 从 A 到 B(包括 A,B)的学生当中,成绩最高的是多少。当 C 为 'U' 的时候,表示这是一条更新操作,要求把 ID 为 A 的学生的成绩更改为 B。
Output
对于每一次询问操作,在一行里面输出最高成绩。
Sample Input
5 6
1 2 3 4 5
Q 1 5
U 3 6
Q 3 4
Q 4 5
U 2 9
Q 1 5
Sample Output
5
6
5
9
读完题可以很快反应是单点增减 + 区间最大值的题。利用上面讲解的思想写出代码:
由于 OJ 不支持 Go,所以此处用 C 代码实现。这里还有一个 Hint,对于超大量的输入,scanf() 的性能明显优于 cin。
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
const int MAXN = 3e5;
int a[MAXN], h[MAXN];
int n, m;
int lowbit(int x)
{
return x & (-x);
}
void updata(int x)
{
int lx, i;
while (x <= n)
{
h[x] = a[x];
lx = lowbit(x);
for (i=1; i<lx; i<<=1)
h[x] = max(h[x], h[x-i]);
x += lowbit(x);
}
}
int query(int x, int y)
{
int ans = 0;
while (y >= x)
{
ans = max(a[y], ans);
y --;
for (; y-lowbit(y) >= x; y -= lowbit(y))
ans = max(h[y], ans);
}
return ans;
}
int main()
{
int i, j, x, y, ans;
char c;
while (scanf("%d%d",&n,&m)!=EOF)
{
for (i=1; i<=n; i++)
h[i] = 0;
for (i=1; i<=n; i++)
{
scanf("%d",&a[i]);
updata(i);
}
for (i=1; i<=m; i++)
{
scanf("%c",&c);
scanf("%c",&c);
if (c == 'Q')
{
scanf("%d%d",&x,&y);
ans = query(x, y);
printf("%d\n",ans);
}
else if (c == 'U')
{
scanf("%d%d",&x,&y);
a[x] = y;
updata(x);
}
}
}
return 0;
}
上述代码已 AC。感兴趣的读者可以自己做一做这道 ACM 的简单题。
5. 区间叠加 + 单点最值
看到这里可能有细心的读者疑惑,这一类题不就是第二类“区间增减 + 单点查询”类似么?可以考虑用第二类题的思路解决这一类题。不过麻烦点在于,区间叠加以后,每个单点的更新不是直接告诉增减变化,而是需要我们自己维护一个最值。例如在 [5,7] 区间当前值是 7,接下来区间 [1,9] 区间内增加了一个 2 的值。正确的做法是把 [1,4] 区间内增加 2,[8,9] 区间增加 2,[5,7] 区间维持不变,因为 7 > 2。这仅仅是 2 个区间叠加的情况,如果区间叠加的越多,需要拆分的区间也越多了。看到这里有些读者可能会考虑线段树的解法了。线段树确实是解决区间叠加问题的利器。笔者这里只讨论树状数组的解法。
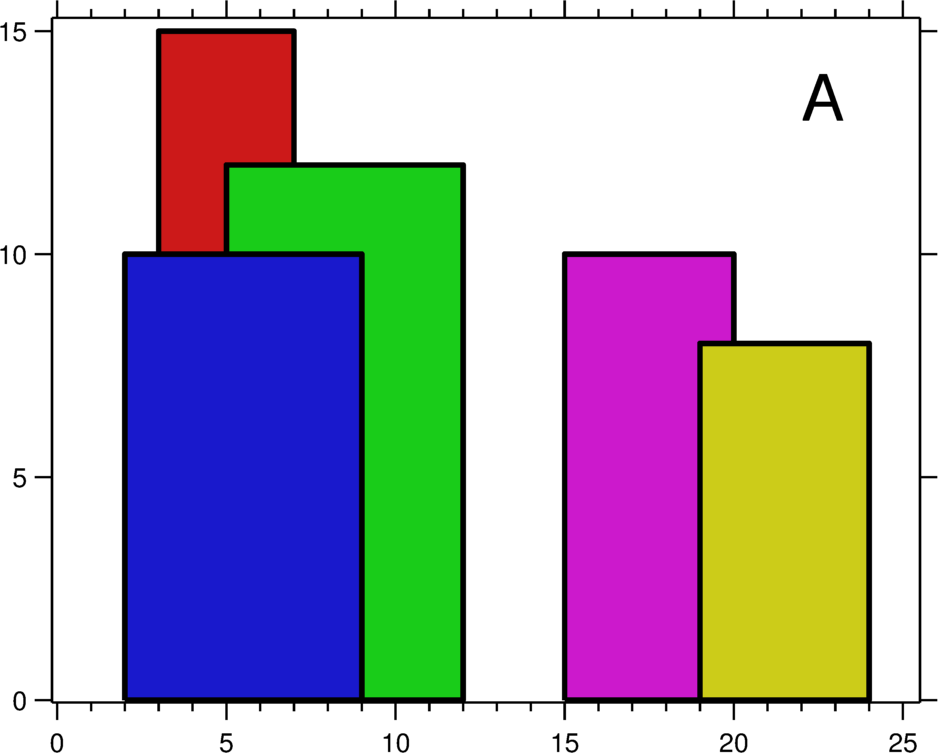
当前 LeetCode 有 1836 题,Binary Indexed Tree tag 下面只有 7 题,218. The Skyline Problem 这一题算是 7 道 BIT 里面最“难”的。这道天际线的题就属于区间叠加 + 单点最值的题。笔者以这道题为例,讲讲此类题的常用解法。
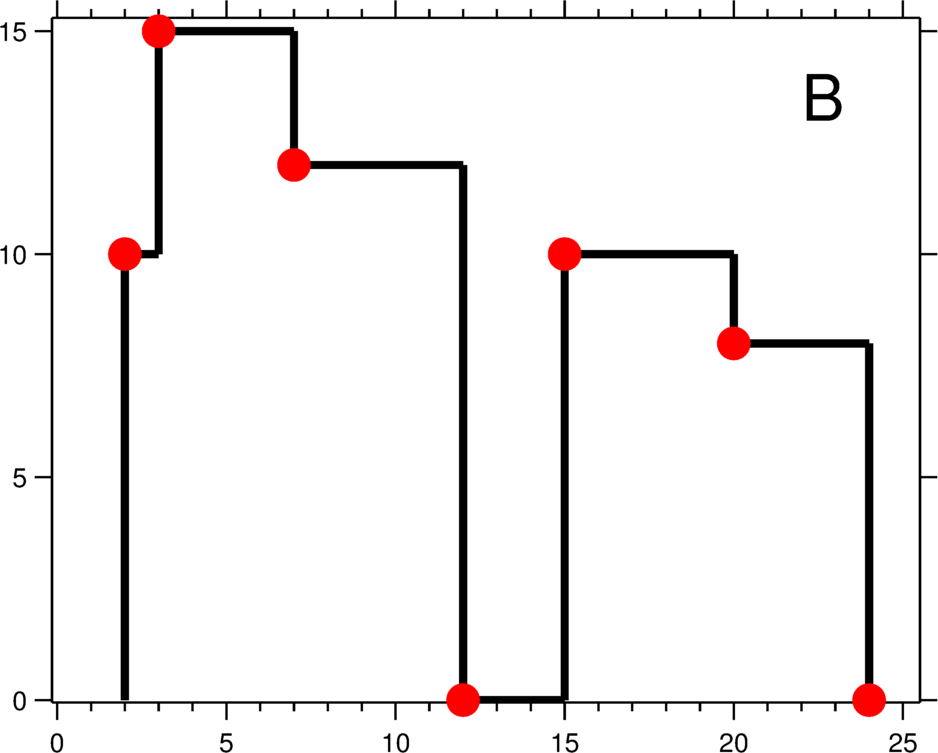
要求天际线,即找到楼与楼重叠区间外边缘的线,说白了是维护各个区间内的最值。这有 2 个需要解决的问题。
- 如何维护最值。当一个高楼的右边界消失,剩下的各个小楼间还需要选出最大值作为天际线。剩下重重叠叠的小楼很多,树状数组如何维护区间最值是解决此类题的关键。
- 如何维护天际线的转折点。有些楼与楼并非完全重叠,重叠一半的情况导致天际线出现转折点。如上图中标记的红色转折点。树状数组如何维护这些点呢?
先解决第一个问题(维护最值)。树状数组只有 2 个操作,一个是 Add() 一个是 Query()。从上面关于这 2 个操作的讲解中可以知道这 2 个操作都不能满足我们的需求。Add() 操作可以改成维护区间内 max() 的操作。但是 max() 容易获得却很难“去除”。如上图 [3,7] 这个区间内的最大值是 15。根据树状数组的定义,[3,12] 这个区间内最值还是 15。观察上图可以看到 [5,12] 区间内最值其实是 12。树状数组如何维护这种最值呢?最大值既然难以“去除”,那么需要考虑如何让最大值“来的晚一点”。解决办法是将 Query() 操作含义从前缀含义改成后缀含义。Query(i) 查询区间是 [1,i],现在查询区间变成 $[i,+\infty) $。例如:[i,j] 区间内最值是 $max_{i...j} $,Query(j+1) 的结果不会包含 $max_{i...j} $,因为它查询的区间是 $[j+1,+\infty) $。这样更改以后,可以有效避免前驱高楼对后面楼的累积 max() 最值的影响。
具体做法,将 x 轴上的各个区间排序,按照 x 值大小从小到大排序。从左往右依次遍历各个区间。Add() 操作含义是加入每个区间右边界代表后缀区间的最值。这样不需要考虑“移除”最值的问题了。细心的读者可能又有疑问了:能否从右往左遍历区间,Query() 的含义继续延续前缀区间?这样做是可行的,解决第一个问题(维护最值)是可以的。但是这种处理办法解决第二个问题(维护转折点)会遇到麻烦。
再解决第二个问题(维护转折点)。如果用前缀含义的 Query(),在单点 i 上除了考虑以这个点为结束点的区间,还需要考虑以这个单点 i 为起点的区间。如果是后缀含义的 Query() 就没有这个问题了, $[i+1,+\infty) $ 这个区间内不用考虑以单点 i 为结束点的区间。此题用树状数组代码实现如下:
const LEFTSIDE = 1
const RIGHTSIDE = 2
type Point struct {
xAxis int
side int
index int
}
func getSkyline3(buildings [][]int) [][]int {
res := [][]int{}
if len(buildings) == 0 {
return res
}
allPoints, bit := make([]Point, 0), BinaryIndexedTree{}
// [x-axis (value), [1 (left) | 2 (right)], index (building number)]
for i, b := range buildings {
allPoints = append(allPoints, Point{xAxis: b[0], side: LEFTSIDE, index: i})
allPoints = append(allPoints, Point{xAxis: b[1], side: RIGHTSIDE, index: i})
}
sort.Slice(allPoints, func(i, j int) bool {
if allPoints[i].xAxis == allPoints[j].xAxis {
return allPoints[i].side < allPoints[j].side
}
return allPoints[i].xAxis < allPoints[j].xAxis
})
bit.Init(len(allPoints))
kth := make(map[Point]int)
for i := 0; i < len(allPoints); i++ {
kth[allPoints[i]] = i
}
for i := 0; i < len(allPoints); i++ {
pt := allPoints[i]
if pt.side == LEFTSIDE {
bit.Add(kth[Point{xAxis: buildings[pt.index][1], side: RIGHTSIDE, index: pt.index}], buildings[pt.index][2])
}
currHeight := bit.Query(kth[pt] + 1)
if len(res) == 0 || res[len(res)-1][1] != currHeight {
if len(res) > 0 && res[len(res)-1][0] == pt.xAxis {
res[len(res)-1][1] = currHeight
} else {
res = append(res, []int{pt.xAxis, currHeight})
}
}
}
return res
}
type BinaryIndexedTree struct {
tree []int
capacity int
}
// Init define
func (bit *BinaryIndexedTree) Init(capacity int) {
bit.tree, bit.capacity = make([]int, capacity+1), capacity
}
// Add define
func (bit *BinaryIndexedTree) Add(index int, val int) {
for ; index > 0; index -= index & -index {
bit.tree[index] = max(bit.tree[index], val)
}
}
// Query define
func (bit *BinaryIndexedTree) Query(index int) int {
sum := 0
for ; index <= bit.capacity; index += index & -index {
sum = max(sum, bit.tree[index])
}
return sum
}
此题还可以用线段树和扫描线解答。扫描线和树状数组解答此题,非常快。线段树稍微慢一些。
三. 常见应用
这一章节来谈谈树状数组的常见应用。
1. 求逆序对
给定 $ n $ 个数 $ A[n] \in [1,n] $ 的排列 P,求满足 $i < j $ 且 $ A[i] > A[j] $ 的数对 $ (i,j) $ 的个数。
这个问题就是经典的逆序数问题,如果采用朴素算法,就是枚举 i 和 j,并且判断 A[i] 和 A[j] 的值进行数值统计,如果 A[i] > A[j] 则计数器加一,统计完后计数器的值就是答案。时间复杂度为 $ O(n^{2}) $,这个时间复杂度太高,是否存在 $ O(log n) $ 的解法呢?
如果题目换成 $ A[n] \in [1,10^{10}] $,解题思路不变,只不过一开始再多加一步,离散化的操作。
假设第一步需要离散化。先把数列中的数按大小顺序转化成 1 到 n 的整数,将重复的数据编相同的号,将空缺的数据编上连续的号。使得原数列映射成为一个 1,2,...,n 的数组 B。注意,数组 B 中存的元素也是乱序的,是根据原数组映射而来的。例如原数组是 int[9,8,5,4,6,2,3,8,7,0],数组中 8 是重复的,且少了数字 1,将这个数组映射到 [1,9] 区间内,调整后的数组 B 为 int[9,8,5,4,6,2,3,8,7,1]。
再创建一个树状数组,用来记录这样一个数组 C(下标从1算起)的前缀和:若 [1, N] 这个排列中的数 i 当前已经出现,则 C[i] 的值为 1 ,否则为 0。初始时数组 C 的值均为 0。从数组 B 第一个元素开始遍历,对树状数组执行修改数组 C 的第 B[j] 个数值加 1 的操作。再在树状数组中查询有多少个数小于等于当前的数 B[j](即用树状数组查询数组 C 中的 [1,B[j]] 区间前缀和),当前插入总数 i 减去小于等于 B[j] 元素总数,差值即为大于 B[j] 元素的个数,并加入计数器。
func reversePairs(nums []int) int {
if len(nums) <= 1 {
return 0
}
arr, newPermutation, bit, res := make([]Element, len(nums)), make([]int, len(nums)), template.BinaryIndexedTree{}, 0
for i := 0; i < len(nums); i++ {
arr[i].data = nums[i]
arr[i].pos = i
}
sort.Slice(arr, func(i, j int) bool {
if arr[i].data == arr[j].data {
if arr[i].pos < arr[j].pos {
return true
} else {
return false
}
}
return arr[i].data < arr[j].data
})
id := 1
newPermutation[arr[0].pos] = 1
for i := 1; i < len(arr); i++ {
if arr[i].data == arr[i-1].data {
newPermutation[arr[i].pos] = id
} else {
id++
newPermutation[arr[i].pos] = id
}
}
bit.Init(id)
for i := 0; i < len(newPermutation); i++ {
bit.Add(newPermutation[i], 1)
res += (i + 1) - bit.Query(newPermutation[i])
}
return res
}
上述代码中的 newPermutation 就是映射调整后的数组 B。遍历数组 B,按顺序把元素插入到树状数组中。例如数组 B 是 int[9,8,5,4,6,2,3,8,7,1],现在往树状数组中插入 6,代表 6 这个元素出现了。query() 查询 [1,6] 区间内是否有元素出现,区间前缀和代表区间内元素出现次数和。如果有 k 个元素出现,且当前插入了 5 个元素,那么 5-k 的差值即是逆序的元素个数,这些元素一定比 6 大。这种方法是正序构造树状数组。
还有一种方法是倒序构造树状数组。例如下面代码:
for i := len(s) - 1; i > 0; i-- {
bit.Add(newPermutation[i], 1)
res += bit.Query(newPermutation[i] - 1)
}
由于是倒序插入,每次 Query 之前的元素下标一定比当前 i 要大。下标比 i 大,元素值比 A[i] 小,这样的元素和 i 可以构成逆序对。Query 查找 [1, B[j]] 区间内元素总个数,即为逆序对的总数。
注意,计算逆序对的时候不要算重复了。比如,计算当前 j 下标前面比 B[j] 值大的数,又算上 j 下标后面比 B[j] 值小的数。这样计算出现了很多重复。因为 j 下标前面的下标 k,也会寻找 k 下标后面比 B[k] 值小的数,重复计算了。那么统一找比自己下标小,但是值大的元素,那么统一找比自己下标大,但是值小的元素。切勿交叉计算。
LeetCode 对应题目是 315. Count of Smaller Numbers After Self、493. Reverse Pairs、1649. Create Sorted Array through Instructions
2. 求区间逆序对
给定 $ n $ 个数的序列 $ A[n] \in [1,2^{31}-1] $,然后给出 $ n \in [1,10^{5}] $ 次询问 $ [L,R] $,每次询问区间 $ [L,R] $ 中满足 $ L \leqslant i < j \leqslant R $ 且 $ A[i] > A[j] $ 的下标 $ (i,j) $ 的对数。
这个问题比上一题多了一个区间限制。这个区间的限制影响对逆序对的选择。例如:[1,3,5,2,1,1,8,9,8,6,5,3,7,7,2],求在 [3,7] 区间内的逆序数。元素 2 在区间内,比元素 2 大的元素只有 2 个。元素 3 和 5 在区间外,所以 3 和 5 不能参与逆序数的统计。比元素 2 小的元素也只有 2 个,黄色标识的 3 个 1 都比 2 小,但是第一个 1 不能算在内,因为它在区间外。
先将所有查询区间按照右端点单调不减排序,如下图所示。
这里也可以按照查询区间左端点单调不增排序。如果这样排序,下面构建树状数组需要倒序插入。并且查找的是下标靠后但是元素值小的逆序对。两者方法都可以实现,这里讲解选其中一种。
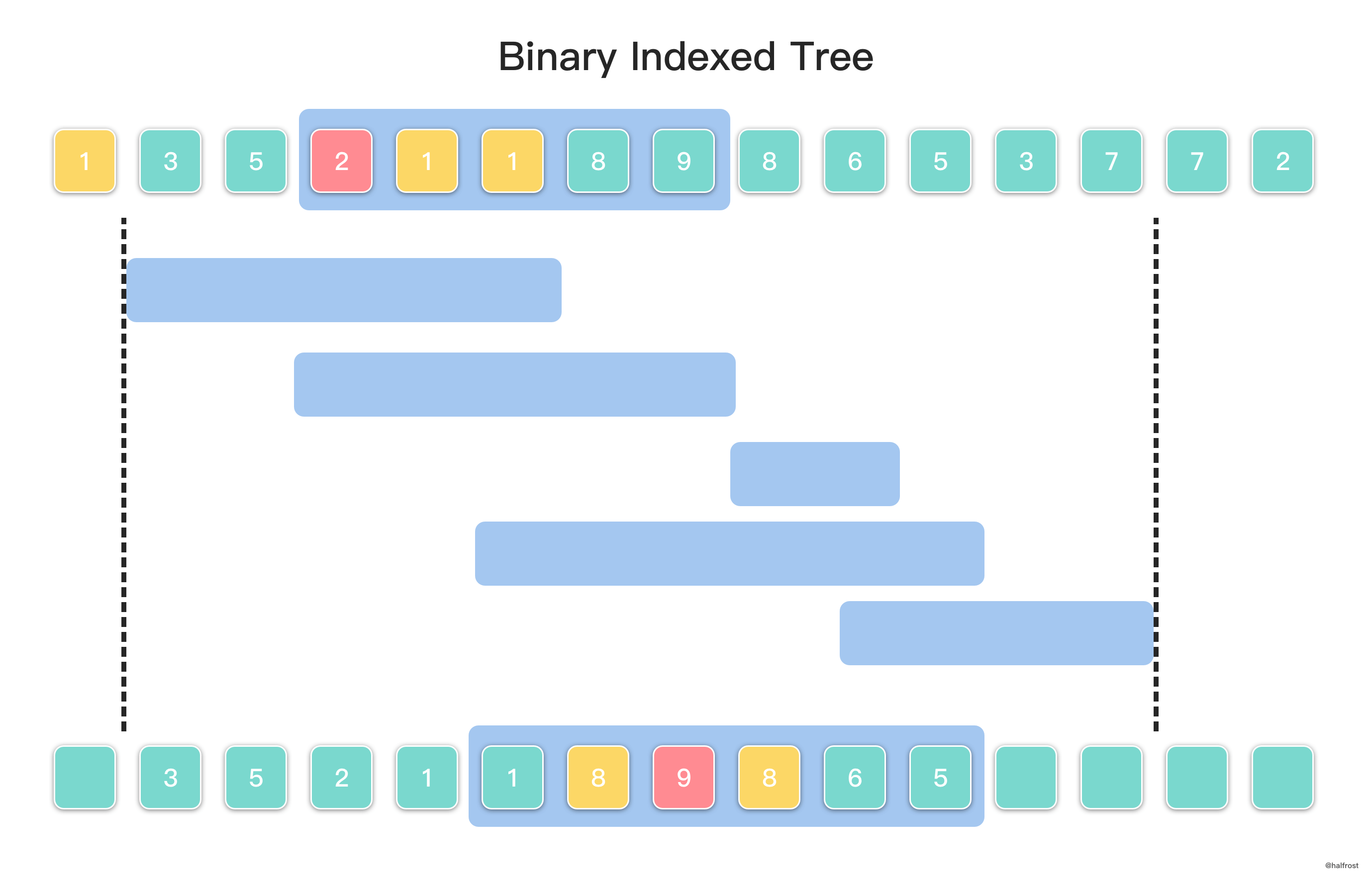
总的区间覆盖的范围决定了树状数组待插入数字的范围。如上图,总的区间位于 [1,12],那么下标为 0,13,14 的元素不需要理会,它们不会被用到,所以也不用插入到树状数组中。
求区间逆序对的过程中还需要利用到一个辅助数组 C[k],这个数组的含义是下标为 k 的元素,在插入到树状数组之前,比 A[k] 值小的元素有几个。举个例子,例如下标为 7 的元素值为 9 。C[7] = 6,因为当前比 9 小的元素是 3,5,2,1,1,8。这个辅助数组 C[k] 的意义是找到下标比它小,且元素值也比它小的元素个数。
由于这里选择区间右区间排序,所以构造树状数组插入是顺序插入。这样区间从左有右的查询可以依次得到结果。如上图中最下一行的图示,假设当前查询到了第 4 个区间。第 4 个区间包含元素值 1,8,9,8,6,5 。当前从左往右插入构造树状数组,已经插入了下标为 [1,10] 区间的元素值,即如图显示插入的数值。现在遍历查询区间内所有元素,Query(A[i] - 1) - C[i] 即为下标 i 在当前查询区间内的逆序对总个数。例如元素 9:
插入 A[i] 元素构造树状数组在先,Query() 查询针对当前全局情况,即查询下标 [1,10] 区间内所有比元素 9 小的元素总数,不难发现所有元素都比元素 9 小,那么 Query(A[i] - 1) 得到的结果是 9。C[7] 是元素 9 插入到树状数组之前比元素 9 小的元素总数,是 6。两者相减,最终结果是 9 - 6 = 3。看上图也很容易看出来结果是正确的,在区间内比 9 下标值大且元素值比 9 小的只有 3 个,分别对应的下标是 8,9,10,对应的元素值是 8,6,5。
总结:
- 离散化数组 A[i]
- 对所有区间按照右端点单调不减排序
- 按照区间排序后的结果,从左往右依次遍历每个区间。依照从左往右的区间覆盖元素范围,从左往右将 A[i] 插入至树状数组中,每个元素插入之前计算辅助数组 C[i]。
- 依次遍历每个区间内的所有元素,对每个元素计算 Query(A[i] - 1) - C[i],累加逆序对的结果即是这个区间所有逆序对的总数。
3. 求树上逆序对
给定 $ n \in [0,10^{5}] $ 个结点的树,求每个结点的子树中结点编号比它小的数的个数。
树上逆序对的问题可以通过树的先序遍历可以将树转换成数组,令树上的某个结点 i,先序遍历到的顺序为 pre[i],i 的子结点个数为 a[i],则转换成数组后 i 管理的区间为 [pre[i], pre[i] + a[i] - 1],然后就可以转换成区间逆序对问题进行求解了。
四. 二维树状数组
树状数组可以扩展到二维、三维或者更高维。二维树状数组可以解决离散平面上的统计问题。
// BinaryIndexedTree2D define
type BinaryIndexedTree2D struct {
tree [][]int
row int
col int
}
// Add define
func (bit2 *BinaryIndexedTree2D) Add(i, j int, val int) {
for i <= bit2.row {
k := j
for k <= bit2.col {
bit2.tree[i][k] += val
k += lowbit(k)
}
i += lowbit(i)
}
}
// Query define
func (bit2 *BinaryIndexedTree2D) Query(i, j int) int {
sum := 0
for i >= 1 {
k := j
for k >= 1 {
sum += bit2.tree[i][k]
k -= lowbit(k)
}
i -= lowbit(i)
}
return sum
}
如果把一维树状数组维护的是数轴上的统计问题,
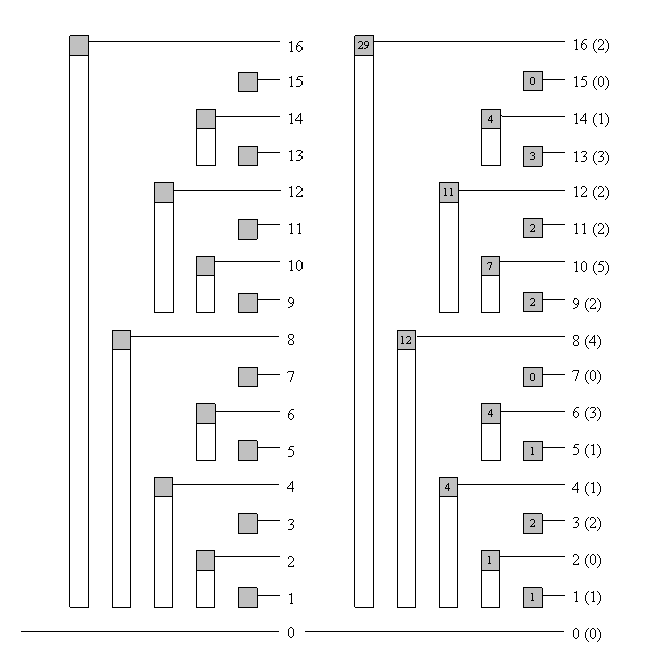
那么二维数组维护的是二维坐标系下的统计问题。X 和 Y 分别都满足一维树状数组的性质。